









现状
在工作中难免会使用数据库,为了能够高效并发访问数据库,数据库连接池必不可少,由于本站copy模式盛行,导致数据库连接池被错误使用,遇到错误甚至追求能跑通就行。
本文就python版本的数据库链接池模块在实际使用场景样例,来说明如何正确合理的使用数据库连接池。
业务场景
在部署机器学习模型时采用的是flask框架,模型预测本身是一个很快的事情,无奈有太多的特征需要通过接口(或者是ots,mysql等)获取,导致响应时效性降低。
为了能很好的实现并发性,提升QPS,采用gunicorn进行多进程,异步处理方案。
此时单个进程只有一个数据库链接,就会导致异步执行的线程共用同一个连接,从而导致报错,引入数据库连接池是必须的。
数据库连接池原理
通过预先建立链接,放到然后list中,使用的时候,从list中取出一个链接,使用使用完成后归还连接。当线程太多,链接池中没有链接的时候,可以选择block,等到有链接可用的时候返回,或者是直接返回错误。
dbutils已经实现了两种pooldb:
PooledDB :可以被多线程共享的链接,适用于异步场景,不断有新线程进来获取连接池,本文使用该方案。
PersistentDB:下面这句话表示,对线程的要求是持续稳定的,不能产生新的线程。 Measures are taken to make the database connections thread-affine. This means the same thread always uses the same cached connection, and no other thread will use it. So even if the underlying DB-API module is not thread-safe at the connection level this will be no problem here. For best performance, the application server should keep threads persistent.
dbutils结构如下
db结尾的是mysql等数据库专用。
pg结尾的是PostgreSQL专用。
如上交代完之后,相信你对数据库链接池有较为全面的认知了,好了具体实现代码如下:
主要代码框架逻辑:
1、初始化连接池
2、获取链接
3、查询数据库
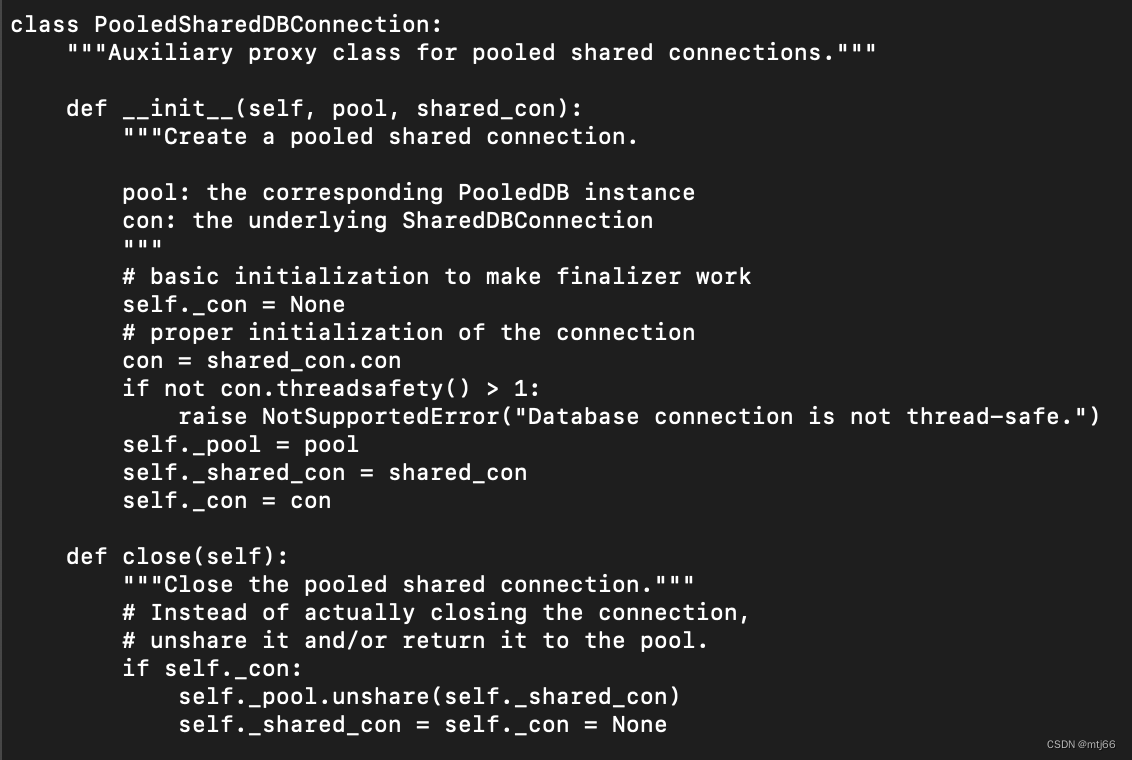
4、close链接(返回给连接池,并不是真正的关闭连接池,参见PooledSharedDBConnection.close方法)
5、具体数据查询&解析逻辑根据业务修改,此处提供了sql_fetch_json函数,返回json格式数据。
6、test1为多线程测试,此处自己多运行体会查询结果。
# coding=utf-8
import random
import threading
from dbutils.pooled_db import PooledDB
from dbutils.persistent_db import PersistentDB
import time
import pymysql
from configuration.config import system_logger, db_config
class MysqlHelper(object):
def __init__(self, db_config):
self.__pool = PooledDB(creator=pymysql,
mincached=1,
maxcached=5,
maxshared=5,
maxconnections=5,
maxusage=5,
blocking=True,
user=db_config.get('user'),
passwd=db_config.get('password'),
db=db_config.get('database'),
host=db_config.get('host'),
port=db_config.get('port'),
charset=db_config.get('charset'),
)
def getConn(self):
conn = self.__pool.connection() # 从连接池获取一个链接
cursor = conn.cursor()
return conn, cursor
@staticmethod
def dispose(cursor, conn):
cursor.close()
conn.close()
def getOne(self, sql):
conn, cursor = self.getConn()
th_name = threading.currentThread().getName()
# print(f'{th_name} {self.conn} {self.cursor} {time.time():.4f} start {sql}')
cursor.execute(sql)
rows = cursor.fetchall()
print(f"{th_name} {conn} {cursor} {time.time():.4f} {rows}")
# self.dispose()
self.dispose(cursor, conn)
return rows
def queryOne(self, sql):
system_logger.info("----------------------sql start ----------------------")
system_logger.info(sql)
try:
conn, cursor = self.getConn()
result = cursor.execute(sql)
# rows = cursor.fetchall()
json_data = self.sql_fetch_json(cursor)
# 将连接返回
self.dispose(cursor, conn)
system_logger.info(f"-----------------------queryByKey result:{result} " + str(json_data))
if len(json_data) == 1:
return json_data[0]
return None
except Exception as e:
system_logger.info("-----------predict exception line: " + str(e.__traceback__.tb_lineno) + " of " +
e.__traceback__.tb_frame.f_globals["__file__"])
system_logger.info(e)
return None
@staticmethod
def sql_fetch_json(cursor: pymysql.cursors.Cursor):
""" Convert the pymysql SELECT result to json format """
keys = []
for column in cursor.description:
keys.append(column[0])
key_number = len(keys)
json_data = []
for row in cursor.fetchall():
item = dict()
for q in range(key_number):
item[keys[q]] = row[q]
json_data.append(item)
return json_data
def test1(pool):
phone_no = f"1390709000{random.randint(6,7)}"
strsql = f"select * from zy_phone where policy_holder_phone_no={phone_no} order by insure_date " \
+ "desc, kafka_etl_time asc limit 1 "
while True:
time.sleep(1)
pool.getOne(strsql)
# time.sleep(0.001)
j = 0
th_name = threading.currentThread().getName()
# if th_name in ['Thread-2','Thread-5']:
# # print(f"task {th_name}")
# time.sleep(0.003)
def main(pool):
# pool.getConn()
ths = []
for i in range(5):
th = threading.Thread(target=test1, args=(pool,))
ths.append(th)
for th in ths:
th.start()
for th in ths:
th.join()
if __name__ == "__main__":
mysqlhelper = MysqlHelper(db_config)
main(mysqlhelper)
time.sleep(3)
while True:
time.sleep(1)常见错误使用方法1:
def getConn(self):
self.conn = self.__pool.connection()
self.cursor = self.conn.cursor()
此处不应该共享链接,和cursor,会导致报错:
AttributeError: 'NoneType' object has no attribute 'read'
或者:
AttributeError: 'NoneType' object has no attribute ‘settimeout‘
常见错误使用方法2:
获取链接以及查询的时候加锁
lock.acquire() pool.getConn() pool.getOne(strsql) lock.release() time.sleep(1)
因为pooldb本身就会加锁,参见如下源码中,自己在从链接池获取链接,到cursor获取数据的时候加锁,会导致锁冗余,此时连接池会退化成单个数据库链接。
self.__pool.connection() 逻辑如下:
def connection(self, shareable=True):
"""Get a steady, cached DB-API 2 connection from the pool.
If shareable is set and the underlying DB-API 2 allows it,
then the connection may be shared with other threads.
"""
if shareable and self._maxshared:
with self._lock:
while (not self._shared_cache and self._maxconnections
and self._connections >= self._maxconnections):
self._wait_lock()
if len(self._shared_cache) < self._maxshared:
# shared cache is not full, get a dedicated connection
try: # first try to get it from the idle cache
con = self._idle_cache.pop(0)
except IndexError: # else get a fresh connection
con = self.steady_connection()
else:
con._ping_check() # check this connection
con = SharedDBConnection(con)
self._connections += 1
else: # shared cache full or no more connections allowed
self._shared_cache.sort() # least shared connection first
con = self._shared_cache.pop(0) # get it
while con.con._transaction:
# do not share connections which are in a transaction
self._shared_cache.insert(0, con)
self._wait_lock()
self._shared_cache.sort()
con = self._shared_cache.pop(0)
con.con._ping_check() # check the underlying connection
con.share() # increase share of this connection
# put the connection (back) into the shared cache
self._shared_cache.append(con)
self._lock.notify()
con = PooledSharedDBConnection(self, con)
else: # try to get a dedicated connection
with self._lock:
while (self._maxconnections
and self._connections >= self._maxconnections):
self._wait_lock()
# connection limit not reached, get a dedicated connection
try: # first try to get it from the idle cache
con = self._idle_cache.pop(0)
except IndexError: # else get a fresh connection
con = self.steady_connection()
else:
con._ping_check() # check connection
con = PooledDedicatedDBConnection(self, con)
self._connections += 1
return con
到此本文结束,如果觉得有收获,就点个赞吧。
















 1008
1008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











