










绪论
本文针对熵模型优化提出使用离散化的高斯混合模型已提供更灵活的隐层表示分布估计,此外在网络结构中使用注意力模块关注复杂区域以提高性能。是第一个达到与VTM 5.2相近表现的工作。
提出的方法
压缩模型公式化

其中分别代表原始图像,重建图像,隐层表示,量化后的隐层表示,
是可训练参数。
代表量化、熵编码。推理时,
是四舍五入量化,生成
经过熵编码为比特流。简单起见使用
代替
。如果给定一个概率模型
,熵编码技术可以无损压缩已经量化后的数据。算术编码器是一种接近最优的编码器,这使得在训练过程中使用
的熵来估计编码率是可行的。
图2中,(a)结构隐层的边缘分布未知且没有额外比特用来估计
,用一个非自适应的、编码端和解码端共享的密度模型,分解先验模型作为熵模型。之后,提出超先验模型(b),引入边信息
捕获
中元素间存在的依赖,公式化如下:
其中和
是超分析、合成变换,
是可训练参数。
是以
为条件的估计分布,在超先验那篇文章中被建模为0均值高斯分布,
。
之后,自回归上下文模型(c)被提出,其中代表自回归上下文模型。
可学习的图像压缩是一个基于拉格朗日乘子的率失真优化。损失函数如下:
没有先验,将其分布建模为分解密度模型:
剩下的部分介绍如何精确建模
离散高斯混合似然

上图显示熵模型是如何工作的,HyperPrior采用0均值高斯分布,Joint采用带和
的高斯分布,Our Approach采用高斯混合模型。只显示熵值最高的通道,第一列是量化后的隐层
;第二、三列是熵模型预测得到的均值和方差;第四列是
,用来衡量未被熵模型捕获的剩余冗余;第五列是
,计算使用熵模型预测分布编码每个位置所需比特。
通常来说,预测均值接近
,复杂区域有更大的
,需要更多的比特来编码,相反平滑区域需要相对少的比特。HyperPrior仍然存在空间冗余,比如天空。相比HyperPrior,Joint通过引入自回归模型建模上下文相关性使得预测更准确(第四列结构相对少)。但由2行4列还能观察到空间冗余,尽管周围元素已经作为上下文模型的输入,参数化分布不能很好利用上下文信息和额外的比特
。这可能是被单个高斯模型的固定形状限制了。于是考虑使用更灵活的参数模型——高斯混合模型:
上式通常需要连续值,是离散的,受到PixelCNN++的启发,提出离散化的高斯混合似然。因为高斯混合表现优于逻辑混合分布,所以使用高斯混合。熵模型公式化如下:
i代表特征图中位置,k代表第k个高斯分布,代表累计分布函数。为了实现训练稳定,将
裁剪到
范围内,当-255时,c为0,当255时,c为1。
该方法可视化结果为图3后三行,实验中设置K=3,第5列显示每个位置第k个高斯分布的权重。虽然第4列显示还存在一些空间冗余,但是混合模型可以调节不同高斯不同位置的权重。另外,我们方法的方差更小,说明熵模型更精确,使用的比特就更少。4行1列显示了编码需要的比特数。
该机制与CABAC的MPS相似,但隐层表示不限于二进制,一种极端是平滑区域,两个平均值都相同,退化为单个高斯模型;一种极端是边界、复杂区域,三个均值都不同,这会导致似然中出现三个峰值代表三个最可能的值。另外模型参数可训练,因此我们的方法更灵活、精确。图2(d)为高斯混合模型结构。
网络结构

其中,使用残差块增大感受野,解码端使用subpixel convolution而非transposed convolution上采样以保留更多细节。
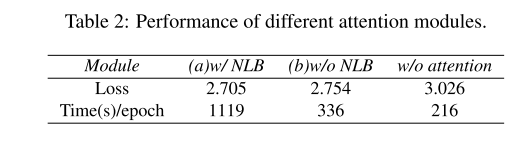
另外使用注意力模块提升图像压缩、重建性能。注意力模块能够帮助网络将更多注意力放在复杂区域、减少简单区域的比特。移除non local block简化注意力结构,因为在我们的结构中深层残差块已经捕获了足够大的感受野。训练损失与时间比较如表2。

实验
消融实验:

RD曲线:

可视化结果:

Appedix
略















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









