










简述
该例子为从一个Collection获取数据然后插入到另外一个Collection中。
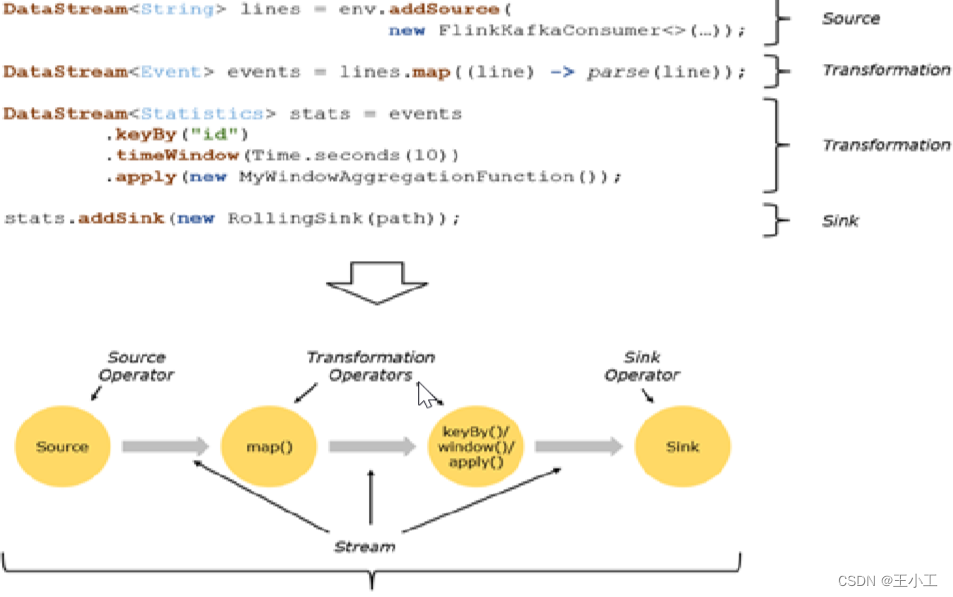
Flink的基本处理过程可以清晰地分为以下几个阶段:
- 数据源(Source):
- Flink可以从多种数据源中读取数据,如Kafka、RabbitMQ、HDFS等。
- Flink会将从数据源中读取到的数据转化为一个个数据流,这些数据流可以是无限大的(如实时数据流),也可以是有限大小的(如批量数据流)。
- 数据转换(Transformation):
- Flink提供了各种数据转换算子(Operators),可以对数据流进行各种操作,包括map、filter、reduce、join等。
- 这些算子帮助用户对数据流进行各种数据处理和计算操作。
- 在Flink中,主要有三类Operator:
- Source Operator:负责数据来源操作,如从文件、socket、Kafka等读取数据。
- Transformation Operator:负责数据转换,如map、flatMap、reduce等算子。
- Sink Operator:负责数据落地操作,如将数据写入Hdfs、Mysql、Kafka等。
- 数据输出(Sink):
- Flink会将处理后的数据输出到指定的目标,这些目标可以是多种类型的数据存储系统,如Kafka、HDFS、MySQL等。
- Flink支持将数据输出到多个目标,并可以进行复制备份。
- Flink核心组件和工作流程:
- Flink在运行中主要有三个核心组件:JobClient、JobManager和TaskManager。
- 用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化后提交到JobManager,最后由TaskManager运行task。
- JobClient是Flink程序和JobManager交互的桥梁,主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。
- 执行图(ExecutionGraph):
- Flink中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- 每一个dataflow以一个或多个sources开始,以一个或多个sinks结束,dataflow类似于任意的有向无环图(DAG)。
- 优化过程:
- Flink会对用户提交的执行计划进行优化,主要优化是将相邻的Operator融合,形成OperatorChain,以提高处理效率。
代码
主要函数
package com.wfg.flink.connector.mongodb;
import com.alibaba.fastjson2.JSON;
import com.mongodb.client.model.InsertOneModel;
import com.wfg.flink.connector.mongodb.model.WellCastingInfo;
import com.wfg.flink.connector.mongodb.schema.WellCastingInfoDeserializationSchema;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.mongodb.sink.MongoSink;
import org.apache.flink.connector.mongodb.source.MongoSource;
import org.apache.flink.connector.mongodb.source.enumerator.splitter.PartitionStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.bson.BsonDocument;
/**
* @author wfg
*/
@Slf4j
public class Main {
public static void main(String[] args) throws Exception {
MongoSource<WellCastingInfo> mongoSource = MongoSource.<WellCastingInfo>builder()
.setUri("mongodb://root:123456@127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/admin?replicaSet=rs0&authSource=admin")
.setDatabase("uux")
.setCollection("castingInfo")
// .setProjectedFields("_id", "f0", "f1")
.setFetchSize(2048)
.setLimit(10000)
.setNoCursorTimeout(true)
.setPartitionStrategy(PartitionStrategy.SAMPLE)
.setPartitionSize(MemorySize.ofMebiBytes(64))
.setSamplesPerPartition(10)
.setDeserializationSchema(new WellCastingInfoDeserializationSchema())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从 MongoDB 读取数据
DataStream<WellCastingInfo> sourceStream = env.fromSource(mongoSource, WatermarkStrategy.noWatermarks(), "Mongo Source");
// 进行转换(如果需要)
DataStream<WellCastingInfo> transformedStream = sourceStream.map((MapFunction<WellCastingInfo, WellCastingInfo>) value -> {
// 转换逻辑
return value;
});
MongoSink<WellCastingInfo> sink = MongoSink.<WellCastingInfo>builder()
.setUri("mongodb://root:123456@127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/admin?replicaSet=rs0&authSource=admin")
.setDatabase("uux")
.setCollection("castingInfo_back")
.setMaxRetries(3)
// .setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setSerializationSchema(
(input, context) -> new InsertOneModel<>(BsonDocument.parse(JSON.toJSONString(input))))
.build();
transformedStream.sinkTo(sink);
// stream.sinkTo(sink);
// 执行作业
env.execute("Mongo Flink Demo");
}
}
数据解析处理
package com.wfg.flink.connector.mongodb.schema;
import com.alibaba.fastjson2.JSONObject;
import com.alibaba.fastjson2.JSONReader;
import com.wfg.flink.connector.mongodb.model.WellCastingInfo;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.TypeExtractor;
import org.apache.flink.connector.mongodb.source.reader.deserializer.MongoDeserializationSchema;
import org.bson.BsonDocument;
import java.util.Date;
/**
* @author wfg
*/
@Slf4j
public class WellCastingInfoDeserializationSchema implements MongoDeserializationSchema<WellCastingInfo> {
@Override
public WellCastingInfo deserialize(BsonDocument bsonDocument) {
WellCastingInfo rs = null;
try {
JSONObject obj = JSONObject.parseObject(bsonDocument.toJson());
obj.remove("_id");
obj.remove("time");
obj.remove("_class");
rs = obj.to(WellCastingInfo.class, JSONReader.Feature.IgnoreAutoTypeNotMatch);
if (bsonDocument.getObjectId("_id") != null) {
rs.setId(bsonDocument.getObjectId("_id").getValue().toString());
}
if (bsonDocument.get("time") != null) {
rs.setTime(new Date(bsonDocument.getDateTime("time").getValue()));
}
} catch (Exception e) {
log.error("数据格式错误:{}:{}", bsonDocument.toJson(), e);
}
return rs;
}
@Override
public TypeInformation<WellCastingInfo> getProducedType() {
return TypeExtractor.getForClass(WellCastingInfo.class);
}
}
数据类
package com.wfg.flink.connector.mongodb.model;
import lombok.Data;
import java.util.Date;
/**
* @author wfg
*/
@Data
public class WellCastingInfo {
private String id;
private String comCode;
private Date time;
private String yjsfzt;
private String yjsyl;
private String jjaqzfzt;
private String spjk01;
private String jyjqy;
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wfg.flink.connector</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>connector-mongodb</artifactId>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.18.1</flink.version>
<log4j.version>2.14.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-mongodb</artifactId>
<version>1.1.0-1.18</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.50</version>
</dependency>
</dependencies>
</project>
说明
MongoSource
MongoSource通常指的是一个自定义的数据源(Source),用于从MongoDB数据库中读取数据。
- 依赖
首先,需要在项目的pom.xml文件中引入Flink MongoDB连接器的依赖。这通常包括Flink的MongoDB连接器以及MongoDB的Java驱动。例如:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-mongodb</artifactId>
<version>1.1.0-1.18</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
- 创建MongoSource
创建一个自定义的MongoSource类,该类通常继承自Flink的RichSourceFunction或其他相关的Source Function接口。在这个类中,需要实现与MongoDB的连接、查询和数据读取的逻辑。 - 关键方法
- **open(Configuration parameters):**在这个方法中,可以初始化MongoDB的连接,如创建一个MongoClient实例。
- **run(SourceContext ctx):**这个方法负责从MongoDB中读取数据,并将数据发送到Flink的SourceContext中。可以使用MongoDB的查询API来执行查询操作,并将结果转换为Flink可以处理的数据类型(如Tuple、POJO等)。
- **cancel():**当Flink作业被取消时,这个方法会被调用。可以在这个方法中关闭MongoDB的连接或执行其他清理操作。
- 配置和使用MongoSource
可以通过调用StreamExecutionEnvironment的addSource方法来添加自定义MongoSource。例如:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<YourDataType> dataStream = env.addSource(new YourMongoSource());
// ... 后续的数据处理和转换操作 ...
注意事项:
- 确保MongoDB服务器的地址、端口和凭据等信息在MongoSource中正确配置。
- 根据需求,可以调整MongoDB的查询条件、分页参数等,以控制从MongoDB中读取的数据量和频率。
- 如果Flink作业需要处理大量的数据,考虑使用MongoDB的索引来优化查询性能。
- 在处理完数据后,确保关闭与MongoDB的连接,以避免资源泄漏。
env.fromSource
env.fromSource 并不是一个直接的方法或表达式。env 通常指的是 Flink 的 StreamExecutionEnvironment 或 ExecutionEnvironment 对象,它们用于设置 Flink 流处理或批处理作业的上下文和执行环境。
然而,为了从外部数据源读取数据到 Flink 作业中,会使用 env 对象上的各种方法来创建数据源。例如,对于流处理,可能会使用 env.addSource(sourceFunction),其中 sourceFunction 是一个实现了 SourceFunction 接口或继承自 RichParallelSourceFunction 的类,它定义了如何从外部系统(如 Kafka、文件系统、数据库等)读取数据。
对于常见的外部数据源,Flink 提供了各种预定义的连接器和数据源函数,可以直接使用它们,而无需自己实现 SourceFunction。例如:
- Kafka: 使用 FlinkKafkaConsumer
- Files: 使用 FileSource 或 StreamExecutionEnvironment.readFile()
- JDBC: 使用 JdbcInputFormat 或第三方库如 flink-connector-jdbc
算子操作
算子(Operator)是数据处理的核心构建块。它们定义了如何转换或处理数据流(DataStream)或数据集(DataSet)。Flink 提供了丰富的算子库来支持各种数据处理任务。以下是一些常见的 Flink 算子操作:
- 转换(Transformation)算子
- map:对每个元素应用一个函数,并返回一个新的元素。
- flatMap:对每个元素应用一个函数,该函数可以返回任意数量的元素。
- filter:过滤出满足特定条件的元素。
- keyBy:按一个或多个键对流进行分区,以便后续可以进行有状态的操作(如聚合)。
- reduce:在具有相同键的分组数据上应用一个聚合函数。
- sum、min、max 等:针对特定数据类型的内置聚合函数。
- 连接(Join)和联合(Co-operation)算子
- timeWindowAll、timeWindow:在时间窗口内对元素进行聚合。
- intervalJoin:基于时间间隔的连接操作。
- connect:连接两个流以进行联合操作,如 coMap、coFlatMap 等。
- union:将两个或多个流合并为一个流。
- 窗口(Window)算子
- tumblingWindow:滚动窗口,窗口之间没有重叠。
- slidingWindow:滑动窗口,窗口之间可以重叠。
- sessionWindow:会话窗口,基于元素之间的时间间隔动态创建窗口。
- 状态和容错
- process:一个低级的算子,允许访问元素的时间戳和状态。
- checkpointing:用于在 Flink 作业中启用容错和状态一致性。
- 侧边输出(Side Outputs)
- 在某些算子中,可以定义侧边输出来处理不符合主逻辑的异常或特殊情况的元素。
- 异步 I/O 操作
- asyncFunction:允许执行异步操作(如数据库查询)而不阻塞 Flink 的主数据流。
- 广播(Broadcast)和重分区(Redistribute)
- broadcast:将数据发送到所有并行子任务。
- rebalance、rescale、shuffle:用于改变流中的元素分布。
- 迭代(Iteration)
- Flink 支持迭代处理,允许重复处理数据直到满足某个条件。
MongoSink
- MongoSink implements Sink
public SinkWriter<IN> createWriter(Sink.InitContext context) {
return new MongoWriter(this.connectionOptions, this.writeOptions, this.writeOptions.getDeliveryGuarantee() == DeliveryGuarantee.AT_LEAST_ONCE, context, this.serializationSchema);
}
- MongoWriter implements SinkWriter
- write: 写入数据
- flush: doBulkWrite写入数据。
- close: 关闭链接
- MongoSinkBuilder
- setUri: 设置Mongodb链接
- setDatabase: 设置Database
- setCollection: 设置Collection
- setBatchSize: 为每个批处理请求设置要缓冲的最大操作数。可以通过-1到
禁用批处理。 - setBatchIntervalMs: 设置批处理刷新间隔(以毫秒为单位)。可以通过-1来禁用它。
- setMaxRetries: 设置写入记录失败时的最大重试次数。
- setDeliveryGuarantee: 设置保存保证,默认保存保证为DeliveryGuarantee#AT_LEAST_ONCE
- setSerializationSchema: 设置对每条记录调用的序列化模式,以将其转换为MongoDB批量
要求
MongoSink<WellCastingInfo> sink = MongoSink.<WellCastingInfo>builder()
.setUri("mongodb://root:123456@127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/admin?replicaSet=rs0&authSource=admin")
.setDatabase("sjzz")
.setCollection("wellCastingInfo_back")
.setMaxRetries(3)
// .setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setSerializationSchema(
(input, context) -> new InsertOneModel<>(BsonDocument.parse(JSON.toJSONString(input))))
.build();
transformedStream.sinkTo(sink);
Flink 1.12 之前,Sink 算子是通过调用 DataStream 的 addSink 方法来实现的:
stream.addSink(new SinkFunction(...));
从 Flink 1.12 开始,Flink 重构了 Sink 架构:
stream.sinkTo(...)
env.execute(“Mongo Flink Demo”)
env.execute() 是用于启动 Flink 作业(Job)的关键方法。这里的 env 通常是一个 StreamExecutionEnvironment 或 ExecutionEnvironment 的实例,它们分别用于 Flink 的 DataStream API 和 DataSet API。
当创建了一个 Flink 作业,定义了数据源、转换(transformations)和数据接收器(sinks)之后,需要调用 env.execute() 来触发 Flink 运行时(runtime)执行作业。
需要注意的是,一旦调用了 env.execute(),Flink 运行时就会开始执行作业,并且 env.execute() 方法会阻塞,直到作业执行完成或发生错误。如果希望程序在启动 Flink 作业后继续执行其他操作,可以考虑将 Flink 作业提交到远程集群并在本地程序中继续执行其他任务。这通常需要使用 Flink 的集群客户端(ClusterClient)或相应的 REST API 来实现。















 4920
4920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









