







本节主要通过两个项目,利用Python进行实际应用,具体可参考以下目录
目录
项目一:将Excel中的内容自动添置Word文档
1. 依据目标确定待使用工具
利用Pandas对Excel进行处理,那利用??对Word进行处理呢(网上搜索)
答案:借助Python-docx这个第三方包进行管理
(1)安装第三方包
#控制台输入该命令,进行安装(用了清华镜像,速度可以UP)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx(2)官网复制,运行提供的样例代码
官网地址:python-docx — python-docx 1.1.0 文档
其中将该句代码注释或删除(因为没有这张图片,运行会报错)
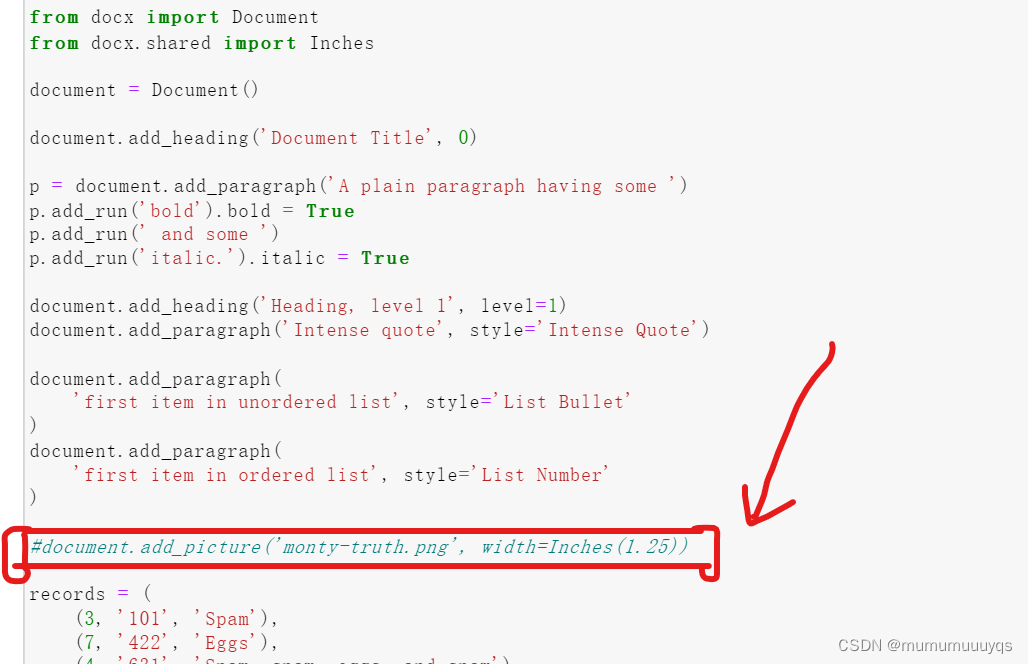
执行后,文件夹就多了一个demo.docx文档

(3)模拟练习
简易版练习
通过人为简易版输出
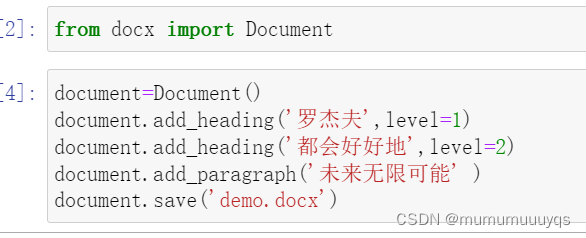
进阶版练习
借用for循环
#1.需要用到Pandas,先导入
import pandas as pd
#2. 将需要用到的表格进行读入,并进行数据读取和处理
video_list=pd.read_excel('video_list.xlsx')
speech_list=pd.read_excel('speech_text.xlsx')
video_list['AwemeId']=video_list['AwemeId'].astype(str)
speech_list['VideoId']=speech_list['VideoId'].astype(str)
#3. 两个表进行合并
merge=pd.merge(video_list,speech_list,how='inner',left_on='AwemeId',right_on='VideoId')
merge#4. 循环访问每一条数据
document=Document() #该句一定要加,否则会延续之前的内容
for i in range(len(merge)):
print(merge.iloc[i]['品牌'])
document.add_heading(merge.iloc[i]['品牌'],level=1)
document.add_heading(merge.iloc[i]['视频标题'],level=2)
document.add_paragraph(merge.iloc[i]['视频文案'] )
document.save('demo.docx')
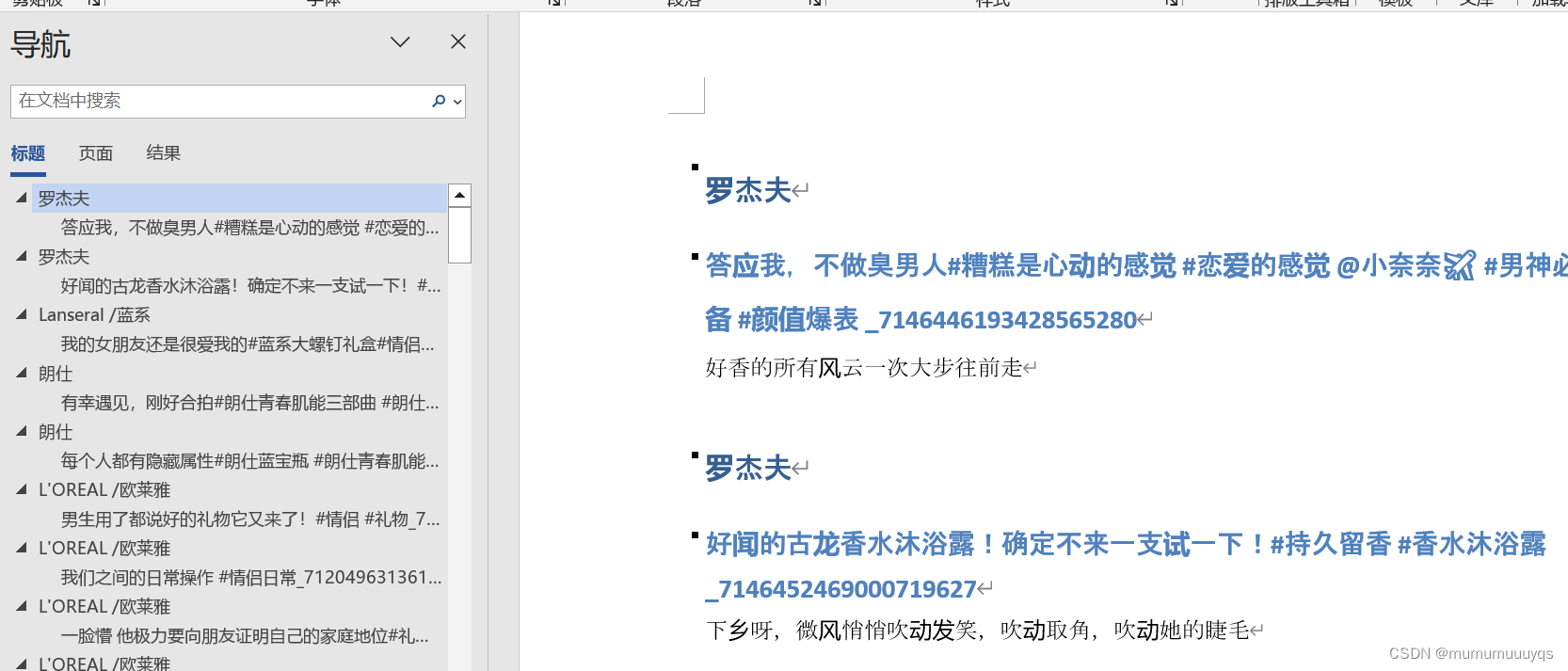
展示结果:
再进阶版
#5.让相同品牌名只出现一次
document=Document() #该句一定要加,否则会延续之前的内容
for i in range(len(merge)):
if merge.iloc[i]['品牌']!=merge.iloc[i-1]['品牌']or i==0: #判断让同品牌名只出现一次
document.add_heading(merge.iloc[i]['品牌'],level=1)
document.add_heading(merge.iloc[i]['视频标题'],level=2)
document.add_paragraph(f'达人昵称:{merge.iloc[i]["BloggerName"]}' )#补充新内容
document.add_paragraph(f'视频地址:douyin.com/video/{merge.iloc[i]["AwemeId"]}' )
document.add_paragraph(merge.iloc[i]['视频文案'] )
document.save('demo.docx')项目二:视频弹幕数据分析
循环读取Excel
#循环读取列表的文件,简化工作流程
import os
excel_list=[]
for item in os.listdir('./'):
if 'xlsx'in item and 'user_level'not in item:
excel_list.append(item)
excel_list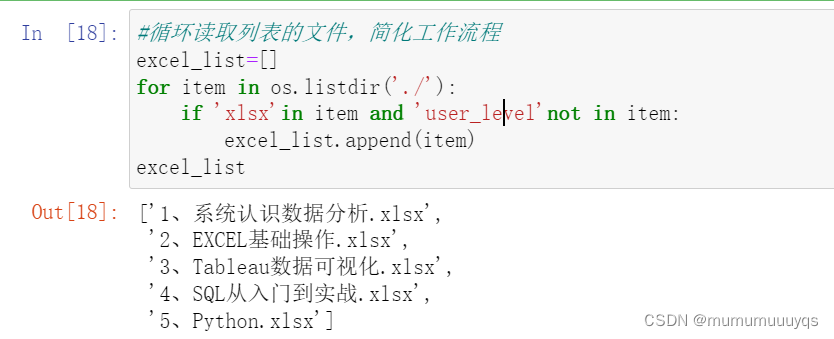
danmu=pd.DataFrame()
for item in excel_list:
excel=pd.read_excel(item,converters={'uid':str,'id':str})#利用converters指定读取结果
excel['视频标题']=item#增加一列来记录每条记录来自哪个视频
danmu=pd.concat([danmu,excel],axis=0)
danmu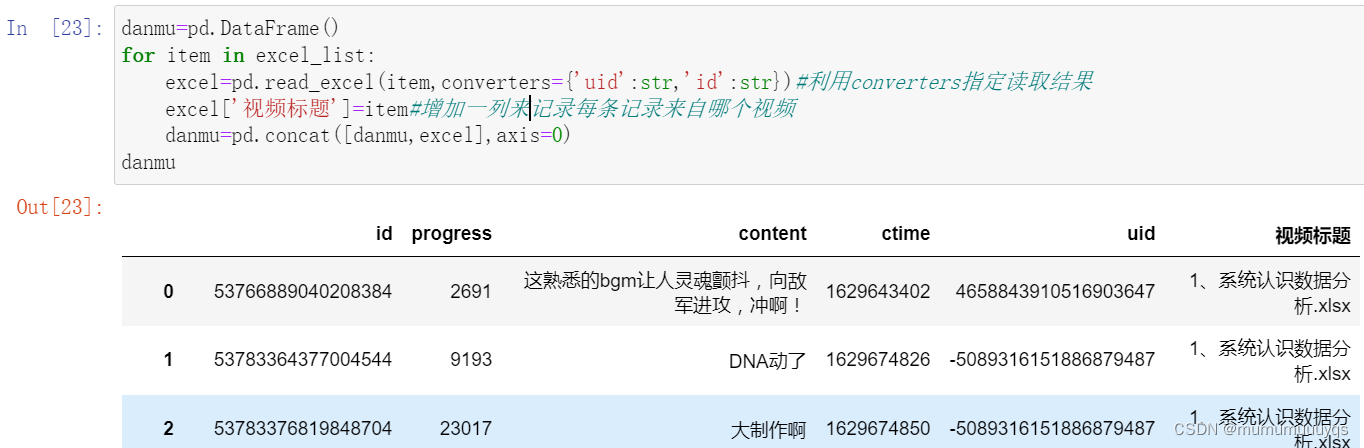
时间处理
#时间处理
from datetime import datetime
#新建一列,其为弹幕存储时间
danmu['弹幕创建时间']=danmu['ctime'].map(datetime.fromtimestamp)
#取出每一个属性对应时间的年,月,以及计算出星期
danmu['年']=danmu['弹幕创建时间'].map(lambda x:x.year)
danmu['月份']=danmu['弹幕创建时间'].map(lambda x:x.month)
danmu 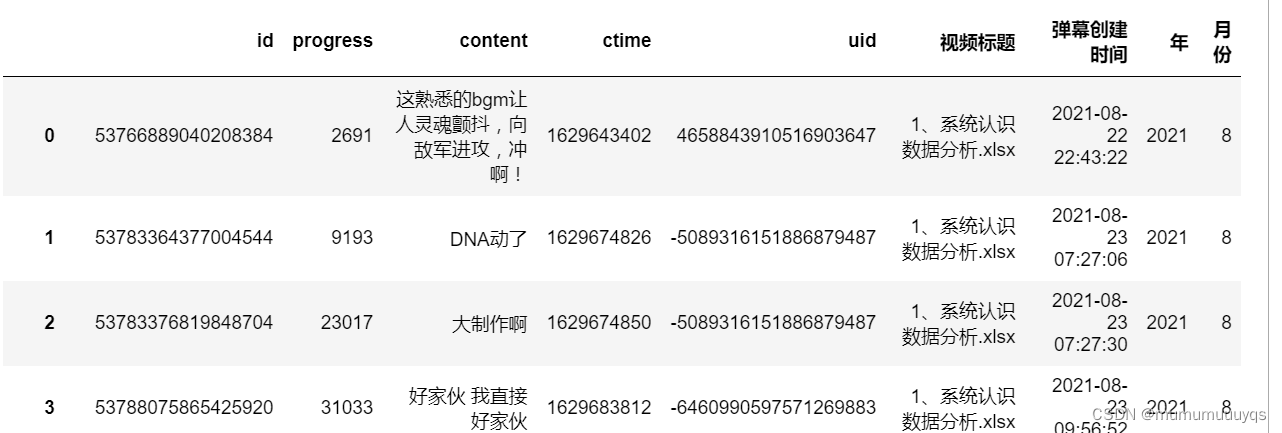
由于原数据没有直接点名星期,故需要一定的转换
danmu['星期']=danmu['弹幕创建时间'].map(datetime.isoweekday)
danmu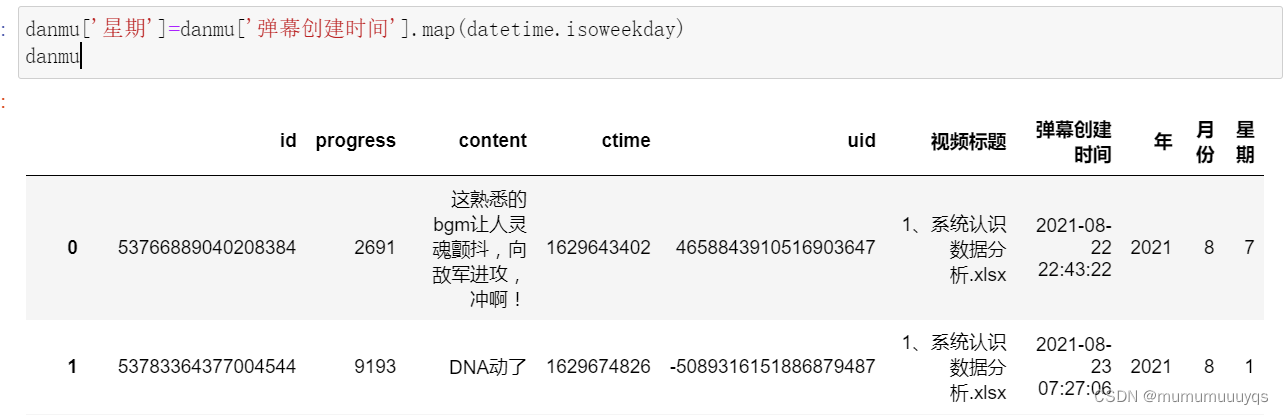
#导入该包,使其能够正常显示中文
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']按照月份分析
#将22年的弹幕都取出来
danmu_year=danmu[danmu['年']==2022]
danmu_year#按月份进行分组,并对id进行聚合,且通过折线图展示出来
danmu_year.groupby('月份')[['id']].count().plot() 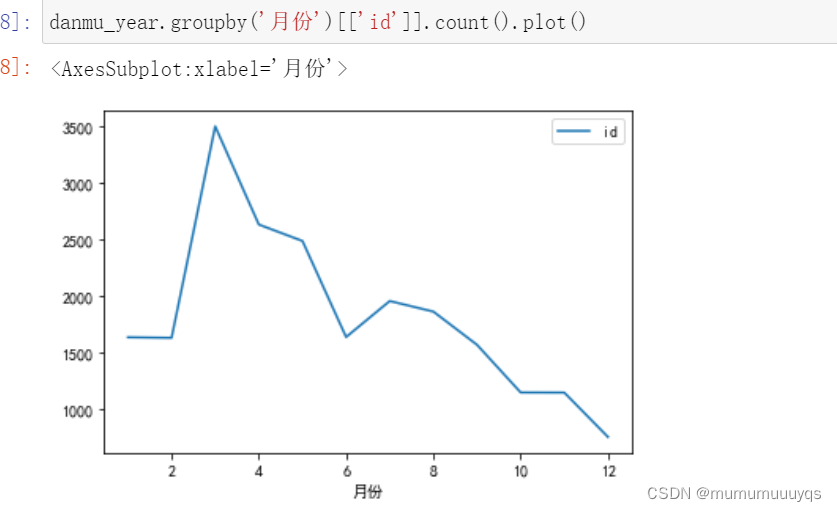
#按月份分组,nunique保证每个uid只计算一次
danmu_year.groupby('月份')[['uid']].nunique().plot() 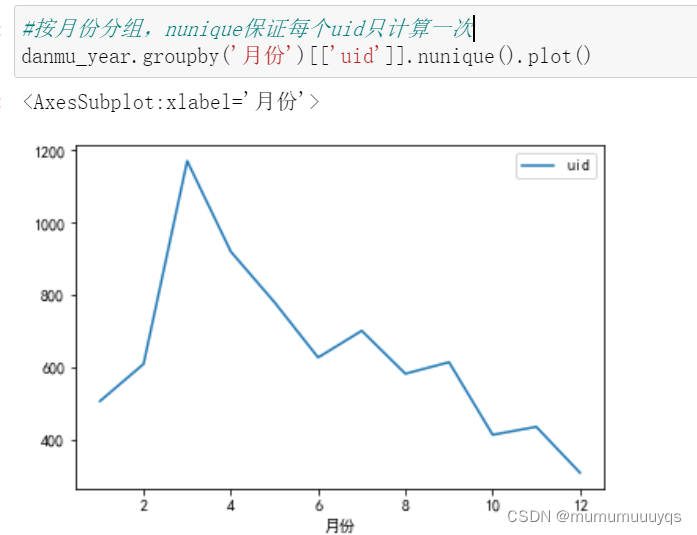
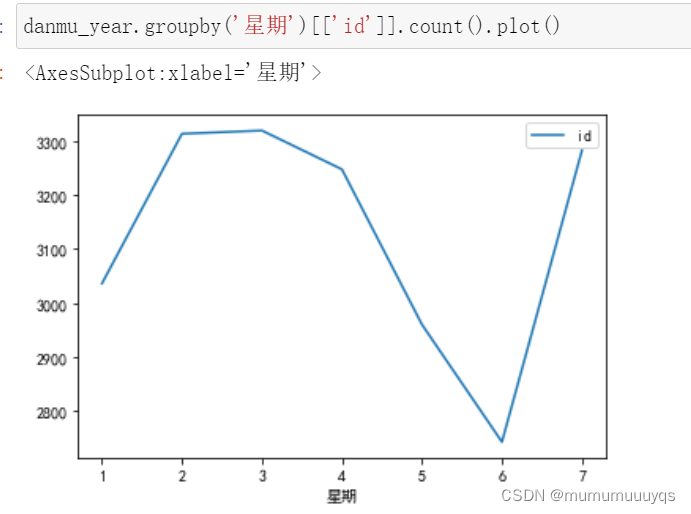
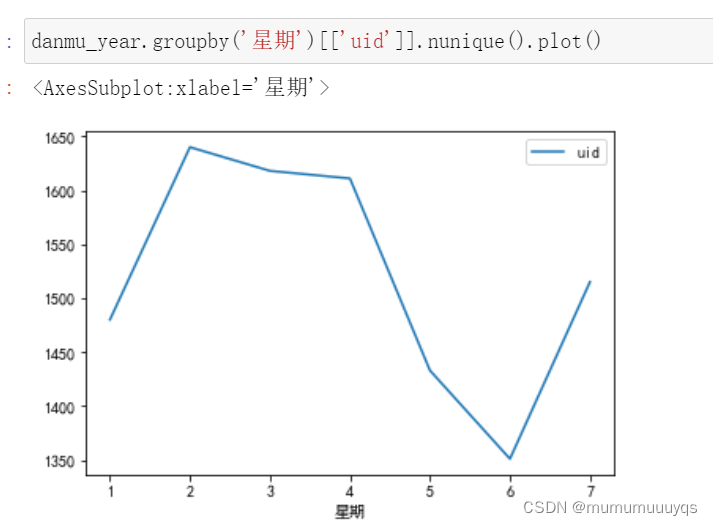
按照星期分析
大部分细节代码同上
#利用pyg做一些复杂的图
import pygwalker as pyg
pyg.walk(danmu_year)
用户画像
#新增一列,记录每个uid所发的弹幕数
danmu['用户弹幕数']=danmu.groupby('uid')['id'].transform('count')在连接前,查看两张表的连接键,其类型是否一致
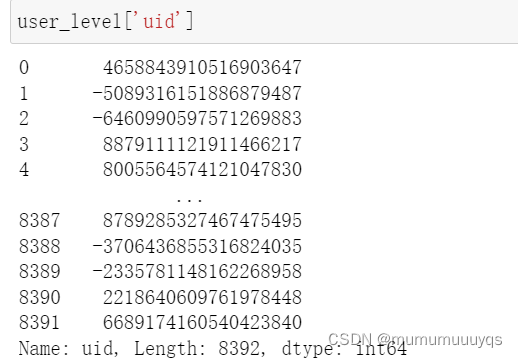
#统一连接键数据类型
user_level['uid']=user_level['uid'].astype(str)
#以uid为关键字,进行两表连接
danmu_level=pd.merge(danmu,user_level,on='uid',how='inner')
danmu_level
弹幕内容
Question:如何查看每个用户发了多少弹幕,并且可按数量进行降序排序
#按uid进行分租,统计每个id的数量,并按该数量进行降序排列
danmu_level.groupby('uid')[['id']].count().sort_values('id',ascending=False)
#查看发弹幕最多的这个人都发了什么弹幕
pd.set_option('display.max_rows',300) #设置DataFrame展示的最大行数为300
danmu_level[danmu_level['uid']=='6653485828143602809']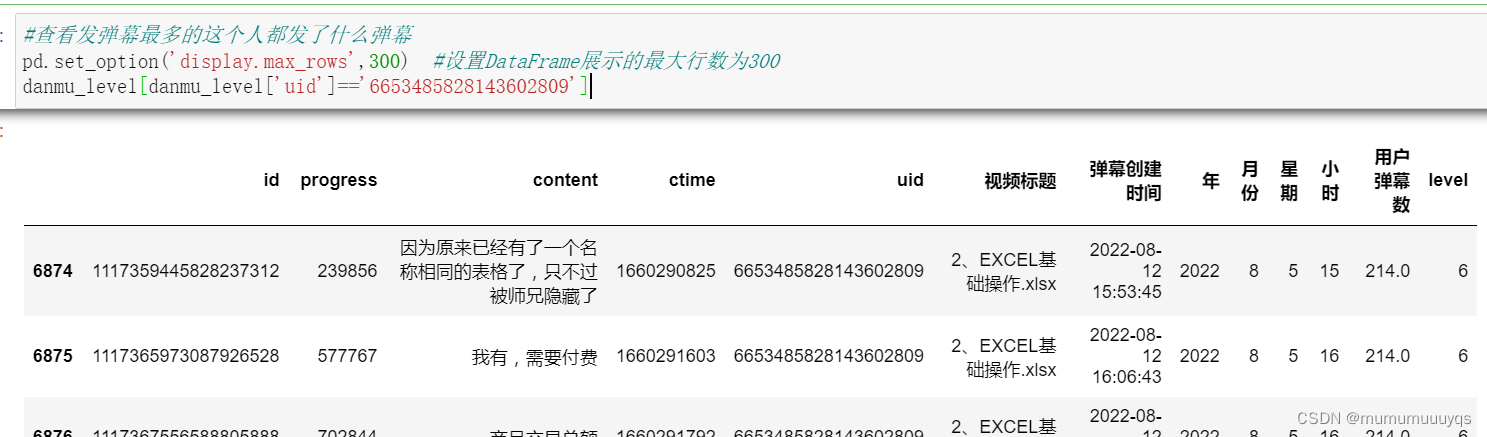
等级分布
danmu_level.groupby('level')[['uid']].count().plot(kind='bar')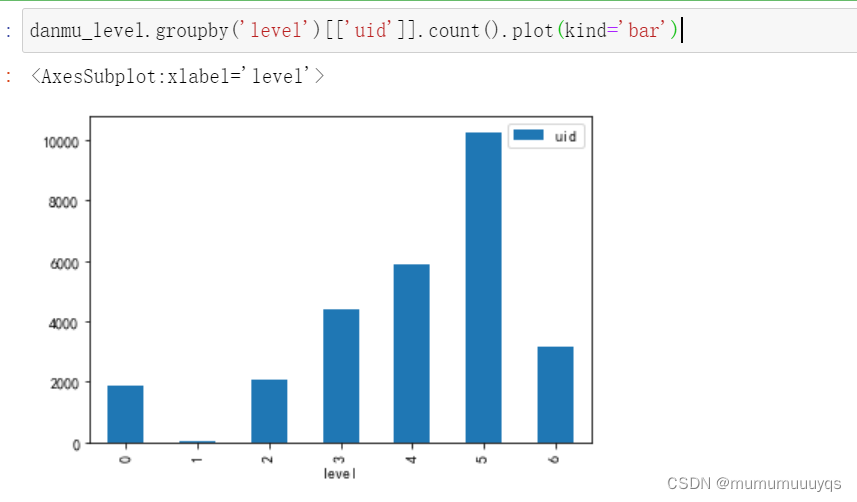
视频内容
1. 视频内容处理(将progress中的毫秒转换为秒的形式)
#引入两个相关的包
from time import strftime
from time import gmtime
danmu['progress']=danmu['progress']/1000
danmu['视频进度']=danmu['progress'].map(lambda x:strftime('%H:%M:%S',gmtime(x)))
danmu['视频进度']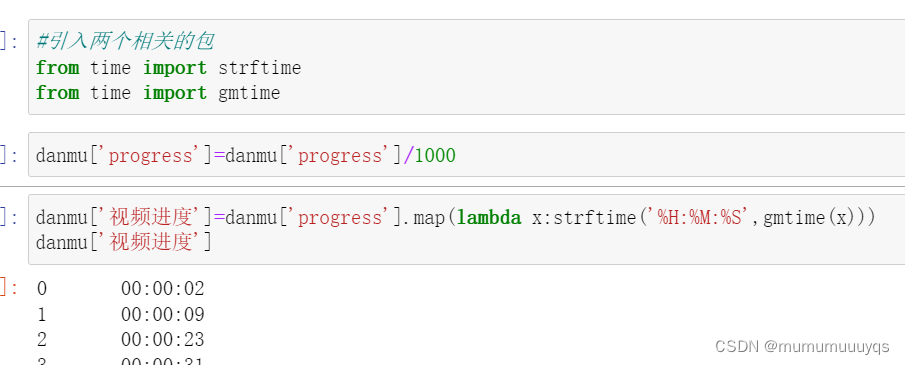
#将时分但拎出来
danmu['视频进度【时分】']=danmu['视频进度'].str[:5]
danmu
2. 开始分析啦
#把p1挑出来
p1=danmu[danmu['视频标题']=='1、系统认识数据分析.xlsx']
#按视频进度【时分】分组,并计算对应的id数量,且按降序排列
p1.groupby('视频进度【时分】')[['id']].count().sort_values('id',ascending=False)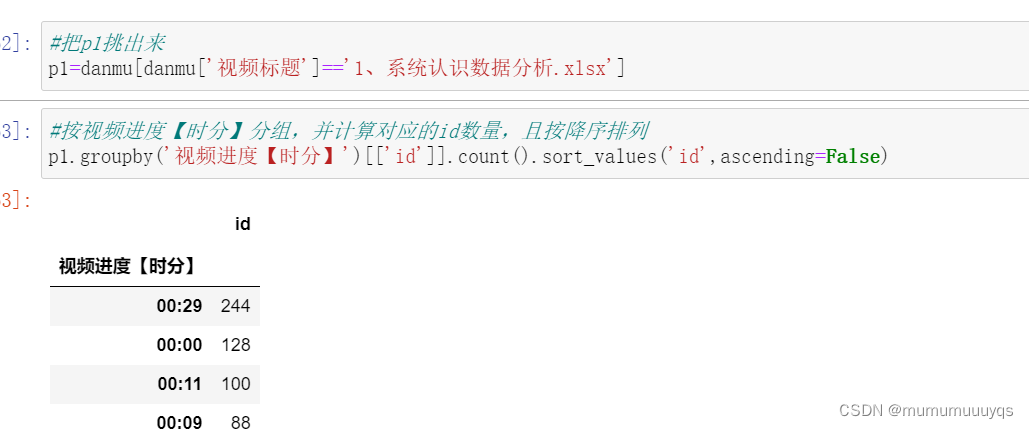
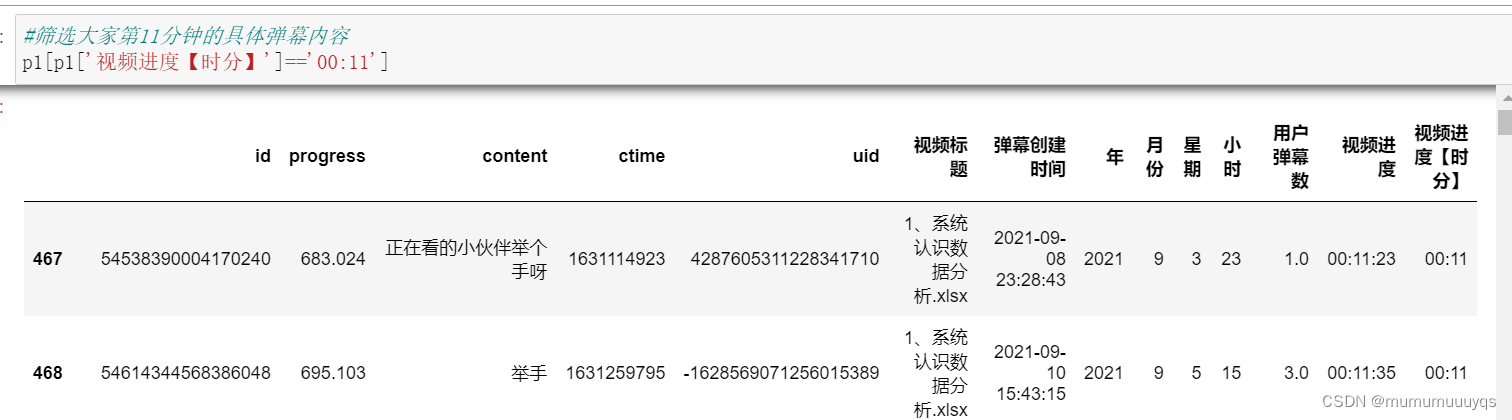















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









