





本文主要参考博客标签传播算法(Label Propagation)及Python实现以及七月算法机器学习算法公开课标签传递算法-七月算法_邹博
一、机器学习的分类
机器学习可以大体分为三大类:监督学习、非监督学习和半监督学习。
监督学习指的是有大量训练样本,通过训练出一个模型来对测试样本进行分类。典型的有SVM、朴素贝叶斯分类。监督学习在训练样本时完全不考虑测试样本,仅仅根据训练样本的信息来训练分类模型。无监督指的是没有任何训练样本,直接根据测试样本集之间的内在相似性进行划分,典型的有K-means聚类。半监督学习位于两者之间,指的是已知类别的样本数较少,不足以训练出一个模型,而要根据这少量的已知类别的样本数据去对大量未知类别的测试样本进行分类。半监督和监督学习的区别在于,半监督在一开始分类的时候就考虑了未知类别的测试样本和已知类别的训练样本之间的关联性。标签传播算法(label Propagation)就属于半监督学习。
二、标签传播算法
标签传播算法针对的问题是:对于部分样本的标记给定,而大多数样本的标记未知的情形,是半监督学习问题。
简单的说,标签传递算法(Label Propagation Algorithm,LPA),将标记样本的标记通过一定的概率传递给未标记样本,直到最终收敛。那么就引伸出一个关键问题:“一定的概率”究竟是怎么计算的?在标签传递算法中,是通过构造相似矩阵来评估样本之间的相似性的。
LP算法包括两大步骤:1)构造相似矩阵;2)传播。
2.1构造相似矩阵
LP算法是基于Graph的,因此我们需要先构建一个图。我们为所有的数据构建一个图,图的节点就是一个数据点,包含labeled和unlabeled的数据,也就是说将所有的数据(包括labeled以及unlabeled)连接起来。节点i和节点j的边表示他们的相似度。这个图的构建方法有很多,这里我们假设这个图是全连接的,节点i和节点j的边权重为:
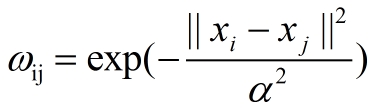
分析一下这个公式,xi和xj“距离”越近,该式越大,即权重越大。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









