









大型语言模型 (LLM) 已经占领了商业世界,现在每家公司都在尝试使用生成式人工智能。尽管 ChatGPT 等工具显然功能强大,但尚不清楚企业如何可靠地使用这项技术来推动价值。
对于我接触过的大多数企业来说,“使用 AI ” 意味着构建聊天机器人、副驾驶、AI 代理或 AI 助手。然而,随着人们对这些解决方案最初的热情逐渐消退,组织开始意识到围绕 LLM 构建系统的关键挑战。
这比我想象的要难……
一个核心挑战是 LLM 本质上是不可预测的(甚至比传统的机器学习系统更加不可预测)。因此,让它们可预测地解决特定问题并不容易。
例如,幻觉问题的一个解决方案是让“评判”LLM 审查系统响应的准确性和适当性。然而,增加 LLM 的数量会增加系统的成本、复杂性和不确定性。
解决正确的问题
这并不是说生成式人工智能(及其同类)不值得追求。人工智能已经让无数公司变得非常富有,而且我认为这种情况不会很快停止。
关键在于,价值是通过解决问题产生的,而不是使用人工智能(本身)。当企业确定需要解决的正确问题时,人工智能的前景就会实现,例如 Netflix 的个性化推荐、UPS 的配送路线优化、沃尔玛的库存管理等等。
3 个 AI 销售用例
“解决正确的问题”说起来容易,做起来却不容易。为了帮助大家,我在这里分享了 3 个 AI 用例,用于每个企业都关心的销售问题。我希望激发你的想象力,并通过具体的例子展示如何实现它们。
这三个用例是:
- 特征工程——从文本中提取特征
- 构建非结构化数据——使文本分析做好准备
- 潜在客户评分——识别你最大的机会
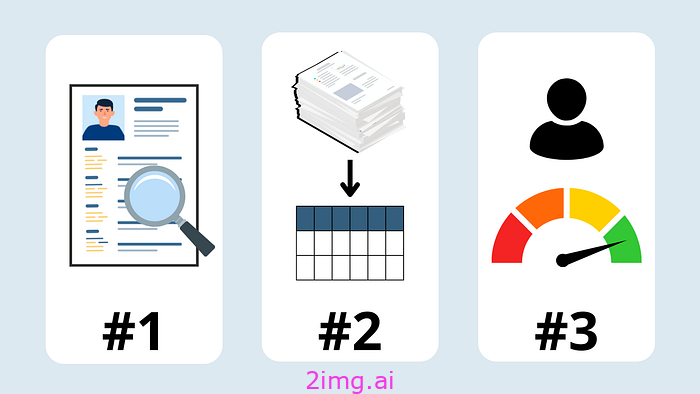
3 个 AI 用例。图片由作者提供。
用例 1:特征工程
特征工程包括创建可用于训练机器学习模型或执行某些分析的变量。例如,给定一组 LinkedIn 个人资料,提取当前职位、工作年限和行业等信息,然后将其以数字形式表示出来。
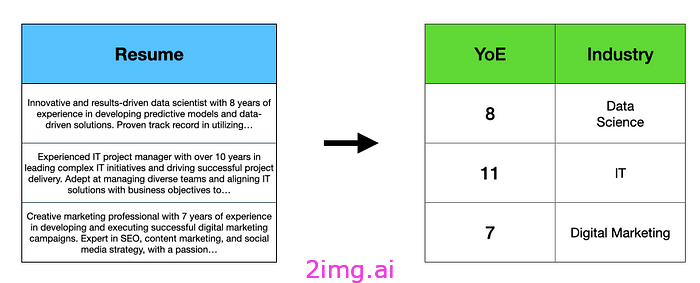
从简历文本中提取多年的经验和行业经验。图片来自作者。
传统上,这通过两种方式实现。1) 手动创建特征,或 2) 从第三方购买特征(例如,来自 FICO 的信用评分、来自 D&B 的公司收入)。然而,大语言模型 (LLM) 创造了第三种方式来实现这一点。
示例:从简历中提取特征
假设您正在为 SaaS 产品寻找潜在客户。该软件有助于保护中型企业免受网络安全威胁。目标客户是 IT 领导者,他们决定哪些供应商适合他们的公司。
您拥有从各种来源收集的 100,000 份专业资料和简历,这些资料和简历基于“IT”、“网络安全”、“领导者”、“副总裁”等标签。但问题是这些潜在客户的质量很低,通常包括非 IT 领导者、入门级 IT 专业人员和其他不符合客户资料的人员。
为了确保销售工作集中于正确的客户,目标是筛选潜在客户,仅包括 IT 领导者。以下是解决此问题的几种方法。
- 想法 1:手动审核所有 100,000 条线索。问题:对于个人或小型销售团队来说不切实际
- 想法 2:编写基于规则的逻辑来筛选简历。问题:简历的格式多种多样,因此逻辑效果不佳。
- 想法 3:向数据供应商支付此信息。问题:这大大增加了客户获取成本(每条线索约 0.10 美元)
鉴于上述想法存在问题,让我们考虑如何使用大型语言模型来解决这个问题。一个简单的策略是制作一个提示,指示 LLM 从简历中提取所需的信息。下面给出了一个例子。
分析从简历中提取的以下文本,并确定此
人是否从事 IT 行业。如果此人不从事 IT
行业,则返回“0”,如果从事 IT 行业,则返回“1”。然后,简要说明
您的结论。
简历文本:
{简历文本}
此解决方案完美融合了上述三个理念。它 (1) 审查每条线索,寻找与个人类似的具体信息;(2) 由计算机程序自动完成;(3) 您支付的费用更少(每条线索约 0.001 美元)。
**奖励**: 对于那些有兴趣实现类似功能的人,我在这里分享了一个示例 Python 脚本,该脚本使用 OpenAI API 从 LinkedIn 个人资料中提取工作年限。
用例 2:构建非结构化数据
电子邮件、支持单、客户评论、社交媒体资料和通话记录中的数据都是非结构化数据的例子。这仅仅意味着它不像 Excel 电子表格或 .csv 文件那样按行和列组织。
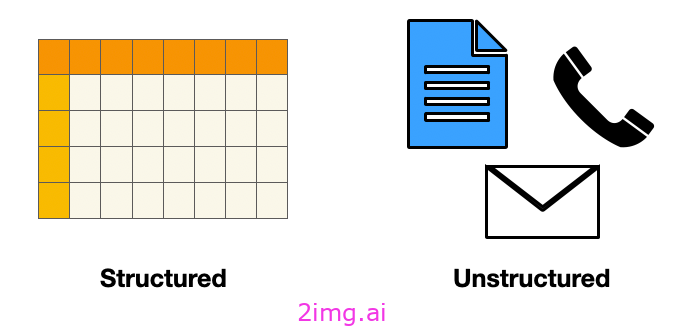
结构化数据与非结构化数据。图片由作者提供。
非结构化数据的问题在于它不具备分析能力,因此很难获得洞察力。这与结构化数据(即按行和列组织的数字)形成对比。将非结构化数据转换为结构化格式是自然语言处理 (NLP) 和深度学习的最新进展可以提供帮助的另一个领域。
示例:将简历翻译成(有意义的)数字
考虑上一个示例中的相同业务案例。假设我们从 100,000 条线索中成功挑选出 10,000 名 IT 领导者。虽然您的销售人员可以开始接听电话并撰写电子邮件,但您首先要看看是否可以提炼列表 以优先考虑 与过去客户相似的线索。
其中一种方法是定义额外的特征,为理想的客户资料提供更精细的粒度(例如,行业、合规性要求、技术堆栈、地理位置),这些特征可以像用例 1 类似地提取。然而,识别这样的指标可能具有挑战性,开发额外的自动化流程需要付出代价。
另一种方法是使用所谓的文本嵌入。文本嵌入只是具有语义意义的文本块的数字表示。可以将其想象成将简历翻译成一组数字。
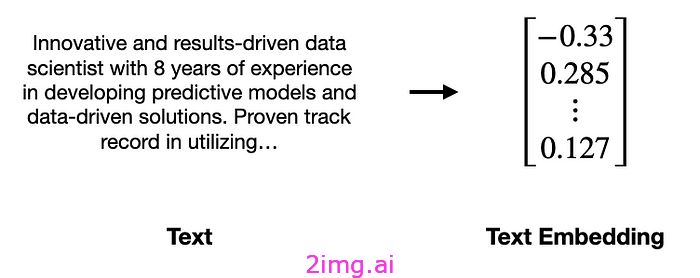
将文本转换为文本嵌入。图片由作者提供。
文本嵌入的价值在于,它们将非结构化文本转换为结构化的数字表,这更适合传统的分析和计算方法。例如,在这种情况下,人们可以使用文本嵌入以数学方式评估哪些潜在客户与过去的客户最相似,哪些潜在客户最不同。
用例 3:潜在客户评分
最后一个用例是潜在客户评分,即根据关键预测因素(例如职位、公司收入、客户行为等)评估潜在客户的质量。虽然这并不是什么新鲜事,但人工智能的最新进展使我们能够更好地解析非结构化数据,这些数据可以输入到潜在客户评分模型中。
示例:根据质量对潜在客户进行评级
为了总结我们正在进行的业务案例,让我们讨论一下如何使用文本嵌入对潜在客户进行优先排序。假设我们有 1,000 个过去的潜在客户列表,其中 500 个购买了产品,500 个没有购买。对于每个潜在客户,我们都有一个个人资料,其中包含关键信息,例如职位、工作经验、当前公司、行业和关键技能。
这些潜在客户可用于训练预测模型,该模型根据客户的个人资料估计客户购买产品的概率。虽然开发这样的模型有很多细微差别,但基本思路是,我们可以使用该模型的预测来定义每个潜在客户的等级(例如 A、B、C、D),这可用于对 10,000 个新潜在客户进行分类和优先排序。
回顾
人工智能为企业带来巨大潜力。然而,要发挥这种潜力,首先需要找到正确的问题,并利用人工智能来解决。
随着 ChatGPT 等工具的普及,解决方案的想法很容易局限于 AI 助手范式。为了帮助扩大可能性空间,我分享了 3 个使用替代方法的实用 AI 用例。
















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











