







Week 5 Neural Networks:Learning
Cost function
Classification
Examples: {(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
L= total no. of layers in network
Sl= no. of units(not counting bias unit) in layer l
if binary classification
y=0or1 Multi-class classification (K classes)
y∈Rk , E.g. [1000]T,[0100]T,[0010]T,[0001]TIn matlab we often should transfor y from a real number to a vector:
Y = zeros(m,num_labels); for i=1:m, Y(i,y(i)) = 1; endForward propagation algorithm
From
a(1) To a(L) .
a(1)=X
and if we have a(i) :
z(i+1)=Θ(i)a(i)
(sl+1×(sl+1))×((1+sl)×1)=sl+1×1
(where must add a(i)0 )
a(i+1)=g(z(i+1))
So we get a(l) ,Then
hΘ(x)=a(l)Θ(l)ij mappping form note j in layer
l to note i in layerl+1 .
i=1,2,⋯,sl+1 and j=1,2,⋯,sl+1Cost function
J(Θ)=−1m[∑i=1m∑k=1Ky(i)klog((hΘ(x(i)))k+(1−y(i)k)log(1−((hΘ(x(i)))k)]+λ2m∑l=1L−1∑i=2sl+1∑j=1sl+1(Θ(l)ji)2Where: hΘ(x)∈RK , (hΘ(x))i=ith output h.
E.g. in matlab:
J = 1/m * sum(sum(-Y.*log(a3)-(1-Y).*log(1-a3)))... + lambda/2/m * (sum(sum(Theta1(:,2:end).^2)) + sum(sum(Theta2(:,2:end).^2)));
Backpropagation algorithm
Similarly,to min J(Θ) we need compute J(Θ) and ∂∂Θ(l)ijJ(Θ) .
Gradient computation
Intution: δ(l)j= “error” of node j in layer
l .From δ(L) To δ(2) (No δ(1) ):
δ(L)=a(L)−y
and if we have δ(i) :
δ(i−1)=(Θ(i−1):j)Tδ(i),j≠0
(sl×(sl−1+1)−1)T×(sl×1)=sl−1×1
(where must minus Θ(i−1)0 ) where:
g′(z(i))=g(z)(1−g(z))
and we can get Δ(l) :
Δ(l)=δ(l+1)(a(l))T
(sl+1×1)×((sl+1)×1)T=sl+1×(sl+1)
Then:
D(l)=1mΔ(l)+λΘ(l):j,j≠0
∂∂Θ(l)J(Θ)=D(l)
Implementation note:Unrolling parameters
Example
Θ(1)∈R10×11,Θ(1)∈R10×11,Θ(1)∈R1×11
Unrolling
thetaVec = [Theta1(:);Theta2(:);Theta3(:)];Reshape
Theta1 = reshape(thetaVec(1:110),10,11); Theta2 = reshape(thetaVec(111:220),10,11); Theta1 = reshape(thetaVec(221:231),1,11);
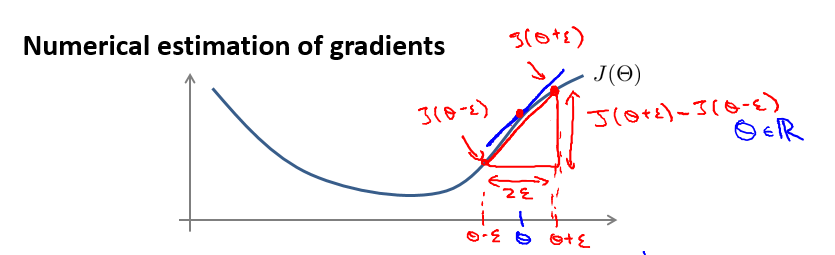
Gradient checking
for i = 1:n, thetaPlus = theta; thetaPlus(i) = thetaPlus(i) + EPSILON; thetaMinus = theta; thetaMinus(i) = thetaMinus(i) – EPSILON; gradApprox(i) = (J(thetaPlus) – J(thetaMinus))/(2*EPSILON); end;Implementation Note:
- Implement backprop to compute DVec (unrolled).
- Implement numerical gradient check to compute gradApprox.
- Make sure they give similar values.
- Turn off gradient checking. Using backprop code for learning.
Important:
- Be sure to disable your gradient checking code before training your classifier. If you run numerical gradient computation on every iteration of gradient descent (or in the inner loop of costFunction(…))your code will be very slow.
Random initialization
If zero initialization:
After each update, parameters corresponding to inputs going into each of two hidden units are identical.So we must random initialization to break symmetry.
Initialize each Θ(l)ij to a random value in [−ϵ,ϵ]
E.g.Theta1 = rand(10,11)*(2*INIT_EPSILON) - INIT_EPSILON; Theta2 = rand(1,11)*(2*INIT_EPSILON) - INIT_EPSILON;
Training a neural network
Pick a network architecture (connectivity pattern between neurons)
- No. of input units: Dimension of features x(i)
- No. output units: Number of classesReasonable default: 1 hidden layer, or if >1 hidden layer, have same no. of hidden units in every layer (usually the more the better)
Steps
- Randomly initialize weights
- Implement forward propagation to get hΘ(x(i)) for any x(i)
- Implement code to compute cost function J(Θ)
- Implement backprop to compute partial derivatives
∂∂Θ(l)ijJ(Θ)
for i = 1:m
Perform forward propagation and backpropagation using example (x(i),y(i))
(Get activations a(l) and delta terms δ(l) for l=2,⋯,L ).- Use gradient checking to compare
∂∂Θ(l)ijJ(Θ)
computed using backpropagation vs. using numerical estimate of gradient of
J(Θ)
.
Then disable gradient checking code. - Use gradient descent or advanced optimization method with backpropagation to try to minimize J(Θ) as a function of parameters Θ
















 1885
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









