






关注公众号,发现CV技术之美

论文名称: Universal Domain Adaptive Object Detection via Dual Probabilistic Alignment
目标检测作为计算机视觉领域的核心任务,在闭集场景中已经取得了显著的进展。然而,现有的方法通常假设类别集合是固定的,并依赖于大量的标注数据,这导致它们在处理跨域数据时,特别是在源域与目标域之间存在域偏移的情况下,泛化性能受限。例如,针对晴天数据训练的目标检测模型往往难以有效适应雾天或其他场景条件下的场景变化。
为了应对这一挑战,域自适应目标检测(Domain Adaptive Object Detection, DAOD)方法被提出。DAOD的主要目标是通过将源域的有标签数据迁移到目标域的无标签数据上,从而缓解源域与目标域之间分布不一致所带来的性能下降问题。
在源域和目标域类别集合相同的前提下,DAOD能够有效实现跨域迁移,并减少对大规模标注数据的依赖,从而降低了高昂的数据标注成本。然而,在开放世界场景中,源域与目标域之间可能会存在私有类别(即目标域包含源域未见过的类别)。因此,传统的DAOD方法受限于闭集假设,无法处理私有类别的域对齐问题,从而限制了其在开放世界场景中的应用。
为了解决这一问题,通用域自适应目标检测(Universal Domain Adaptive Object Detection, UniDAOD)方法被提出。UniDAOD通过放宽类别集合的闭集假设,能够在没有类别先验信息的情况下实现源域与目标域的跨域对齐,从而适应包括闭集、部分集和开放集等多种场景。此方法显著提升了目标检测模型在开放世界中的鲁棒性和泛化能力,拓展了目标检测技术在更复杂和动态场景中的应用范围。
现有UniDAOD模型的不足
现有的通用域自适应目标检测(UniDAOD)方法的核心思想借鉴了域自适应目标检测(DAOD)和通用域自适应(UniDA)方法的范式。具体而言,UniDAOD方法结合了DAOD系列的基础对齐方法,包括实例对齐与全局对齐,并借鉴了UniDA系列方法来挖掘源域和目标域中的公共类别样本。在UniDA中,通过构建概率阈值机制,域判别器的概率层面能够筛选出公共类别的样本,从而实现源域与目标域的对齐。
因此,现有的UniDAOD方法的基本流程通常包括以下步骤:
首先,区分源域和目标域中的类别,并将其划分为公共类别和私有类别;
接着,去除私有类别,仅保留公共类别;
然后,针对这些公共类别的特征进行对齐,从而实现从开放集场景到闭集场景的转变。
在域判别器的设计上,UniDAOD通过设定概率阈值来进一步区分源域和目标域中的公共类别与私有类别,从而达到更精确的对齐效果。
尽管UniDAOD方法在许多场景下表现良好,尤其是在处理从闭集场景到开放集场景的转变时,然而,直接使用DAOD和UniDA的方法结论,使得UniDAOD方法在开放世界场景下仍然存在次优化问题。具体来说,以下两个问题值得进一步探索:
全局特征与实例特征是否都对齐公共类别特征?
概率阈值是否在复杂的检测任务中对不同特征都有效?
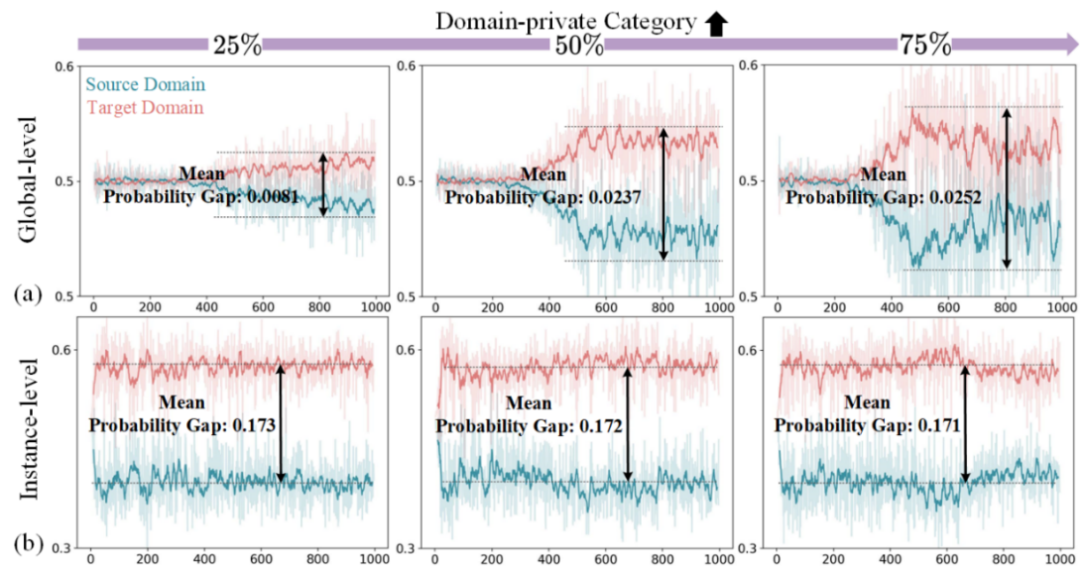
为了探索上述问题,我们在图2中对域判别器的概率进行了可视化分析。图2为源域(Source Domain)和目标域(Target Domain)域鉴别器中的概率差异分析,分为全局级别(Global-level)和实例级别(Instance-level),在不同的域私有类别占比(25%、50%、75%)下进行评估。
在全局级别,图2(a)中展示了随着域私有类别比例的增加,源域与目标域之间的整体预测概率差异逐步扩大,表现为两条概率曲线之间的间距逐渐增大,反映出域私有类别比例的提高显著增强了域间的概率差异。
在实例级别图2(b)中,呈现了实例目标特征的概率在源域和目标域中的概率差异。与全局级别相比,实例级别的概率差异更加显著,即目标实例特征的概率差异在源域和目标域之间存在较大偏差。
此外,随着域私有类别比例的增加,实例级别的概率差异并未发生显著变化,而是保持相对稳定。全局级别的概率差异随着私有类别的增加而增加。
针对第一个问题,现有的域自适应目标检测(DAOD)方法假设域共享类别集是已知的,并且在进行域对齐时,假定全局特征和实例特征对齐的贡献是相同的。也就是说,全局特征和实例特征都应该对齐共享类别特征。然而,这与图2中的结论相悖:全局特征倾向于对齐域私有类别,而实例特征则更倾向于对齐域共享类别。
针对第二个问题,现有的UniDA方法通过使用阈值对样本进行筛选,但这依赖于稳定的概率分布。在图2(a)中,概率差异波动较大,导致阈值难以有效筛选样本;而在图2(b)中,概率变化相对稳定,因此阈值筛选样本效果较好。不同的特征在概率分布上是异构的。因此,现有基于阈值的范式难以在目标检测中有效适应不同特征下的概率分布。
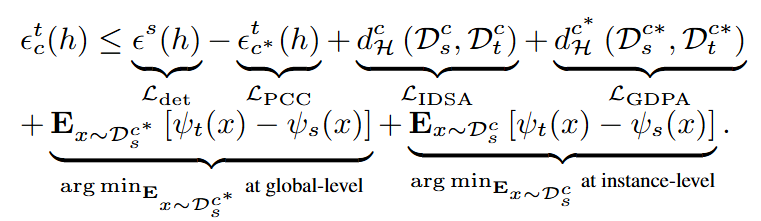
为了解决上述两个问题,我们通过公式推导(见图3)证明了在最小化标签函数期望的条件下,全局级别的特征倾向于对齐域私有类别,而实例级别的特征则倾向于对齐域共享类别。这一理论推导的结果与图2中的实验现象高度一致,进一步验证了我们模型假设的合理性。基于这一发现,接下来我们将引入双概率建模方法,以实现异构域分布下的样本采样和权重估计。
在全局特征层面,区域提议网络(RPN)构建了前景类别 和背景类别 的类别空间。 表示标签函数。因此,域共享和域私有类别标签函数的概率为:。
在实例特征层面,ROI头部(ROI-head)构建了前景域共享类别(c )、域私有类别( )和背景类别()的类别空间,其中类别数量 假设条件是大于 1 。因此,域共享和域私有类别标签函数的概率可以表示为:
。
我们通过分析 P 以估计当前特征标签函数的概率。全局特征层面最小化;
当满足条件 邋 (global-feature) (instance-feature) 时,域私有标签函数可以在全局特征层面最小化;
当满足条件 邋 (global-feature) (instance-feature) 时,域共享标签函数可以在实例特征层面最小化。
双概率建模
通过图3中的理论分析,我们已经明确了全局特征与实例特征在对齐过程中的不同作用,并揭示了域私有类别与域共享类别之间的关系。在此基础上,双概率建模方法能够有效解决这些问题。
具体而言,我们通过对全局特征和实例特征进行正态分布建模,从而实现样本的采样与加权,进而更好地进行对齐。由于对抗训练中的数据概率分布近似正态分布,因此我们采用正态分布对全局特征和实例特征进行建模,以进行样本的采样与加权。
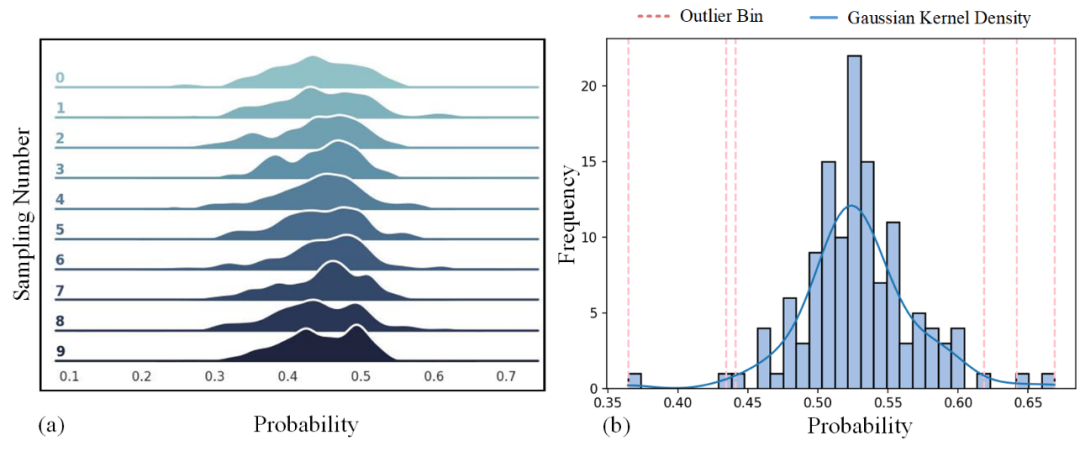
在图4(a)中,左图展示了多次对实例特征进行采样后的概率分布,结果表明这些特征的概率分布基本符合正态分布。因此,我们提出的一个直观思路是通过正态分布建模概率,并剔除那些不符合正态分布的样本。图4(b)展示了我们的方法:首先计算样本梯度的模长,并将其划分为不同的bins,进而建模高斯分布。
可以看到,位于分布边缘之外的bins对应的样本是需要剔除的样本。所有这些bins的总和代表了特征空间中距离特征质心的采样半径,并且在对抗训练过程中,基于源域或目标域数据的高斯分布,该半径会动态调整。
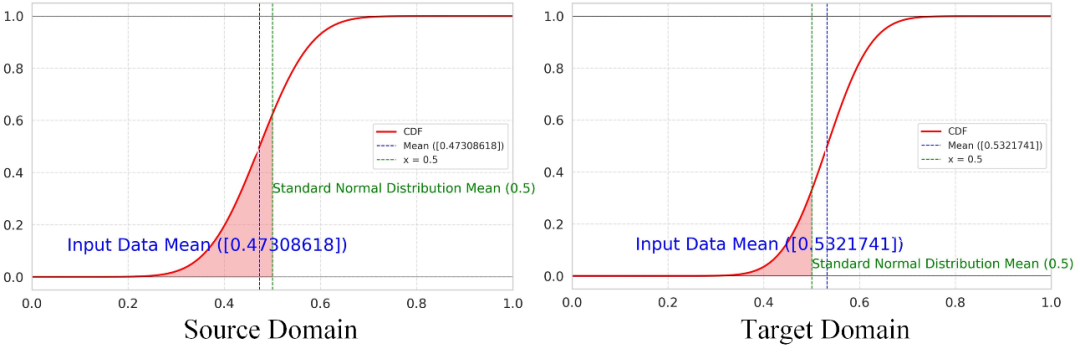
在全局特征层面,我们通过使用累计分布函数(Cumulative Distribution Function, CDF)来估计私有类别的分布,从而避免因过度域对齐而导致的负迁移问题。根据图2的结论,私有类别的增强概率通常偏离0.5,因此在CDF上,私有类别的数量与其对应的分布值之间存在一定的关系。
为了避免直接将CDF作为权重进行对齐所可能引发的过度域对齐问题,我们计算源域和目标域的CDF,并采用正则化方法对其进行调整。具体的CDF计算公式如下:
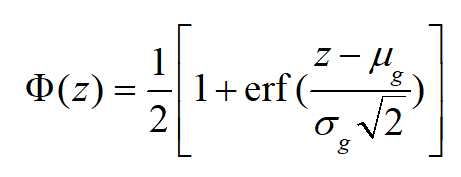
为了避免直接将CDF作为权重进行对齐所导致的过度域对齐,我们对源域和目标域的CDF值进行正则化调整。具体来说,我们设计了以下正则化形式作为域对齐的权重:
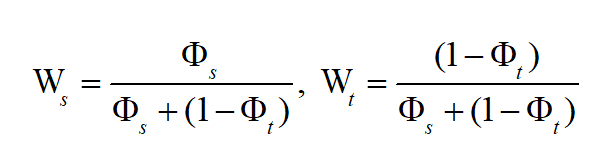
DPA模型框架
DPA的模型设计思路主要来源于我们得到的公式(见图3)。在图6中,DPA 包含三个定制模块:全局级别域私有对齐(GDPA)、实例级别域共享对齐(IDSA)和私有类别约束(PCC)。
为了最小化目标域的域共享类别的上限,DPA 包括 GDPA、IDSA 和 PCC,以优化方程
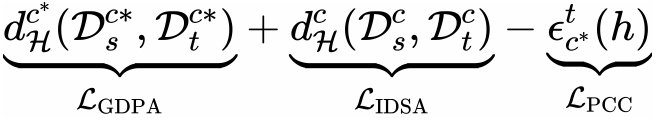
中的项。GDPA最小化域私有类别 域分布差异,适用于全局级特征;IDSA 最小化域共享类别域分布差异 ,适用于实例级特征。此外,PCC 最大化目标域的域私有类别风险误差。
具体来说,GDPA 利用全局级别采样挖掘域私有类别样本并通过累积分布函数计算对齐权重来解决全局级别私有类别对齐。IDSA 利用实例级别采样挖掘域共享类别样本并通过高斯分布计算对齐权重来进行域共享类别域对齐以解决特征异质性问题。PCC 在特征和概率空间之间聚合域私有类别质心以缓解负迁移。
实验结果
我们在三个域自适应场景(开放集、部分集和封闭集)中,针对五个数据集对我们的DPA框架进行了评估。这些数据集包括:Foggy Cityscapes、Cityscapes、Pascal VOC、Clipart1k 和 Watercolor。我们在三钟域自适应场景(开放集、部分集和封闭集)中,针对五个数据集对我们的DPA框架进行了评估。这些数据集包括:Foggy Cityscapes、Cityscapes、Pascal VOC、Clipart1k 和Watercolor。
在开放集场景中,源域和目标域均包含共享类别和私有类别样本。我们引入了多个共享类别比例来构建不同的共享类别比例基准,其中和分别表示源域和目标域的类别集合。在部分集场景中,源域的类别集合是目标域类别集合的子集,或者反之亦然。在封闭集场景中,源域和目标域的类别集合完全相同。
开放集场景中的性能结果
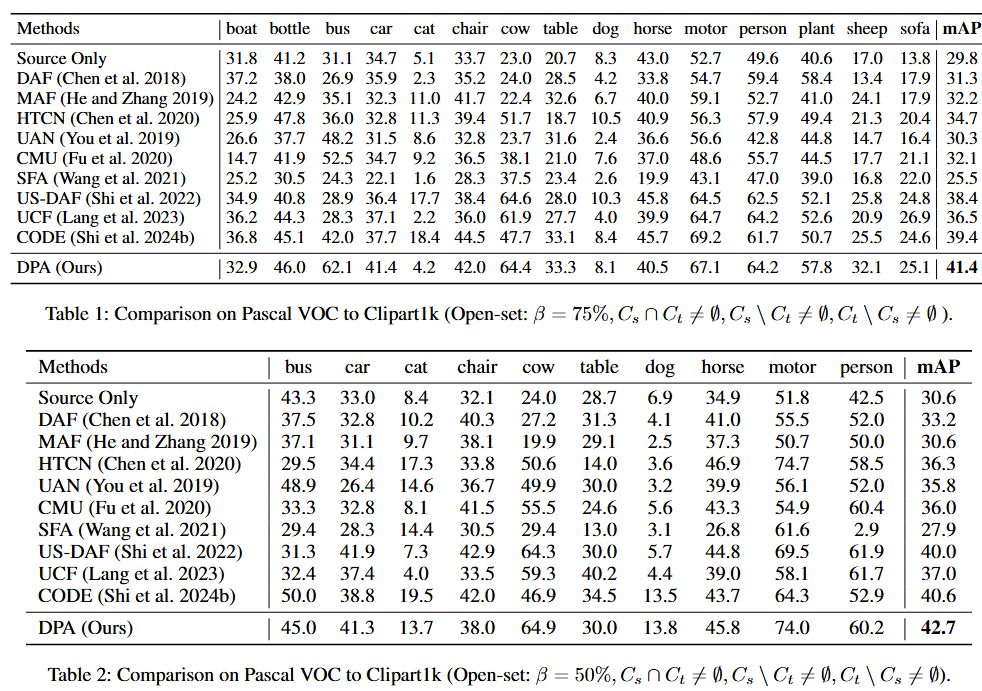
开放集场景中的性能结果
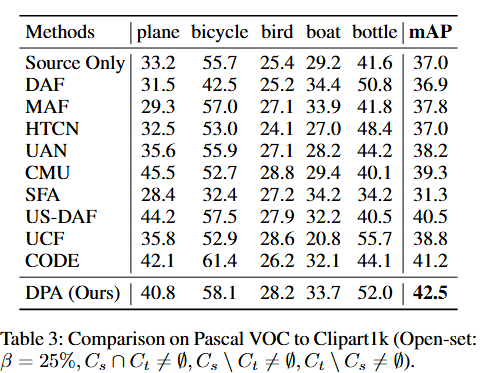
部分集场景中的性能结果
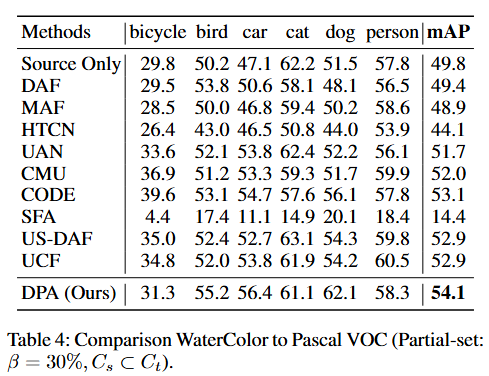
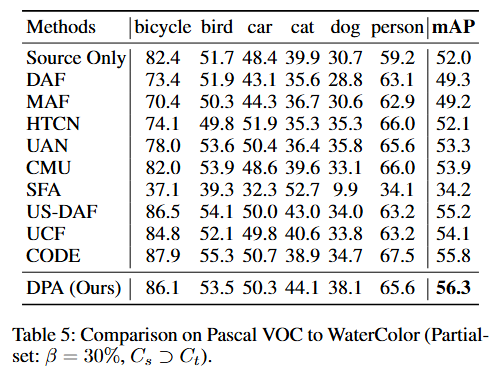
封闭集场景中的性能结果
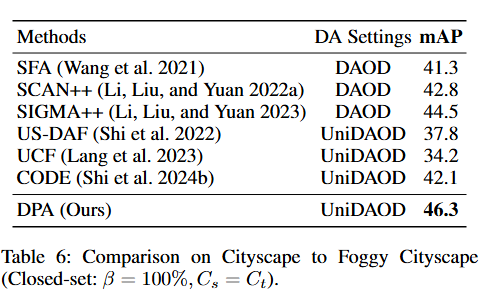
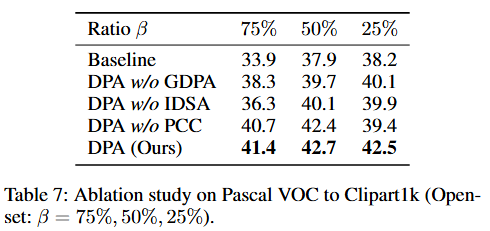
消融实验
可视化分析
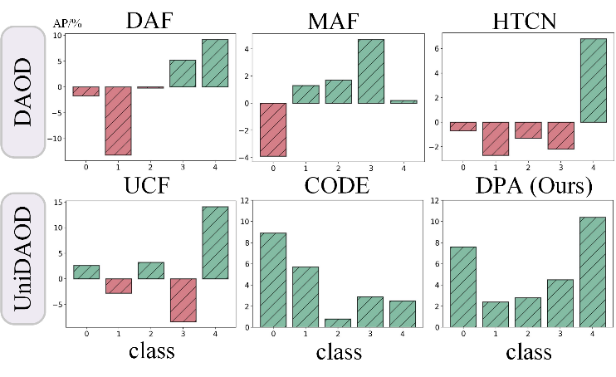
为了比较所提方法与现有 DAOD 和 UniDAOD 方法在正迁移和负迁移方面的性能,我们在图 7 中展示了 DAOD 和 UniDAOD 相对于仅使用源域模型的性能提升。
结果显示,DAOD 方法存在显著的负迁移,其中 DAF、MAF 和 HTCN 在类别 0 上的平均精度(AP)分别下降约 2%、4% 和 1%。
相比之下,UniDAOD 方法有效缓解了负迁移,CODE 和 DPA 在类别 4 上分别实现了约 3% 和 10% 的正迁移。这种基于类别的性能分析证明了所提方法能够有效应对负迁移并增强正迁移效果。
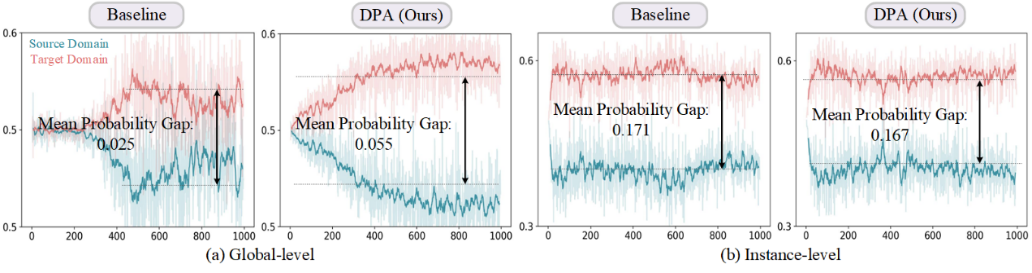
我们进一步分析了 DPA 框架在开放集对齐中的概率差表现。如图8(a) 所示,全局级别的平均概率差在 DPA 中更加显著,这突显了其在区分域私有类别方面的有效性。相比之下,图 8(b) 显示实例级别的平均概率差较小,这表明 DPA 能更好地对齐域共享类别。
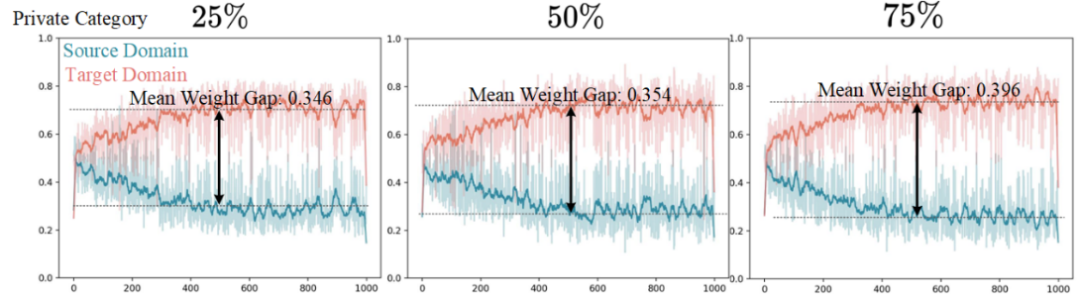
此外,我们对全局域私有对齐进行了权重定量分析(见图9)。随着域私有类别比例的增加,平均权重差也随之增大,这表明对抗训练通过权重调整,自适应地惩罚了与域私有类别相关的特征。
总结
我们提出了一种用于通用域自适应目标检测的DPA框架,包含两种概率对齐方式。
受理论视角启发,我们设计了GDPA模块,用于对齐全局私有样本,以及IDSA模块,用于对齐实例级域共享样本。为应对负迁移问题,我们引入了PCC模块,用于混淆私有类别的可辨识性。
大量实验表明,在开放集、部分集和封闭集场景中,DPA框架显著优于现有的通用域自适应目标检测方法。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「目标检测」交流群👇备注:OD



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









