 DeepSeek-V3核心技术与低成本训练揭秘
DeepSeek-V3核心技术与低成本训练揭秘





DeepSeek的核心技术探索
关于DeepSeek公司及其大模型
公司介绍
DeepSeek 2023年7月成立于杭州,是幻方量化旗下的子公司,全称是杭州深度求索人工智能基础技术研究有限公司。
“成立时间才一年多”、“最近推出的V3已经能和OpenAI的4o(名称中"o"代表Omni,即全能的意思,凸显了其多功能的特性。)媲美”、“训练成本不到600W美元”、“API定价仅是国内其它头部厂商几十分之一”、“APP已经在中美APP store登上免费应用榜首”;
以上是最近关于DeekSeek的一些新闻热点信息,下面我们从官网看一下:
DeepSeek近半年相继推出了3个主要的大模型版本,分别是DeepSeek V2.5、DeepSeek V3、DeepSeek-R1(全部都使用了MOE架构)。在这之前还推出了DeepSeek-VL、DeepSeek Coder、DeepSeek Math。
模型能力
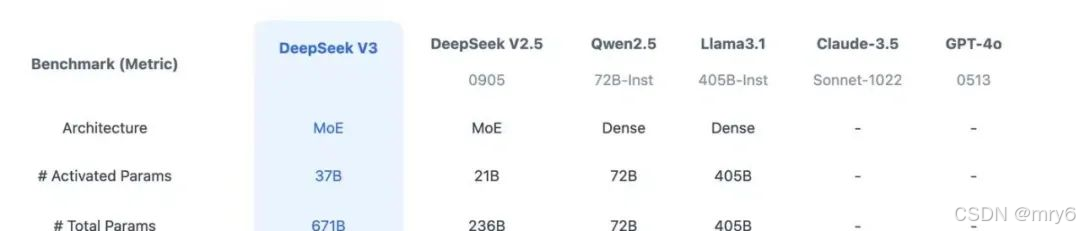
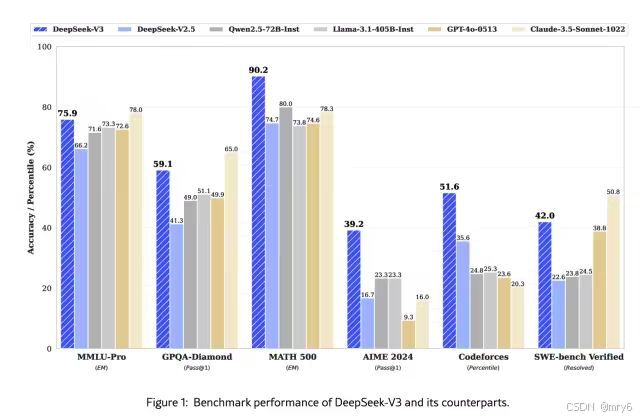
DeepSeek模型已经对标国内Qwen(通义大模型)、海外Lanma、GPT 4o,从公布的榜单评测上看:DeepSeek-V3在开源模型中位列榜首,与世界上先进的闭源模型不分伯仲
成本
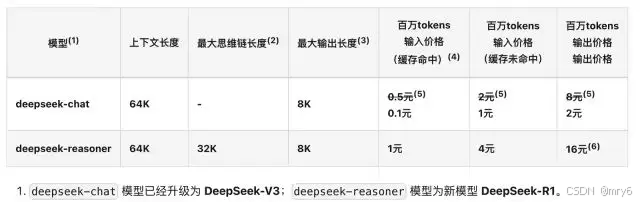
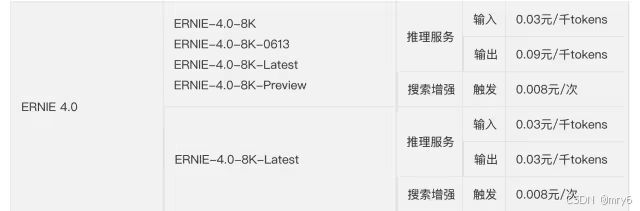
推理成本(API报价):百万Token输入价格能达到1元。
训练成本:从技术报告中看DeepSeek用的是H800的GPU做的训练,而且只有2千张左右的H800,整个V3的正式训练成本不超过600W美元。
1、预训练阶段,每万亿的Token训练V3使用2048个H800GPU集群,只需要180K 个H800 GPU小时,大概3.7天(180000/2048/24)。
2、整个预训练总耗时2664K GPU小时 (不到2个月),加上 上下文扩展和后训练,总耗时大概2788KGPU耗时。
3、按照H800 每小时2美元租赁,总的训练成本不超过600W美元。

这么低的推理和训练成本不由引出以下的问题:
- 模型采用了什么样的网络架构?
- 训练的精度、框架和并行策略是怎样的?
- 模型的部署和优化方案是怎样的?
- 在硬件层的计算和通信上做了什么优化?
DeepSeek训推核心技术
DeepSeek-V3模型网络架构
DeepSeek-V3整体预训练用了14.8万亿的高质量Token,并且在后期做了SFT和RL,模型参数量达到671B,但是每个Token仅激活37B参数。为了做到高效的推理和训练,DeepSeek-V3自研了MLA注意力机制和无辅助损失负载均衡策略的MOE架构。
从技术报告中看出,是经典的Transformer架构,毕竟亮眼的就是前馈网络使用的DeepSeekMoE架构、Attention机制使用MLA架构,其实这两个在DeepSeek-V2模型已经被验证使用过。
与DeepSeek-V2相比,DeepSeek-V3额外引入了一种无辅助损失的负载均衡策略
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









