







 本文提出一种面向内容的图像压缩方案,根据不同图像区域的特点采用不同的损失函数,如结构区域使用拉普拉斯损失,纹理区域使用LPIPS损失,小人脸区域使用MSE损失。通过有标记的学习方式改善了现有方法在不同内容上的压缩效果。
本文提出一种面向内容的图像压缩方案,根据不同图像区域的特点采用不同的损失函数,如结构区域使用拉普拉斯损失,纹理区域使用LPIPS损失,小人脸区域使用MSE损失。通过有标记的学习方式改善了现有方法在不同内容上的压缩效果。
Content-Oriented Learned Image Compression (ECCV 2022)
2022/08/12: 这篇文章比较简单,也不想全文翻译浪费时间,直接讲思路吧。
Abstract
近年来,随着深度神经网络的发展,端到端优化图像压缩取得了重大进展,在率失真性能上超过了经典方法。然而,大多数基于学习的图像压缩方法是无标记的,在优化模型时不考虑图像语义或内容。其实人眼对不同内容的敏感度是不同的,所以图像内容也是需要考虑的。在本文中,我们提出了一种面向内容的图像压缩方法,用不同的策略处理不同类型的图像内容。大量实验表明,该方法取得了与最先进的端到端学习图像压缩方法或经典方法相比较的主观结果。
1. Introduction
第一段指出图像压缩的必要性以及传统编码方法是手工设计的各个模块,无法实现全局优化,也就无法实现全局最优。第二段指出现在深度学习端到端方法主要的优势是可以整个框架进行联合优化,并且近年来E2E方法主要依靠VAE和GAN来压缩图像,使用的损失基本是MSE、MS-SSIM和LPIPS等。这些方法在全局上使用相同方式进行优化,但是人类的视觉感知对某些信息是敏感的,而对有些信息是不敏感的。使用MSE优化,结构信息例如文本信息和线条可以正确保留,但是重构图像会变得比较模糊。使用GAN和LPIPS优化,信息细节保存得很好,但结构信息却被扭曲了,如文字扭曲、人脸扭曲等。图像内容在人类的感知中起着重要的作用,人眼对不同的内容有不同的敏感度。然而,在基于学习的图像压缩中,图像内容的影响在很大程度上被忽略了。

因此,针对上述问题,本文提出了一种面向内容的图像压缩方案,该方案适用于现有的大多数框架。具体来说,在训练阶段,将图像分成不同的区域,并根据其特点使用不同的损失度量。据我们所知,这是第一种在不改变架构的情况下提高视觉感知质量的面向内容的图像压缩方法。图1给出了一个实例,说明了该方法的优越性。本文的贡献总结如下:
- 我们提出了一种面向内容的端到端图像压缩方案,在不同的区域使用不同的损耗度量。区域掩码只在训练阶段使用,在编码和解码阶段不需要额外的信息。
- 为了评估该方案,我们设计了一个基于GAN的体系结构作为实例来展示其有效性。通过对几种经典方法和端到端加密方法的比较,我们的方法性能最好。
2. Method
2.1 Framework of our method
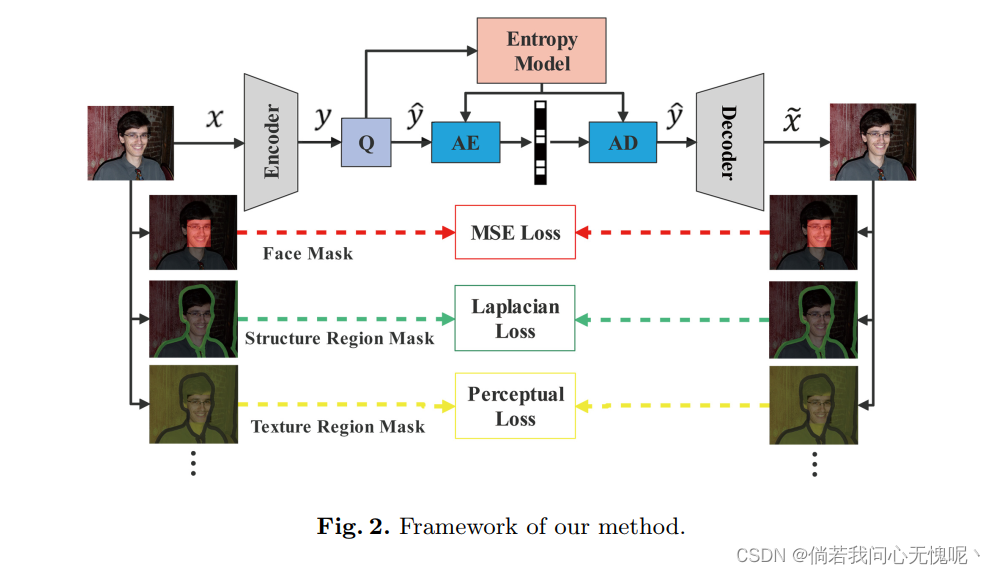
不同的损失函数适用于不同的图像内容。而现有的学习图像压缩总是以相同的损失函数对整个图像进行优化。在现有的与内容相关的图像压缩方法中,重要的映射[17]、ROI掩码[7]或其他额外的信息需要编码作为码流的一部分。这种方法一方面需要改变编码器-解码器的结构,通过添加一个特殊的模块来提取重要的地图或ROI掩码,使体系结构更加复杂,另一方面也增加了额外的比特开销,这不可避免的降低了编码效率。如果架构足够“聪明”,能够区分不同的图像内容并采用不同的压缩策略,这个问题是可以克服的。该方法整体框架如图2所示。掩码信息在训练阶段只用于选择不同的损失函数,在推理阶段不需要。
如图2所示,E2E图像压缩从无标记学习转化为有标记学习。损失函数的选择取决于图像区域的分类。根据前面的分析,我们将图像分为三个图像区域,分别是纹理区域、结构区域和小人脸区域。
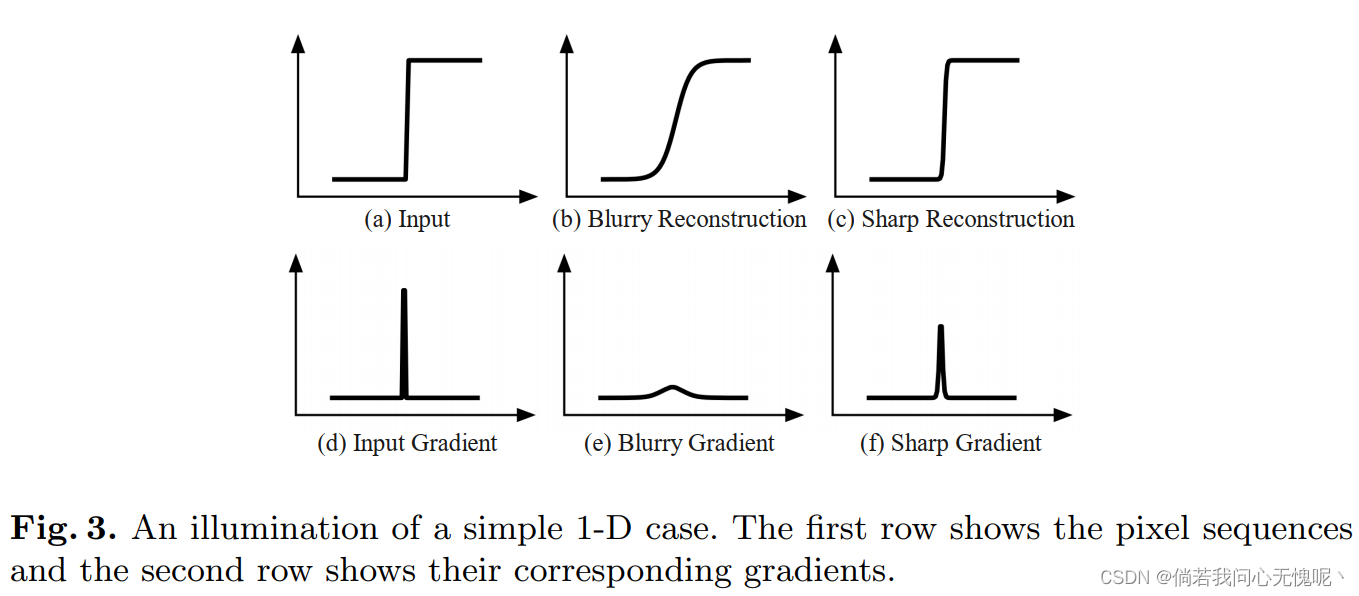
Structure Region. 由于像素的突变,结构区域通常具有较强的梯度,对于非常接近的邻域,统计相关性很小。而接收域较大的损失函数会引入额外的噪声,这对于精确的边缘重建是不可接受的。人眼对结构的清晰度和像素级的正确性非常敏感,因此采用点级损失函数更合适。但是,MSE会导致重建模糊,影响主观视觉感知。因此结构区域采用以下损失函数:
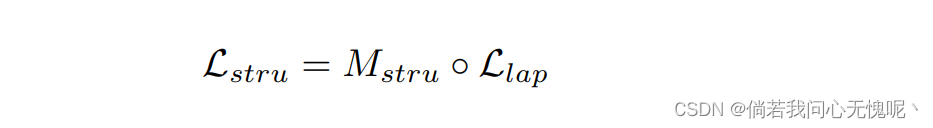
公式右侧两项分别为结构区域的蒙版和拉普拉斯损失,对这个损失不懂的可以参考SPSR(CVPR 2021)【Structurepreserving super resolution with gradient guidance】,这个梯度损失是一个简单且work的损失函数,在各类图像复原的底层任务中都可以使用。
Texture Region. 与结构区域不同,纹理区域具有更多的细节,区域像素高度相关。人眼很难感知逐像素的正确性,人们更关心纹理的分布情况。现有的基于感知优化的方法[20]已经取得了很好的纹理重建效果。因此纹理区域使用MAE损失、LPIPS损失和GAN损失:
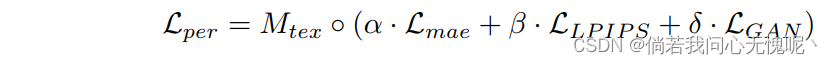
在本文工作中,选择VGG[23]网络作为主干网络来计算LPIPS损耗。
Small Face Region. 在我们的框架中,人脸区域将被分类为纹理区域,并在不干预的情况下优化感知损失。在这种情况下,较大的人脸可以很好地重建,但较小的人脸可能会出现翘曲,如图1左侧所示。因此,我们对小面区域采用不同的损失函数。一般来说,人们对面部结构的正确性是非常敏感的,为此需要进行准确的重建。因此,我们使用更严格的约束损失,即MSE损失,来进行人脸图像重建。

我们使用广为人知的YOLO-face算法来检测图像中的人脸,而
L
s
f
a
c
e
L_{sface}
Lsface算法只应用于小的人脸中。最后,将整个图像的损失函数总结为:
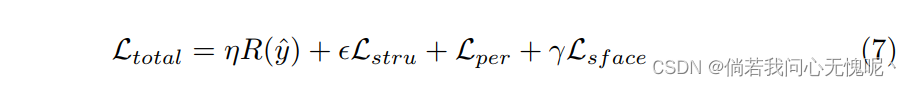
其中,
η
η
η、
ϵ
\epsilon
ϵ和
γ
γ
γ为相应损失度量的权重。因为人们通常更关注图像的面孔,我们有意分配更多的比特在小的面孔上使用较大的
γ
γ
γ。注意,掩码是二进制值的,并且是互斥的。而面膜的优先级也有所不同,具体来说,从高到低依次是:面膜、结构面膜和纹理面膜。换句话说,结构蒙版不覆盖面部区域,纹理蒙版不覆盖面部和结构区域。
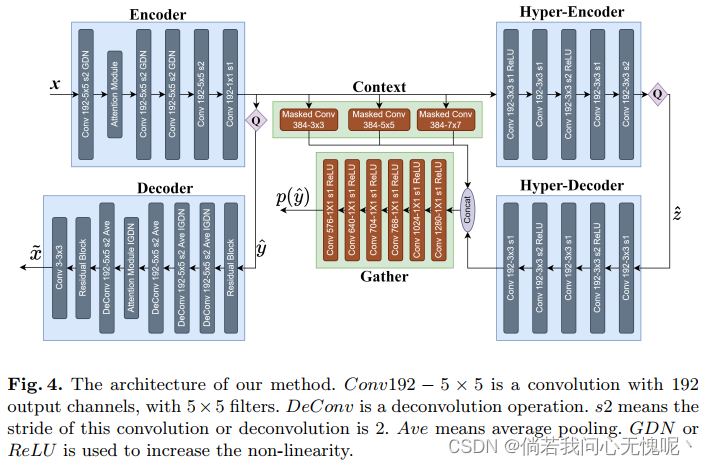
2.2 Architecture
网络结构部分其实没有过多的重点,作者在编码器中为了缓解棋盘格伪影的问题,在每个反卷积层后引入了额外的平均池化层;熵模型部分,采用了非对称高斯模型进行建模;在鉴别器部分使用PatchGAN的鉴别器。
2.3 Implementation of masked perceptual loss
通常,向MSE或MAE添加像素级掩模很容易,只需简单的点乘。但是在LPIPS或GAN损耗上使用比较困难,因为这两种损耗函数计算的是特征损耗,不能对应于掩模像素到像素。本节提出了一种名为“真实价值替换”的方法来解决这个问题。
考虑掩模
M
t
e
x
M_{tex}
Mtex、原始图像
x
x
x和重建图像
x
~
\tilde{x}
x~,我们用对应
x
~
\tilde{x}
x~的值替换
x
x
x的掩码部分的值,以得到被替换的重建图像
x
~
′
\tilde{x}'
x~′
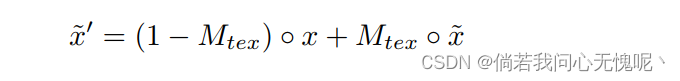
然后直接用x和
x
~
′
\tilde{x}'
x~′计算损失函数来估计掩膜损失:
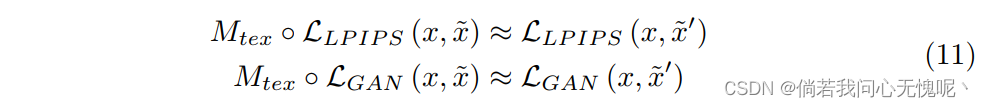
3. Experiment
4.1 Training Details
众所周知,训练GANs生成图像的难度很大,因此将训练过程分为两个阶段。在第一阶段,我们仅以MSE作为畸变损失来指导像素级重构的优化。第一阶段的优化目标是使 L R D = η R + L m s e L_{RD} = ηR + L_{mse} LRD=ηR+Lmse最小化。利用第一阶段的结果作为预训练模型,我们可以在第二阶段用3.2节提到的损失函数(即完全体的损失函数)Eq.7训练感知优化模型。
为了在图像的不同区域使用不同的损失度量,需要不同内容区域的掩码。在我们的实验中,图像中的人脸使用众所周知的YOLO-face[8]检测。然后将人脸的坐标信息存储在XML文件中,用于在训练阶段生成人脸掩码。这样可以节省训练模型时的人脸检测时间。对于结构区域掩码,由于边缘检测复杂度较低,我们在训练时不提前生成掩码,而是直接使用拉普拉斯边缘检测器检测结构区域。(虽然没有放出代码,但这里基本说了如何去实现,但是没有说明纹理区域的掩膜是如何实现的呀。我这里的认为是其实纹理区域压根就没有特有的纹理检测,其实就是整个图像减去了结构区域和面部区域掩膜得到的)
4.2 Ablation Study



从上至下的图分别证明损失函数各个部分的有效性,网络结构各个部分(patchGAN、平均池化)的有效性和所提出方法的有效性。比较的方法是BPG、AGDIC和HIFIC,前两个不是感知优化的,后一个是感知优化的,实验证明所提出方法的视觉感知好。更多与HIFIC比较的例子如图10所示。与HIFIC相比,COLIC不仅可以恢复相似的信息纹理区域,如喷雾,还可以恢复更好的结构区域,如线条、纹理和小人脸。总之,COLIC可以达到更好的视觉效果。
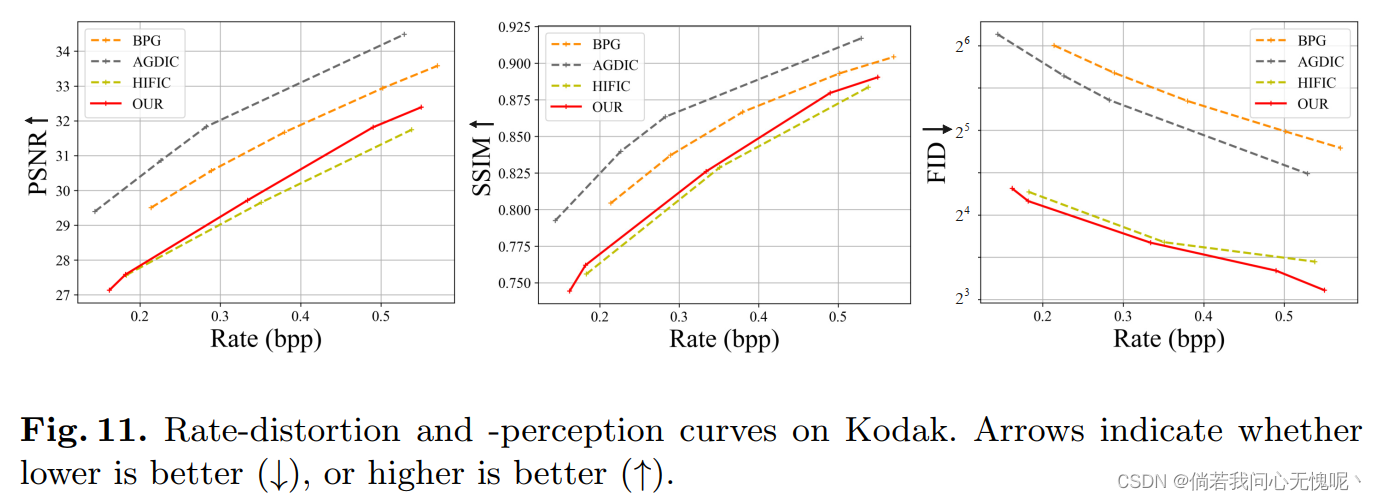
为了提高视觉质量,我们牺牲了一些客观指标。与HIFIC相比,COLIC在客观指标和感知指标上都取得了更好的效果。这归功于对结构区域施加正确约束的优化损失较好,重构能力较强的网络结构较好,以及训练策略较好。(这部分其实挺有意思的,虽然给出了每个损失和每个部分对于主观质量的影响,但是缺少了客观指标的一个说明。采用MAE损失的PSNR就是会高一些,而感知损失与GAN损失就是主观效果要好一丢丢但其实容易产生扭曲边缘,并且客观指标较低。)
4. Conclusion
在这项工作中,我们提出了一个面向内容的图像压缩方案,可以用于大多数现有的方法。我们建议对不同的图像内容根据其特点采用不同的损失函数。一个基于GAN设计的网络结构,验证了该方案的有效性。实验清楚地显示了我们的方法在视觉质量和不同的指标上的优越性。事实上,该方法的有效性表明,现有的编码器和解码器具有足够的“智能”来区分不同的图像区域,并在不同训练损失的指导下采用不同的重建策略。因此,通过监督训练的方法可以更好地利用人的知觉先验,获得更好的主观结果。


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











