








1. 导入依赖包
#coding:utf-8
from gen_captcha import gen_captcha_text_and_image
from gen_captcha import number
from gen_captcha import alphabet
from gen_captcha import ALPHABET
import numpy as np
import tensorflow as tf #tensorflow2.生成验证码用于训练模型
text, image = gen_captcha_text_and_image() #先生成验证码和文字测试模块是否完全
print("验证码图像channel:", image.shape) # (60, 160, 3)
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = len(text)
print("验证码文本最长字符数", MAX_CAPTCHA) # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐
# 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
# r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
# gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img
"""
cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。
np.pad(image【,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行
"""
# 文本转向量
char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
CHAR_SET_LEN = len(char_set)
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c)-48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + char2pos(c)
vector[idx] = 1
return vector
# 向量转回文本
def vec2text(vec):
char_pos = vec.nonzero()[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx < 36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)
"""
#向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有
vec = text2vec("F5Sd")
text = vec2text(vec)
print(text) # F5Sd
vec = text2vec("SFd5")
text = vec2text(vec)
print(text) # SFd5
"""
# 生成一个训练batch
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN])
# 有时生成图像大小不是(60, 160, 3)
def wrap_gen_captcha_text_and_image():
''' 获取一张图,判断其是否符合(60,160,3)的规格'''
while True:
text, image = gen_captcha_text_and_image()
if image.shape == (60, 160, 3):#此部分应该与开头部分图片宽高吻合
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image()
image = convert2gray(image)
# 将图片数组一维化 同时将文本也对应在两个二维组的同一行
batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
batch_y[i,:] = text2vec(text)
# 返回该训练批次
return batch_x, batch_y3.定义CNN
####################################################################
# 申请占位符 按照图片
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
# 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
# 将占位符 转换为 按照图片给的新样式
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
#w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
#w_c2_alpha = np.sqrt(2.0/(3*3*32))
#w_c3_alpha = np.sqrt(2.0/(3*3*64))
#w_d1_alpha = np.sqrt(2.0/(8*32*64))
#out_alpha = np.sqrt(2.0/1024)
# 3 conv layer
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# Fully connected layer
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
#out = tf.nn.softmax(out)
return out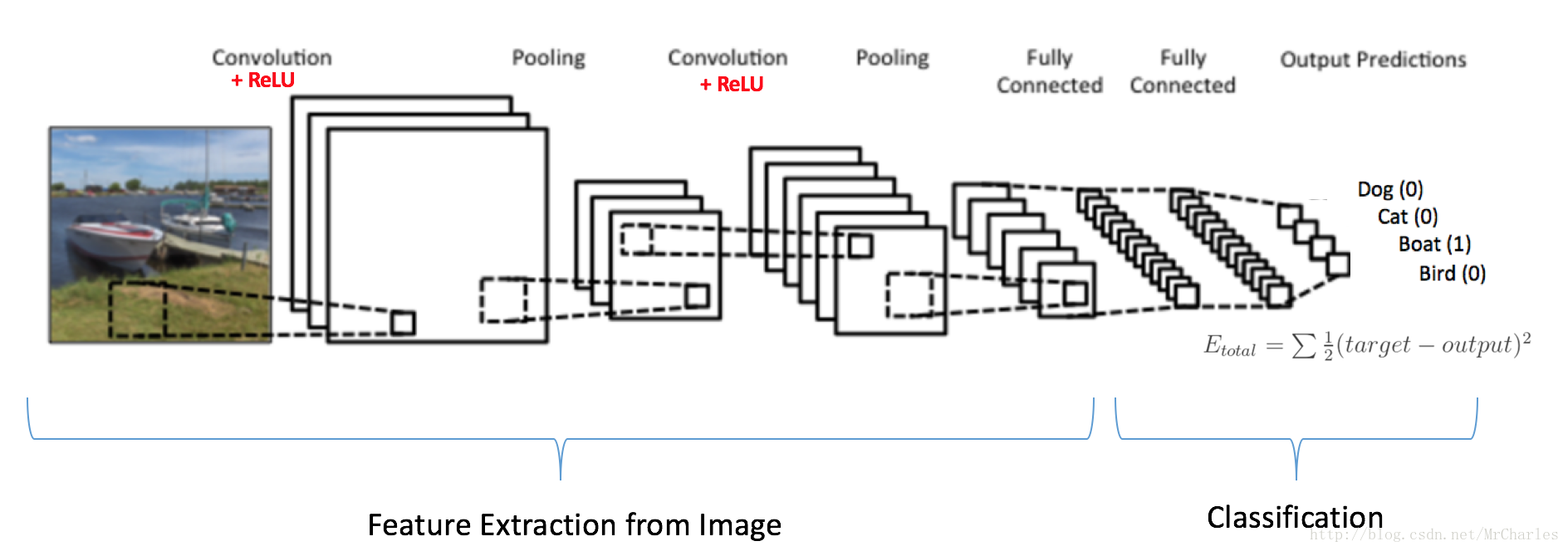

上图就是一个典型的CNN模型,但是只有两层卷积,我们这里有三层。
左边:
数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间:- CONV:卷积计算层,线性乘积 求和。
- RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。
代码解释:
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
权值初始化
为了建立模型,我们需要先创建一些权值(w)和偏置(b)等参数,这些参数的初始化过程中需要加入一小部分的噪声以破坏参数整体的对称性,同时避免梯度为0.由于我们使用ReLU激活函数,所以我们通常将这些参数初始化为很小的正值。
一般卷积层之后会跟一个池化层,所以我们将他们的组合看做一个整体。
这层卷积层总共设置32个神经元,也就是有32个卷积核去分别关注32个特征。窗口的大小是3×3,所以指向每个卷积层的权重也是3×3,因为图片是黑白色的,只有一个颜色通道,所以总共只有1个面,故每个卷积核都对应一组3*3 * 1的权重。
因此w权重的tensor大小应是[3,3,1,32]
b权重的tensor大小应是[ 32 ]
初始化这两个权重:
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
卷积(Convolution)和池化(Pooling)
TensorFlow同样提供了方便的卷积和池化计算。怎样处理边界元素?怎样设置卷积窗口大小?在这个例子中,我们始终使用vanilla版本。这里的卷积操作仅使用了滑动步长为1的窗口,使用0进行填充,所以输出规模和输入的一致;而池化操作是在2 * 2的窗口内采用最大池化技术(max-pooling)。
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME') #使用了滑动步长为1的窗口,使用0进行填充,所以输出规模和输入的一致其中,padding='SAME'表示通过填充0,使得输入和输出的形状一致。
tf.nn.bias_add(conv2d......, b_c1) 对x_image进行卷积计算,加上bias,再应用到一个ReLU激活函数,最终采用最大池化。
tf.nn.relu(........)
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')

全连接层
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
Dropout
# 训练
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y))
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y))
# 最后一层用来分类的softmax和sigmoid有什么不同?
# optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
while True:
batch_x, batch_y = get_next_batch(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print(step, loss_)
# 每100 step计算一次准确率
if step % 100 == 0:
batch_x_test, batch_y_test = get_next_batch(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print(step, acc)
# 如果准确率大于50%,保存模型,完成训练
if acc > 0.5:
saver.save(sess, "crack_capcha.model", global_step=step)
break
step += 1
train_crack_captcha_cnn()执行脚本,报错,
File "C:\Program File\Python\Python35-02\lib\site-packages\tensorflow\python\platform\self_check.py", line 82, in preload_check
% (build_info.cudart_dll_name, build_info.cuda_version_number))
ImportError: Could not find 'cudart64_90.dll'. TensorFlow requires that this DLL be installed in a directory that is named in your %PATH% environment variable. Download and install CUDA 9.0 from this URL: https://developer.nvidia.com/cuda-toolkit
CUDA缺失,这告诉我们,没有GPU驱动,安装驱动即可。到这个地址下载驱动https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exenetwork
http://www.laurencemoroney.com/installing-tensorflow-with-gpu-on-windows-10/ 这个文章详细介绍了GPU驱动
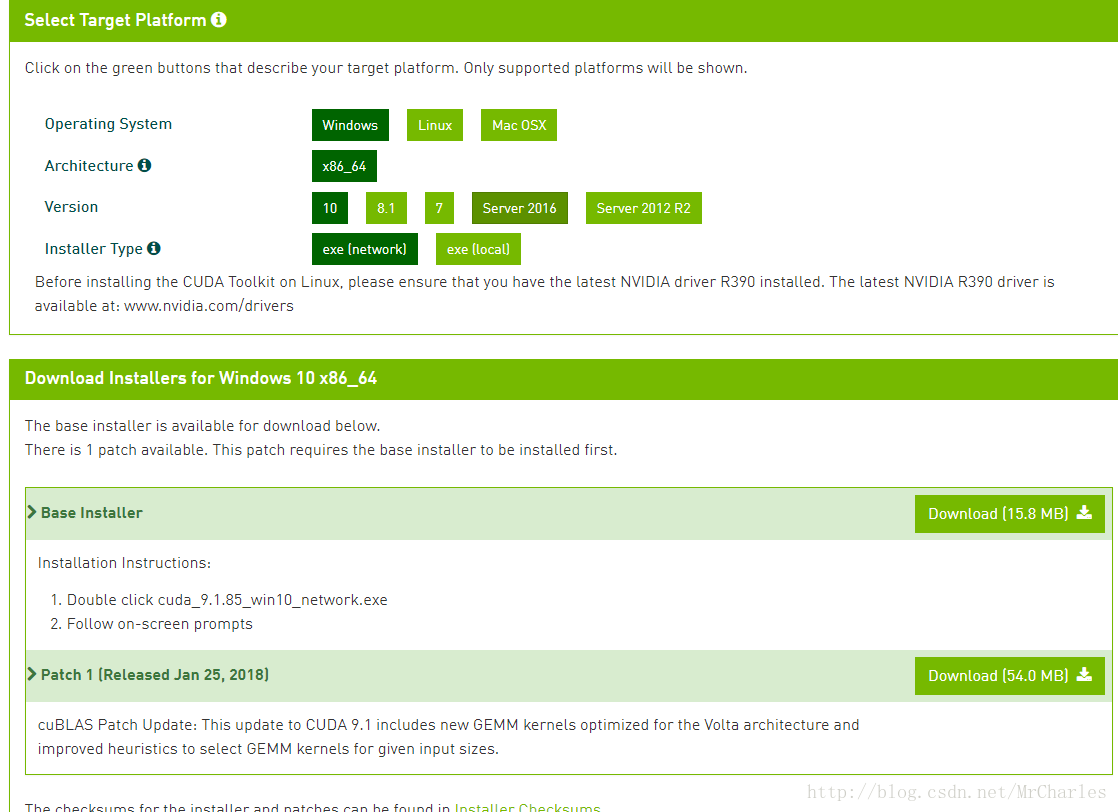
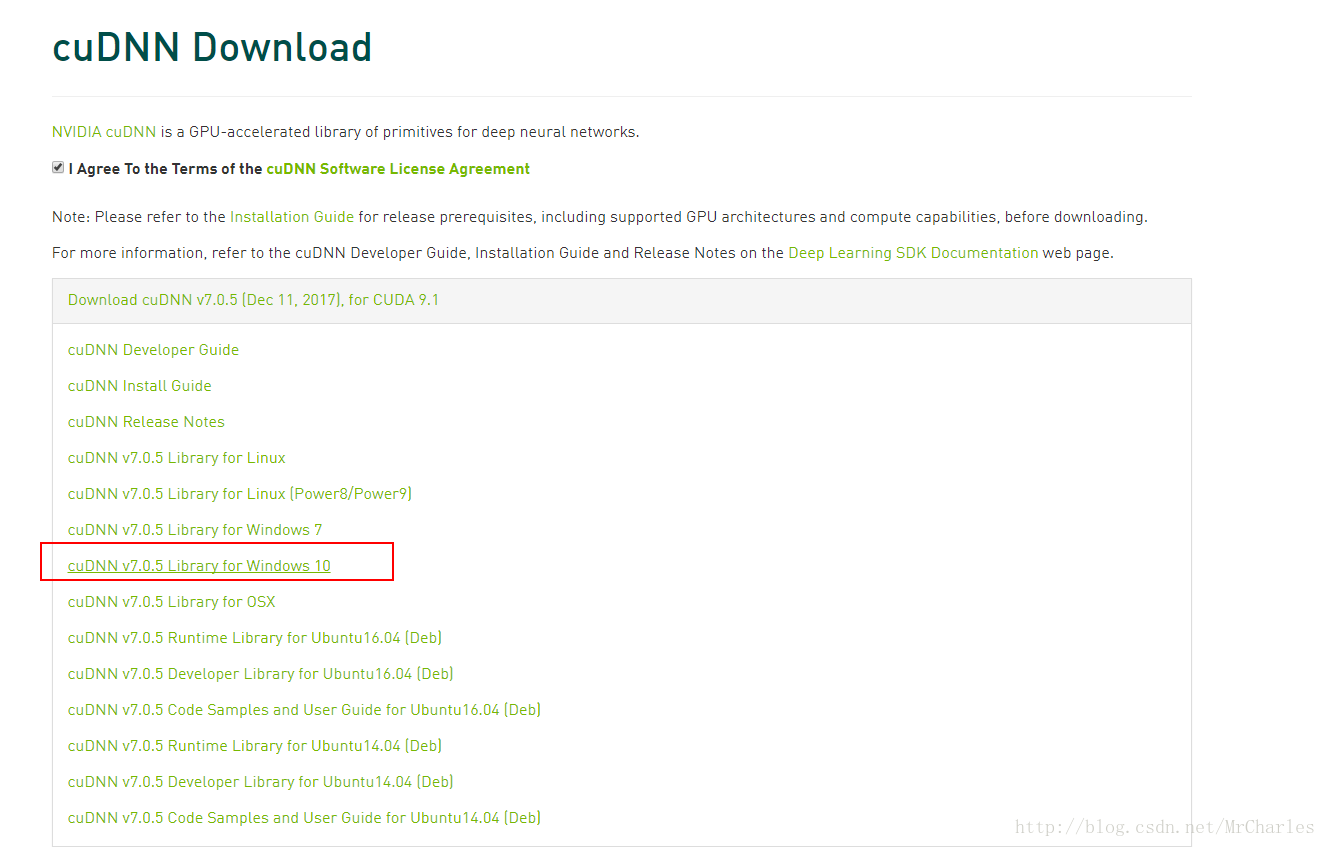
第二个安装cuDNN
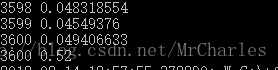
运行3600循环之后,准确率:0.52左右
















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











