







前言
InfiniteBench 是清华刘知远团队做的一个面向 100k+ 长序列(平均上下文长度为195k)的 3946 条评测集。该评测集针对大模型在长文本方面的5项能力、12个子任务而设计:检索、数学、代码、问答、摘要。
既包含真实场景数据,探测大模型在处理实际问题的能力;也包含合成数据,为测试数据拓展上下文窗口提供了便捷。
Github:https://github.com/OpenBMB/InfiniteBench
数据集:https://huggingface.co/datasets/xinrongzhang2022/InfiniteBench
论文:https://arxiv.org/abs/2402.13718
论文关键内容
Introduction & Related Work
目前的长上下文基准主要特点是平均上下文长度约为10K token(Bai et al., 2023; Tay et al., 2020),大多低于100K token。这种长上下文评估方法的滞后阻碍了不同长上下文LLMs的比较分析,并指出了长上下文处理中潜在的改进方向。
- 长文模型技术栈:旋转位置编码、YaRN、滑动窗口注意力、LM-Infinite、StreamingLLM…
- 长文评测基准:L-Eval(An et al., 2023)和 LongBench(Bai et al., 2023)等现有评测基准的上下文长度约为 10K tokens。
- LongBench 包括四个类别—问答、摘要、合成检索和代码—涵盖 21 个任务,其中四个是新颖的。
- 相反,L-Eval 在问答、摘要、数学、检索和多项选择(MC)领域整合了 18 个任务,引入了三个新任务。
- 另一个值得注意的基准,LooGLE(Li et al., 2023),区分了短依赖和长依赖的例子,专注于摘要和问答任务;它的摘要语料库与我们的不同,使用的是学术论文而不是小说。
- Long-Range Arena(LRA)(Tay et al., 2020)进一步多样化,设计了六个文本、图像和数学任务,用于可扩展性。
相比之下,∞BENCH 以其更长的上下文和更广泛的任务领域而脱颖而出。
表1:已有长文评测集(中文的只有longbench)
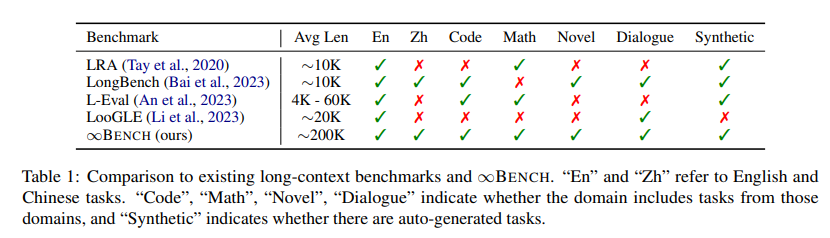
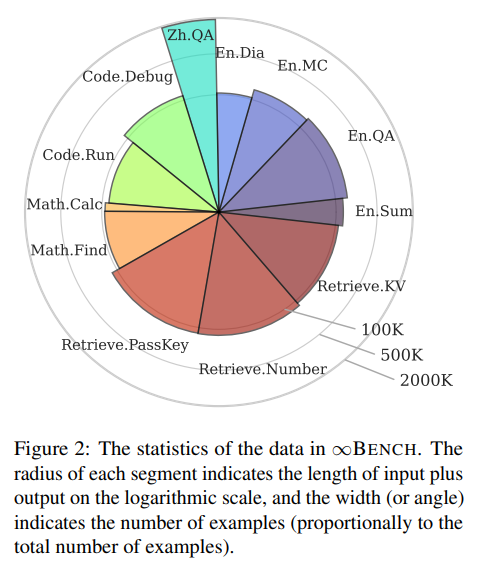
图2描述了∞BENCH中数据的统计信息。每个任务由一个扇形表示,扇形的半径代表该任务数据的长度(输入和输出的token数),而扇形所占的角度代表该任务中的样本数量相对于整个数据集中样本数量的比例。
数据说明
包括真实数据、合成数据。两大类下面分别又有各种类型的数据源,基于这些数据源构建不同的任务。
真实数据
小说(Novel)
按照如图所示的开发基于小说的任务,利用从网站获取并手动筛选的小说。在这些任务中,模型需要在推理期间对整本小说进行推理。
认识到许多小说以及它们的电影改编和相关讨论可能在网上可以获取,并且可能在训练期间已经被LLMs遇到过,我们采用关键实体替换作为对策。这包括将注释者确定的突出实体(如主角名字)替换为不相关的实体,创建“假小说”。使用这些修改后的小说,我们设计了三种格式的任务:摘要(Sum)、开放式问答(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









