







单变量线性回归:
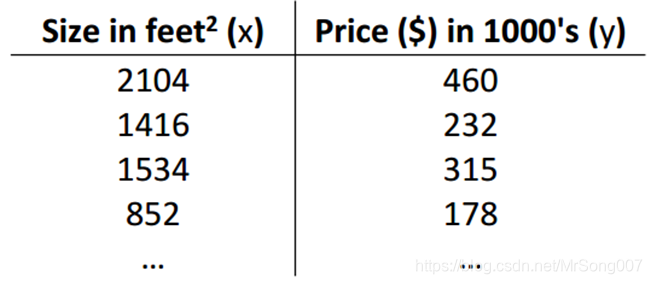
我们有以上数据,这些数据表示的是房屋尺寸(x)和房屋价格(y)的关系, 我们希望从这些数据中找到一个房屋预测模型,当我们给这个模型一个房屋尺寸信息 (x_i) 的时候,该模型能给我们预测一个大概的房屋价格 (y_i)。这就是一个典型的单变量先行回归问题,该问题描述可以用下边的过程来表示:其中 h 是从数据中找出来的房屋模型,又称为“假设”。

假设(hypothesis):
单变量假设通常由以下方程来表示:
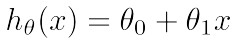
其中theta_0和theta_1 是参数;
在上述房屋预测的例子中, x 是土地尺寸; h_theta(x) 是预测出来的房屋价格;上述假设就是通过已知的大量房屋尺寸和房屋价格的关系找到的,也就是说通过已知的大量房屋尺寸和房屋价格的关系来确定theta_0和theta_1的值。
消耗函数(Cost Function):
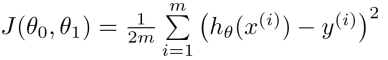
从消耗函数的方程中也可以看出它表示的是”在假设中预测出的房屋价格“与”真实房屋价格“之间差异的程度。消耗函数越小,代表从已知数据中得到的假设能更加准确的描述房屋尺寸与房屋价格之间的关系。(其中m表示的是已知数据对的个数)。消耗函数是参数 theta_0和theta_1 的函数。当我们通过使得消耗函数最小来找到theta_0和theta_1后,此时theta_0和theta_1所描述的假设就是最准确的。
不同的参数值如何影响消耗函数的值
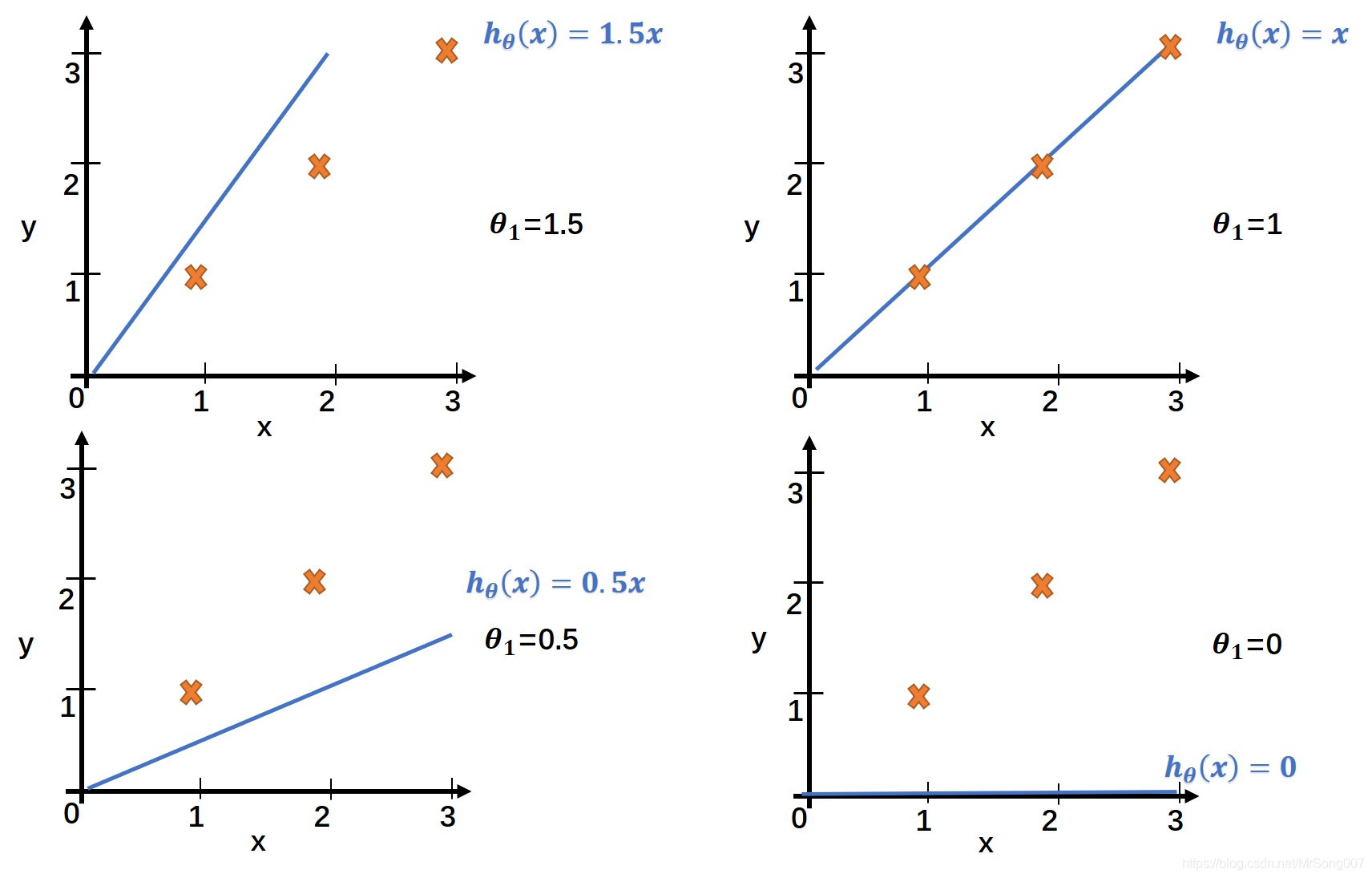
简单考虑只有一个参数的情况,上图中黄色的叉号表示已知的数据,一共3个已知数据,分别是(1,1)(2,2)(3,3),m=3; 蓝色的线表示在当前参数下的假设;那么根据消耗函数公式,我们可以求出在theta_1取不同的值得情况下消耗函数的值,消耗函数的大致变化如下图的凹函数:

上述是一个未知参数的情况,那么两个未知参数的情况大致可以猜测是下图的形式,一个碗状图:
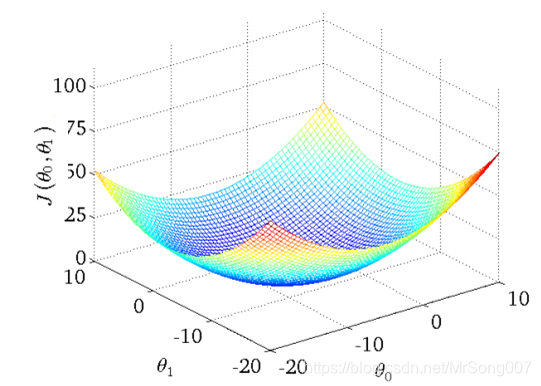
目标(Goal)
经过以上的分析和不同参数值对消耗函数值的影响,目标已经很明确,就是找到使得消耗函数最小化的theta_0和theta_1的值,此时所得到的假设是能够最好地反映已知数据的,即:
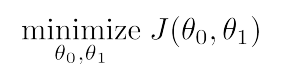
梯度下降
梯度下降策略就是提出来解决上述问题,该策略要满足以下两点:
- 给 theta_0和theta_1 设任意初始值;
- 不断改变theta_0和theta_1 的值来减小消耗函数,直到减小到最小值;
梯度下降过程:
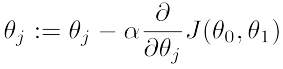
对每个参数按照以上公式同时同步进行更新,直到参数收敛,参数收敛就是前后两次的值不再发生变化(一般设置一个极小的阈值)。其中参数alpha 代表学习率,alpha 的值太小,利用梯度下降策略来使得消耗函数取做小的过程就会太慢;alpha 的值太大,利用梯度下降策略来使得消耗函数取做小的时候会出现消耗函数的值发散的情况;所以取合适的值很重要。














 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









