










OpenAI 刚刚宣布了一种具有令人难以置信的新推理能力的新模型。但事实真是如此吗?
在测试之前,我的第一个问题是让我们问问ChatGPT 4o它是怎么想的:

作者截图
他似乎接受得很好,但最后提出的棘手问题可能表明他对他闪亮的新弟弟有些嫉妒(欢迎加入俱乐部,亲爱的 ChatGPT,即使是人类也不喜欢被告知人工智能比他们更好)
OpenAI 推出新模型犹如晴天霹雳。此前有传言称即将推出的模型价格不菲,但目前 ChatGPT4o1 似乎无需额外付费即可使用。
我们开发了一系列新的人工智能模型,旨在花更多时间思考后再做出反应。它们可以推理复杂的任务,解决比以前的科学、编码和数学模型更难的问题。——来源
显然,这个模型就是著名的草莓模型。现在不是 GPT5,而是经过额外训练的 GPT4。但对于 OpenAI 来说,这代表了类似人类的人工智能的又一步。同时,该模型可以在 ChatGPT-4o1 版本和迷你版本(应该更快)中进行测试。它也可以作为 API 版本使用,但需要额外付费:
开发人员访问 o1 的费用非常昂贵:在 API 中,o1-preview 每 100 万个输入令牌(即模型解析的文本块)收费 15 美元,每 100 万个输出令牌收费 60 美元。相比之下,GPT-4o 每 100 万个输入令牌收费 5 美元,每 100 万个输出令牌收费 15 美元。——来源
尽管价格更贵,但这款机型应该比其前身更好。事实上,它在几乎所有基准测试中都胜过前身。
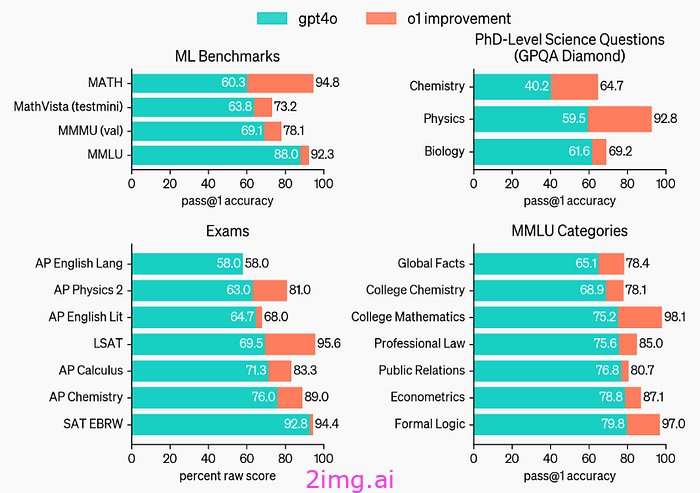
图片来源:这里
令人难以置信的是,它在推理和编码任务中的表现远远优于其前身(这在某种程度上是必要的,因为Claude 3 在编码方面比 GPT4 更好)。
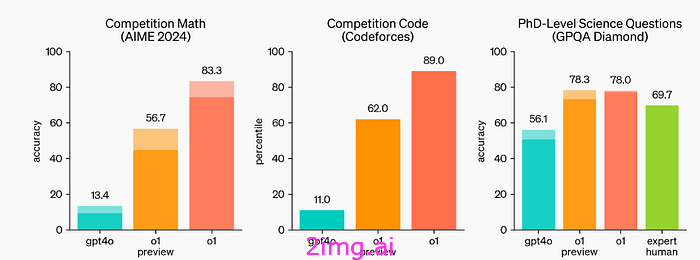
图片来源:这里
此外,该模型还可以解决逻辑难题、数学问题等。
据作者介绍,该模型在执行规划任务时具有非凡的能力。例如,之前的模型在国际数学奥林匹克资格考试中得分为 13%,而新模型得分达到 89%。此外,在物理、生物和化学任务方面,它的表现应该与博士生相当。一个引人注目的细节是,该模型能够计算单词“strawberry”中 R 的数量(由于标记化,以前的LLM未能完成这项乍一看似乎微不足道的任务)。
“需要明确的是,o1-preview 并不是在所有方面都做得更好。例如,它并不是比 GPT-4o 更好的作家。但对于需要规划的任务,变化相当大。” —来源

作者截图
我在 ChatGPT 4th 上告诉了他,他以惯常的外交方式回应,但实际上我真的认为他很高兴。
我们的大规模强化学习算法在高度数据高效的训练过程中教会模型如何使用思路链进行有效思考。 —来源
作者截图
总的来说,这个模型是 ChatGPT 加上RHLF 的增强版。作者在专有数据集上使用了与创建 ChatGPT 相同的算法(或至少是更高级的版本)。他们似乎收集了大量数学问题和编码的思路,以提高模型的推理能力。简而言之,他们花费了大量资源招募程序员并创建这些 CoT(如何解决问题的解释),然后他们在此基础上训练模型。
现在 OpenAI 非常擅长营销,他们一直在谈论这个神秘的新Q*算法,据说它能让模型具备推理能力。显然,它被认为是对人类的威胁,但到目前为止似乎并非如此
其实,在描述这些模型时,是否应该谈及推理和思考,已经引起了热烈的讨论。HuggingFace 的 CEO 说得好:
再次强调,人工智能系统不是在“思考”,而是在“处理”、“预测”……就像谷歌或计算机一样。给人一种技术系统是人类的错误印象,这只是廉价的骗术和营销手段,让你误以为它比实际更聪明。——来源
关于推理的真正含义,人们总是争论不休,这又是另外一回事。然而,谈论推理是不恰当的;归根结底,在这个光鲜亮丽的模型背后,总有一个无法推理的老式变压器。
但到底这种模式真的对人类构成威胁吗?
不,我认为完全不是。就我个人而言,我发现它比它的前身更令人沮丧。一段时间以来,人们一直怀疑基准测试的真实有效性以及 LLM 在编码方面的实际表现。
根据我的经验,这种模型速度较慢,而且似乎做了很多不必要的步骤(你看不到推理的中间体,尽管它确实宣布它正在做某事,就好像它是一个老式的加载栏一样)。

作者截图
我们无法知道它是否真的在执行这些推理步骤,或者它们只是让模型看起来像在做某事的一种方式。无论哪种方式,它都会时不时地崩溃,你必须让它重新生成。为了测试它,我让它解决一个连它的前身都无法完成的简单任务:“给定一个科学摘要,使用 huggingface 模型来识别实体并提取它们。然后,我想绘制文本并用不同的颜色突出显示提取的实体。给出 Python 代码。 ”

作者截图
经过几次尝试,它还是像前身一样失败了。经过了这么多推理,却找不到正确的模型。我给了他正确的模型,但他却用错了。
“我们花了好几个月研究推理,因为我们认为这实际上是一个关键的突破,”McGrew 说。“从根本上说,这是一种新的模型模式,能够解决真正困难的问题,从而达到类似人类的智能水平。”——来源
在我看来,此刻的他就像一个表情很痛苦、假装在思考问题的解决方案,但最终却给出了错误答案的学生。
OpenAI 表示,由于采用了这种新的训练方法,该模型应该会更加准确。Tworek 说:“我们注意到这个模型的幻觉减少了。”但问题仍然存在。“我们不能说我们解决了幻觉问题。”——来源
幻觉是 LLM 的主要问题之一。事实上,这是在金融和医学等敏感领域使用这些模型的主要限制之一。这也是 RAG 或 GraphRAG 等系统发展的原因。
总而言之,这个模型在推理和编码方面明显优于前一个模型(至少在基准测试中如此)。同时,它的编写速度比前一个模型更差,因此不应将其用于所有任务。神秘的 Strawberry 最终在精选的数据集上与 GPT4 对齐,其中不仅存在问题和解决方案,而且还有解决问题的推理。该模型继续产生幻觉。因此,它是其前身的更好版本,当然是一个有趣的模型,但它也不会取代人类(当我要求它解决编码问题时,它会继续让我感到沮丧)。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











