







1. 引言
算法的适用性和性能取决于某些常规计算的完成速度。如,在椭圆曲线密码学中,需要计算公钥: k × g = g + g + g + . . . . + g k\times g=g+g+g+....+g k×g=g+g+g+....+g,其中 k k k 是一个非常大的整数(通常为一百位左右的数字),且 g g g 是椭圆曲线上的一个点 ( x , y ) (x,y) (x,y),可称其为generator生成元。
如果直观计算,即重复对 g g g 做加法,则需要约 1 0 100 10^{100} 10100 次运算(称该算法运算复杂度为 O ( n ) \mathcal{O}(n) O(n)),即表明运算次数(达到某个常数因子)随着 k k k 呈线性增长。
当前(2023年)最快的超级计算机的性能低于:每秒进行 1 0 18 10^{18} 1018 次浮点运算,这意味着进行一次直观计算会花很长时间。
尽管如此,现在每天都在进行此类计算或相关计算,这要归功于更快算法的开发,如通过重复加法来减少运算时间—— g + g = 2 g , 2 g + 2 g = 4 g g+g=2g,2g+2g=4g g+g=2g,2g+2g=4g等等,从而将计算次数降低为 O ( log n ) \mathcal{O}(\log n) O(logn),即由 1 0 100 10^{100} 10100次运算,降低为了 100 × log 2 10 100\times\log_2 10 100×log210 次。
zk-SNARK(zero-knowledge succinct non-interactive arguments of knowledge,零知识简洁非交互式知识论证)是重要的密码学原语,它允许一方(证明者)说服另一方(验证者)某个陈述是真实的,而无需透露除该陈述的有效性之外的任何其他信息。
zk-SNARK 的应用范围很广,因为它们有可能成为新形式治理、数据共享和金融系统的基础。如:
- 用户可以将困难的计算委托给不受信任的一方,并获得一个证明,该证明允许用户验证计算的完整性,而无需重新运行所有内容。
关键是证明是简洁的,因此可以在数百毫秒的量级内进行验证,而不是执行整个计算。该构造依赖于将计算转换为多项式并检查多项式的条件。
- 多项式乘法可以通过快速傅里叶变换以非常有效的方式完成——FFT是人类有史以来发明的最重要的算法之一。
- 此外,该计算可以并行化:多个处理器可以运行算法的各个部分,以使其更快。
只要要乘的数字足够大,即使是整数乘法(几乎随处可见)等简单计算也可以比schoolbook学校规则更快地完成。
本文适合想了解如何加速一些常规计算并使算法运行得更快的读者
2. Divide and conquer(分而治之): Karatsuba
在小学都学过如何将两个数字相乘:将一个数字写在另一个数字下面,然后将上面的每个数字乘以下面数字的每个数字,然后将所有数字相加:
1234
× 152
——————————————
2468(=1234×2)
6170(=1234×50)
1234(=1234×100)
——————————————
187568(= 187568)
该算法复杂度为
O
(
n
2
)
\mathcal{O}(n^2)
O(n2)。1960 年,Kolmogorov推测这代表了乘法的渐近界限(即两个数的乘积不能小于
O
(
n
2
)
\mathcal{O}(n^2)
O(n2) 次运算)。他就这个话题做了一个演讲,其中一名学生,当时 23 岁的 Karatsuba,想出了一个解决方案——复杂度为
O
(
n
log
2
(
3
)
)
\mathcal{O}(n^{\log_2(3)})
O(nlog2(3)),从而推翻了Kolmogorov猜想。Karatsuba算法的基本思想为:假设要将
x
x
x和
y
y
y相乘,则可将其分解为更小的数字:
x
=
x
1
×
1
0
m
+
x
0
x=x_1\times 10^m +x_0
x=x1×10m+x0
y
=
y
1
×
1
0
m
+
y
0
y=y_1\times 10^m +y_0
y=y1×10m+y0
其中
x
0
,
y
0
x_0,y_0
x0,y0 值均小于
1
0
m
10^m
10m。则
x
×
y
x\times y
x×y乘积简化为:
x
×
y
=
x
1
×
y
1
×
1
0
2
m
+
(
x
1
×
y
0
+
y
1
×
x
0
)
×
1
0
m
+
x
0
×
y
0
x\times y=x_1\times y_1\times 10^{2m}+(x_1\times y_0+y_1\times x_0)\times 10^m+x_0\times y_0
x×y=x1×y1×102m+(x1×y0+y1×x0)×10m+x0×y0
Karatsuba发现,
x
1
×
y
0
+
y
1
×
x
0
x_1\times y_0+y_1\times x_0
x1×y0+y1×x0可以通过引入一些加法操作来有效计算:
x
1
×
y
0
+
y
1
×
x
0
=
(
x
1
+
x
0
)
×
(
y
1
+
y
0
)
−
x
1
×
y
1
−
x
0
×
y
0
x_1\times y_0+y_1\times x_0=(x_1+x_0)\times (y_1+y_0)-x_1\times y_1-x_0\times y_0
x1×y0+y1×x0=(x1+x0)×(y1+y0)−x1×y1−x0×y0
即使有一些额外的计算,这些计算也只是针对较小的数字进行操作,因此对于较大的数字来说,总体成本较小。
3. Toom-Cook 算法
分而治之策略可以进一步实施,从而降低乘法算法的复杂性。Toom 和 Cook 开发了几种方法(称为 Toom-X,X 是一个数字),包括以下阶段:
- 1)Splitting 分裂
- 2)Evaluation 评估
- 3)Pointwise multiplication 逐点乘法
- 4)Interpolation 插值
- 5)Recomposition 重组
GNU 多精度算术库中实现了几种算法变体。
- Toom-2 与 Karatsuba 的算法相同。
- Toom-X:
- 首先将数字 x x x 和 y y y 拆分为 X X X 个长度相等的部分。(如果无法完全拆分,最重要的部分可比其余部分短。 )
- 将这些部分被视为某个多项式的系数(本文重点关注 Toom-3,Toom-4算法可参看15.1.4 Toom 4-Way Multiplication):【为了简化表示,省略乘法符号。】
x ( t ) = x 2 t 2 + x 1 t + x 0 x(t)=x_2 t^2+x_1 t+x_0 x(t)=x2t2+x1t+x0
y ( t ) = y 2 t 2 + y 1 t + y 0 y(t)=y_2 t^2+y_1 t+y_0 y(t)=y2t2+y1t+y0
若评估
x
,
y
x,y
x,y在
t
=
b
t=b
t=b处的值,则可获得分解前的数字。从而将2个数字的乘积等价为degree为
2
(
X
−
1
)
2(X-1)
2(X−1)的多项式:
w
(
t
)
=
w
4
t
4
+
w
3
t
3
+
w
2
t
2
+
w
1
t
+
w
0
w(t)=w_4t^4+w_3t^3+w_2t^2+w_1t+w_0
w(t)=w4t4+w3t3+w2t2+w1t+w0
可在 5 个不同的点处求该多项式的值,根据插值定理,这足以唯一地确定多项式
w
w
w。
可以选择 5 个方便的点,使多项式的求值和重构变得容易。常见的点是:
0
,
1
,
−
1
,
2
,
∞
0,1,-1,2,\infty
0,1,−1,2,∞。(最后一个只是main系数的乘积)。对应每个值的形式为:
w
(
0
)
=
x
(
0
)
y
(
0
)
=
x
0
y
0
w(0)=x(0)y(0)=x_0y_0
w(0)=x(0)y(0)=x0y0
w
(
1
)
=
x
(
1
)
y
(
1
)
=
(
x
0
+
x
1
+
x
2
)
(
y
0
+
y
1
+
y
2
)
w(1)=x(1)y(1)=(x_0+x_1+x_2)(y_0+y_1+y_2)
w(1)=x(1)y(1)=(x0+x1+x2)(y0+y1+y2)
w
(
−
1
)
=
x
(
−
1
)
y
(
−
1
)
=
(
x
0
−
x
1
+
x
2
)
(
y
0
−
y
1
+
y
2
)
w(-1)=x(-1)y(-1)=(x_0-x_1+x_2)(y_0-y_1+y_2)
w(−1)=x(−1)y(−1)=(x0−x1+x2)(y0−y1+y2)
w
(
2
)
=
x
(
2
)
y
(
2
)
=
(
x
0
+
2
x
1
+
4
x
2
)
(
y
0
+
2
y
1
+
4
y
2
)
w(2)=x(2)y(2)=(x_0+2x_1+4x_2)(y_0+2y_1+4y_2)
w(2)=x(2)y(2)=(x0+2x1+4x2)(y0+2y1+4y2)
w
(
∞
)
=
x
(
∞
)
y
(
∞
)
=
x
2
y
2
w(\infty)=x(\infty)y(\infty)=x_2y_2
w(∞)=x(∞)y(∞)=x2y2
从
w
w
w及其系数的角度来看,有:
w
(
0
)
=
w
0
w(0)=w_0
w(0)=w0
w
(
1
)
=
w
4
+
w
3
+
w
2
+
w
1
+
w
0
w(1)=w_4+w_3+w_2+w_1+w_0
w(1)=w4+w3+w2+w1+w0
w
(
−
1
)
=
w
4
−
w
3
+
w
2
−
w
1
+
w
0
w(-1)=w_4-w_3+w_2-w_1+w_0
w(−1)=w4−w3+w2−w1+w0
w
(
2
)
=
16
w
4
+
8
w
3
+
4
w
2
+
2
w
1
+
w
0
w(2)=16w_4+8w_3+4w_2+2w_1+w_0
w(2)=16w4+8w3+4w2+2w1+w0
w
(
∞
)
=
w
4
w(\infty)=w_4
w(∞)=w4
剩下的就是解线性方程(其中 2 个系数很简单)。一旦知道系数,剩下的就是评估
w
w
w在
t
=
b
t=b
t=b处的值,即可作为
x
,
y
x,y
x,y的乘积。
Toom-3 具有比Karatsuba(即Toom-2)的
O
(
n
1.58
)
\mathcal{O}(n^{1.58})
O(n1.58)更低的复杂度——
O
(
n
log
(
5
)
/
log
(
3
)
)
=
O
(
n
1.46
)
\mathcal{O}(n^{\log(5)/\log(3)})=\mathcal{O}(n^{1.46})
O(nlog(5)/log(3))=O(n1.46),因此对于足够大的整数,它运行得更快。
对于更大的整数(大约 10,000 到 40,000 位数字),可以使用 Schönhage-Strassen 算法来加快速度,该算法使用快速傅里叶变换 (FFT) 来实现 O ( n log ( n ) log log ( n ) ) \mathcal{O}(n\log(n)\log\log(n)) O(nlog(n)loglog(n))复杂度。
在解释Schönhage-Strassen 算法之前,需要介绍一下FFT。该算法复杂度可进一步降低为 O ( n log ( n ) ) \mathcal{O}(n\log(n)) O(nlog(n)),但该算法只对(超)难以置信的大数实用,如Galactic algorithm 银河算法。
4. FFT(快速傅里叶变换)
FFT 是许多重要算法的关键组成部分之一,如快速乘以非常大的数字、多项式乘法、求解有限差分方程、纠错码(Reed-Solomon 码)和数字信号处理。19 世纪初,高斯在尝试插值小行星 Pallas 和 Juno 的轨道时使用了 FFT。简单实现需要 O ( n 2 ) \mathcal{O}(n^2) O(n2)次运算。
1965 年,Cooley 和 Tukey 意识到该算法可以更有效地实现,将其简化为 O ( n log ( n ) ) \mathcal{O}(n\log(n)) O(nlog(n)),进而导致了其广泛使用。几乎每种语言和数值计算库都实现了FFT。如 Rust 中有Module fft。
为了了解与简单算法相比的巨大改进,先看下不同样本的计算次数:
| Number of samples | 1 0 3 10^3 103 | 1 0 6 10^6 106 | 1 0 12 10^{12} 1012 |
|---|---|---|---|
| DFT operations | 1 0 6 10^6 106 | 1 0 12 10^{12} 1012 | 1 0 24 10^{24} 1024 |
| FFT operations | 1 0 4 10^4 104 | 2 × 1 0 7 2×10^{7} 2×107 | 4 × 1 0 13 4×10^{13} 4×1013 |
由此可知,对于1000个以上的元素,计算量将减少多于2个量级。
4.1 复数上的 FFT
傅里叶变换将函数从其原始域(空间或时间)映射到另一个函数,具体取决于(空间或时间)频率。换句话说,它将函数分解为具有不同频率和振幅的正弦波集合,这些正弦波可用于分析给定系统的行为。还可以执行反转,将所有这些波相加以恢复原始函数。尽管(连续)傅里叶变换有许多应用,但本文对离散傅里叶变换 (discrete Fourier transform,DFT) 感兴趣,其中有一个有限的数据集合。给定数据
x
0
,
x
1
,
⋯
,
x
N
−
1
x_0,x_1,\cdots,x_{N-1}
x0,x1,⋯,xN−1,该DFT给出序列
X
0
,
X
1
,
⋯
,
X
N
−
1
X_0,X_1,\cdots,X_{N-1}
X0,X1,⋯,XN−1,其中:
X
=
∑
k
=
0
N
−
1
x
k
exp
(
−
2
π
i
k
/
N
)
X=\sum_{k=0}^{N-1} x_k\exp(-2\pi i k/N)
X=∑k=0N−1xkexp(−2πik/N)
其中
i
2
=
−
1
i^2=-1
i2=−1是imaginary unit虚数单位。该DFT 的逆运算由下式给出:
x
=
1
N
∑
k
=
0
N
−
1
X
k
exp
(
2
π
i
k
/
N
)
x=\frac{1}{N}\sum_{k=0}^{N-1} X_k\exp(2\pi i k/N)
x=N1∑k=0N−1Xkexp(2πik/N)
DFT 可以表示为矩阵向量积的形式:
X
=
M
x
X=Mx
X=Mx,其中
M
M
M为
N
×
N
N\times N
N×N DFT矩阵:
M
i
j
=
ω
(
i
−
1
)
×
(
j
−
1
)
M_{ij}=\omega^{(i-1)\times (j-1)}
Mij=ω(i−1)×(j−1)
其中 ω = exp ( 2 π i / N ) \omega=\exp(2\pi i/N) ω=exp(2πi/N), i , j i,j i,j 取值 1 , 2 , 3 , ⋯ , N 1,2,3,\cdots,N 1,2,3,⋯,N。
通过这种方式实现,DFT 需要 N 2 N^2 N2次运算,由向量矩阵乘法产生。FFT 将利用该结构并使用分而治之策略,使此计算更加高效。
还可以将 DFT 视为求具有基于单位根 x k x_k xk系数的多项式,这在讨论快速多项式乘法时很有用。
关键在于计算具有 N N N个点的 DFT 可简化为计算两个 具有 N / 2 N/2 N/2个点的DFT。可以递归地应用这个方法,将一个非常大的问题分解成一组更小、更容易解决的子问题,然后重新组合这些结果以获得 DFT。
该算法还利用了复平面上的
n
n
n-th单位根的属性优势。若
z
n
=
1
z^n=1
zn=1,则称
z
z
z为
n
n
n-th单位根——这些值形如:
z
k
=
exp
(
2
π
i
k
/
n
)
z_k=\exp(2\pi i k/n)
zk=exp(2πik/n),其中
k
=
0
,
1
,
2
,
.
.
.
,
n
−
1
k=0,1,2,...,n-1
k=0,1,2,...,n−1。
有趣的是,这些根是共轭对:对于每个根 r r r有相应的 r ˉ \bar{r} rˉ(事实上,它们形成了一个order为 n n n的有限乘法群)。如,四次方根为: 1 , i , − 1 , − i 1,i,-1,-i 1,i,−1,−i。很容易看出哪些是成对的。
为了了解一切是如何运作的,假设有一个向量 x = ( x 0 , x 1 , x 2 , ⋯ , x n − 1 ) x=(x_0,x_1,x_2,\cdots,x_{n-1}) x=(x0,x1,x2,⋯,xn−1),且要计算 FFT。
可以将其分为偶数项和奇数项:
X
=
∑
k
=
0
n
/
2
−
1
x
2
k
exp
(
2
π
i
2
k
/
n
)
+
∑
k
=
0
n
/
2
−
1
x
2
k
+
1
exp
(
2
π
i
(
2
k
+
1
)
/
n
)
X=\sum_{k=0}^{n/2-1} x_{2k}\exp(2\pi i 2k/n)+\sum_{k=0}^{n/2-1} x_{2k+1}\exp(2\pi i (2k+1)/n)
X=∑k=0n/2−1x2kexp(2πi2k/n)+∑k=0n/2−1x2k+1exp(2πi(2k+1)/n)
可以用不同的方式来表达奇数项,即去掉
exp
(
2
π
i
/
n
)
\exp(2\pi i/n)
exp(2πi/n)因子:
X
=
∑
k
=
0
n
/
2
−
1
x
2
k
exp
(
2
π
i
2
k
/
n
)
+
exp
(
2
π
i
/
n
)
∑
k
=
0
n
/
2
−
1
x
2
k
+
1
exp
(
2
π
i
(
2
k
)
/
n
)
X=\sum_{k=0}^{n/2-1} x_{2k}\exp(2\pi i 2k/n)+\exp(2\pi i/n)\sum_{k=0}^{n/2-1} x_{2k+1}\exp(2\pi i (2k)/n)
X=∑k=0n/2−1x2kexp(2πi2k/n)+exp(2πi/n)∑k=0n/2−1x2k+1exp(2πi(2k)/n)
现在可以看到,只要 k k k大于 n / 2 n/2 n/2,该因子对应于 n n n-th单位根。
另一种看待这个问题的方法是重新排列这些项,从指数的分子中取
2
2
2并将其发送到分母:
X
=
∑
k
=
0
n
/
2
−
1
x
2
k
exp
(
2
π
i
k
/
(
n
/
2
)
)
+
exp
(
2
π
i
/
n
)
∑
k
=
0
n
/
2
−
1
x
2
k
+
1
exp
(
2
π
i
(
k
)
/
(
n
/
2
)
)
X=\sum_{k=0}^{n/2-1} x_{2k}\exp(2\pi i k/(n/2))+\exp(2\pi i/n)\sum_{k=0}^{n/2-1} x_{2k+1}\exp(2\pi i (k)/(n/2))
X=∑k=0n/2−1x2kexp(2πik/(n/2))+exp(2πi/n)∑k=0n/2−1x2k+1exp(2πi(k)/(n/2))
现在发现 ∑ k = 0 n / 2 − 1 x 2 k exp ( 2 π i k / ( n / 2 ) ) = D F T ( x 2 k ) \sum_{k=0}^{n/2-1} x_{2k}\exp(2\pi i k/(n/2))=DFT(x_{2k}) ∑k=0n/2−1x2kexp(2πik/(n/2))=DFT(x2k)只是偶数项的 DFT,其包含 n / 2 n/2 n/2个点。同样地, ∑ k = 0 n / 2 − 1 x 2 k + 1 exp ( 2 π i ( k ) / ( n / 2 ) ) \sum_{k=0}^{n/2-1} x_{2k+1}\exp(2\pi i (k)/(n/2)) ∑k=0n/2−1x2k+1exp(2πi(k)/(n/2))为奇数项的 DFT,包含 n / 2 n/2 n/2个点。
这样,就将 n n n点 DFT 分解为两个较小的 n / 2 n/2 n/2点 DFT,它们可以组合起来得到原始的 DFT。现在,每个 n / 2 n/2 n/2 DFT 可以分解为两个较小的 DFT,因此可以通过使用较小的样本来递归地减少计算次数(这样,就可以免去计算大型向量矩阵乘积的麻烦)。
4.2 将 FFT 扩展到任意环
FFT 可以从复数或实数扩展到任意环,如整数或多项式(详情可参看Math Survival Kit for Developers)。具体来说,可以使用专门用于 FFT 的数论变换来将FFT扩展到 Z / p Z \mathbb{Z}/p\mathbb{Z} Z/pZ,即整数模 p p p( p p p为素数),同时根据 a n ≡ 1 ( m o d p ) a^n\equiv 1(\mod p) an≡1(modp),有 n n n-th单位根。
重要的是,要限制使用素数:在这种情况下,有 1 1 1的平方根仅有2个——为 1 1 1和 − 1 -1 −1。如取 p = 5 p=5 p=5,有 1 2 ≡ 1 ( m o d 5 ) , − 1 ≡ 4 , 4 2 = 16 ≡ 1 ( m o d 5 ) 1^2 \equiv 1 \pmod{5}, -1\equiv 4, 4^2 =16 \equiv 1 \pmod{5} 12≡1(mod5),−1≡4,42=16≡1(mod5)。
而若 p = 8 p=8 p=8为非素数,则不成立,因为 1 2 ≡ 3 2 ≡ 5 2 ≡ 7 2 ≡ 1 ( m o d 8 ) 1^2\equiv 3^2\equiv 5^2\equiv 7^2\equiv 1 \pmod{8} 12≡32≡52≡72≡1(mod8),从而有4个 1 1 1的平方根。
在有限域中使用 FFT 的问题在于:
- 不能随心所欲地选择domain和field。
需要选择一个阶为
2
n
2^n
2n的乘法子群(即,需要选择由元素
g
g
g生成的群,其最多可幂乘
2
n
2^n
2n次)。如,若取
p
=
5
p=5
p=5,由
2
2
2可生成order为
4
=
2
2
4=2^2
4=22的群:
2
1
=
2
,
2
2
=
4
,
2
3
≡
3
,
2
4
≡
1
{2^1=2,2^2=4,2^3\equiv 3, 2^4\equiv 1}
21=2,22=4,23≡3,24≡1
不过该群无需遍历
p
=
5
p=5
p=5中所有元素。
5. FFT乘法算法
该算法与 Karatsuba 和 Toom 的算法遵循相同的思路:
- 1)Splitting 分裂
- 2)Evaluation 评估
- 3)Pointwise multiplication 逐点乘法
- 4)Interpolation 插值
- 5)Recomposition 重组
关键的区别在于使用 FFT 来加速计算。
5.1 多项式乘法
先从多项式乘法开始。给定两个多项式, p ( x ) = p d x d + p d − 1 x d − 1 + . . . + p 0 p(x)=p_d x^d+p_{d-1}x^{d-1}+...+p_0 p(x)=pdxd+pd−1xd−1+...+p0和 q ( x ) = q d x d + q d − 1 x d − 1 + . . . + q 0 q(x)=q_d x^d+q_{d-1}x^{d-1}+...+q_0 q(x)=qdxd+qd−1xd−1+...+q0,要求这2个多项式的积 w ( x ) = p ( x ) q ( x ) w(x)=p(x)q(x) w(x)=p(x)q(x)。
最简单的算法是重复应用分配律,执行乘法并重新排列所有内容。两个degree为 d d d的多项式的乘积是degree为 2 d 2d 2d的多项式。可以看到,该策略涉及计算复杂度为 O ( d 2 ) \mathcal{O}(d^2) O(d2),即运算量随所涉及多项式的degree二次增长。可以利用该多项式的结构和插值定理。至少有两种形式来描述同一个多项式:
- 1)给出 d + 1 d+1 d+1个系数
- 2)指定该多项式在
d
+
1
d+1
d+1个点的评估值
- 第二种选择的优点是什么?可以自由选择点并减少计算次数。
如,若有一个偶函数 f ( x ) = f ( − x ) f(x)=f(-x) f(x)=f(−x),可以计算更少的点。同样,如果函数是奇函数 f ( x ) = − f ( x ) f(x)=-f(x) f(x)=−f(x),则可改变符号来得到 − x -x −x值。因此,选择pair x x x和 − x -x −x,可将评估次数减少一半(例外情况为取 x = 0 x=0 x=0)。
可以将该多项式拆分为两个多项式:一个多项式有奇数项,另一个多项式有偶数项:
p
(
x
)
=
p
e
(
x
)
+
x
p
o
(
x
)
p(x)=p_e(x)+xp_o(x)
p(x)=pe(x)+xpo(x)
如若
p
=
x
5
+
3
x
4
+
5
x
3
+
2
x
2
+
6
x
+
3
p=x^5+3x^4+5x^3+2x^2+6x+3
p=x5+3x4+5x3+2x2+6x+3,可将其切分为:
p
(
x
)
=
(
3
x
4
+
2
x
2
+
3
)
+
x
(
x
4
+
5
x
2
+
6
)
p(x)=(3x^4+2x^2+3)+x(x^4+5x^2+6)
p(x)=(3x4+2x2+3)+x(x4+5x2+6)
从而有:
p
e
=
(
3
x
4
+
2
x
2
+
3
)
p_e=(3x^4+2x^2+3)
pe=(3x4+2x2+3)
p
o
=
(
x
4
+
5
x
2
+
6
)
p_o=(x^4+5x^2+6)
po=(x4+5x2+6)
这2个多项式均为偶函数!从而有:
p
(
−
x
)
=
p
e
(
x
)
−
x
p
o
(
x
)
p(-x)=p_e(x)-xp_o(x)
p(−x)=pe(x)−xpo(x)
如果有pair ( x k , p ( x k ) ) (x_k,p(x_k)) (xk,p(xk)) 和 ( x k , q ( x k ) ) (x_k,q(x_k)) (xk,q(xk)),则 p ( x ) q ( x ) p(x)q(x) p(x)q(x)乘积多项式在 x k x_k xk处的评估值为 ( x k , ( p ( x k ) q ( x k ) ) ) (x_k,(p(x_k)q(x_k))) (xk,(p(xk)q(xk)))。
为确定该乘积多项式,需要 2 d + 1 2d+1 2d+1个点,利用上述策略,需要更少的点评估值。如果可以轻松地从系数形式转换为点评估值形式,以该形式执行乘法,然后转换回系数形式,可以实现较低的复杂度。可以递归地将 p e ( x 2 ) , p o ( x 2 ) p_e(x^2), p_o(x^2) pe(x2),po(x2)多项式分解为更小的多项式。
可以选 n n n个单位根作为评估点,从而有pairs: e x p ( 2 π i k / n ) exp(2\pi i k/n) exp(2πik/n),其中 k = 0 , 1 , 2 , ⋯ , n − 1 k=0,1,2,\cdots,n-1 k=0,1,2,⋯,n−1。换句话说,可以快速计算该多项式的 DFT,将系数相乘,一旦找到该乘积,就可以reverse反转该 DFT。这样的算法复杂度为 O ( d log d ) \mathcal{O}(d\log d) O(dlogd)。
5.2 整数乘法
要将 FFT 应用于整数乘法,需要将数字转换为多项式的系数,执行 FFT 乘法,最后重建结果。总的来说,这将需要 O ( n log ( n ) log ( log ( n ) ) \mathcal{O}(n\log(n)\log(\log(n)) O(nlog(n)log(log(n))次运算。开销很大,因此该算法只适用于非常大的整数。如,若要乘以 3578 3578 3578 和 2457 2457 2457,可以定义向量 ( 8 , 7 , 5 , 3 , 0 , 0 , 0 , 0 ) (8,7,5,3,0,0,0,0) (8,7,5,3,0,0,0,0)和 ( 7 , 5 , 4 , 2 , 0 , 0 , 0 , 0 ) (7,5,4,2,0,0,0,0) (7,5,4,2,0,0,0,0),其中可方便地用零填充数字。
通常,运算是在模 2 N + 1 2^N + 1 2N+1 下进行,其中 N N N大于整数 x x x和 y y y 的总位数,以确保计算结果不会发生wrap around溢出。
傅立叶变换的一个优势在于:
- 诸如 x x x 和 y y y 的卷积可以通过它们的变换 X X X 和 Y Y Y 的乘积计算,并通过逆变换得到结果:
∑ k = 0 N x k y N − k = IFFT ( FFT ( y ) × FFT ( x ) ) \sum_{k=0}^{N} x_k y_{N-k} = \text{IFFT}(\text{FFT}(y) \times \text{FFT}(x)) ∑k=0NxkyN−k=IFFT(FFT(y)×FFT(x))
Schönhage-Strassen 算法利用了负循环卷积(negacyclic convolution)。给定长度为 n n n 的向量 x x x 和 y y y,以及 r r r 为 2 n 2n 2n-th (primitive)单位根(即满足 r 2 n ≡ 1 m o d p r^{2n} \equiv 1 \mod p r2n≡1modp 且对于 0 < k < 2 n 0 < k < 2n 0<k<2n, r k ≢ 1 r^k \not\equiv 1 rk≡1),可以定义如下的权重向量:
W j = r j , for 0 ≤ j < n W_j = r^j, \quad \text{for } 0 \leq j < n Wj=rj,for 0≤j<n
W j − 1 = r − j , for 0 ≤ j < n W^{-1}_j = r^{-j}, \quad \text{for } 0 \leq j < n Wj−1=r−j,for 0≤j<n
负循环卷积(NCC) 的计算方式如下:
NCC ( x , y ) = W − 1 IFFT ( FFT ( W x ) × FFT ( W y ) ) \text{NCC}(x, y) = W^{-1} \text{IFFT}(\text{FFT}(W_x) \times \text{FFT}(W_y)) NCC(x,y)=W−1IFFT(FFT(Wx)×FFT(Wy))
GNU Multiple Precision Arithmetic Library 实现了不同方法的比较,详情可见New Toom multiplication code for unbalanced operands。
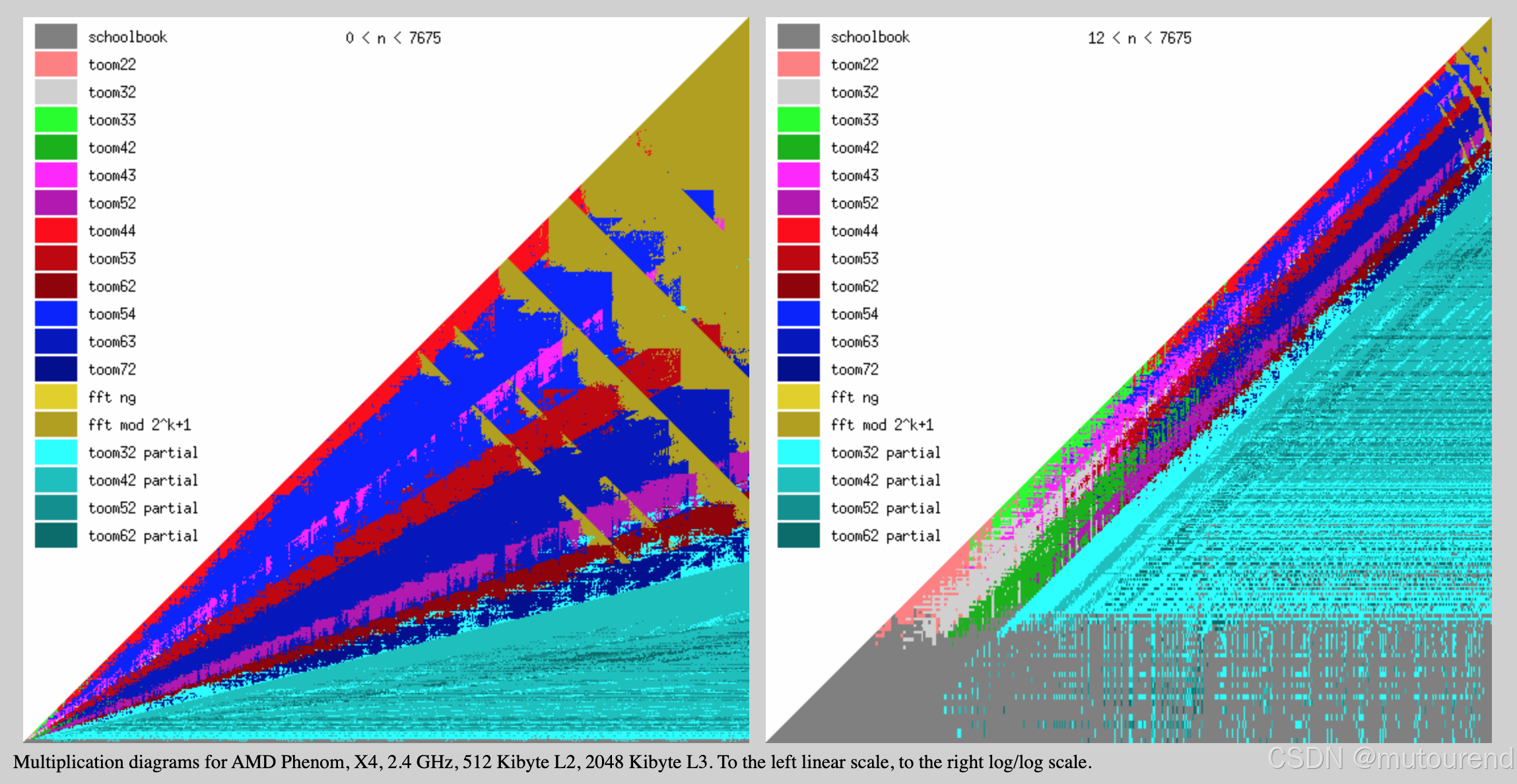

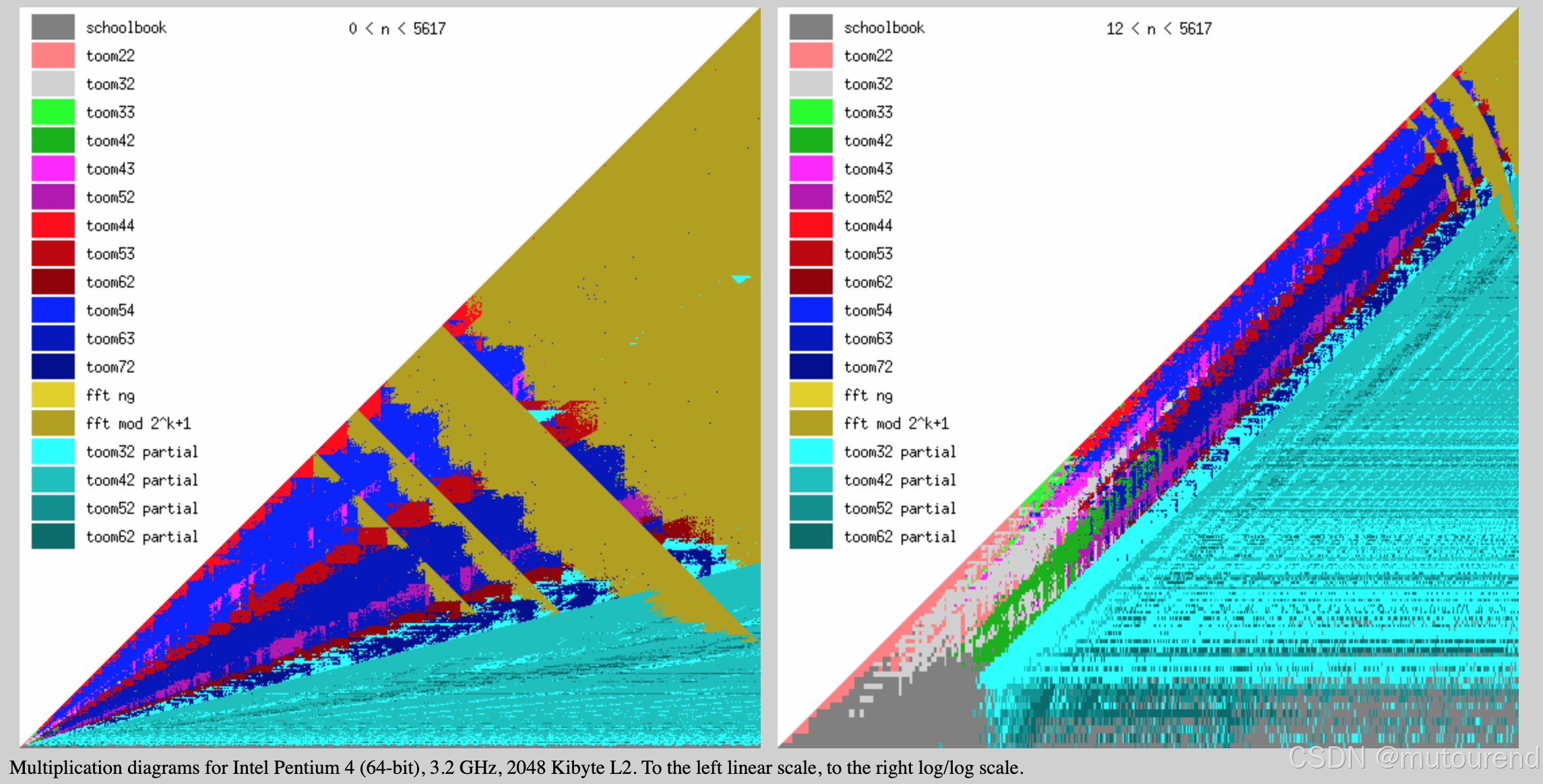
6. 总结
选择合适的算法来执行常规计算(如整数或多项式乘法)对软件的性能可能产生显著影响。根据整数的大小,可以通过分治法加速计算(减少计算次数):
- 将计算拆分为较小的部分,使其更易处理,或者不断拆分,直到变得可管理。
本文介绍的所有快速算法都采用了这一方法,从而大幅减少计算量。
快速傅立叶变换(FFT)由于其复杂度为 O ( n log n ) O(n \log n) O(nlogn),可以作为加速计算的有力工具,尽管一开始它可能看起来有些奇怪或难以理解!
参考资料
[1] LambdaClass 2023年1月博客 Weird ways to multiply really fast with Karatsuba, Toom–Cook and Fourier

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









