







CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.IR、cs.MM
1.A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions

标题:关于多模态推荐系统的综合调查:分类、评估和未来方向
作者:Hongyu Zhou, Xin Zhou, Zhiwei Zeng, Lingzi Zhang, Zhiqi Shen
文章链接:https://arxiv.org/abs/2302.04473v1
项目代码:https://github.com/enoche/mmrec
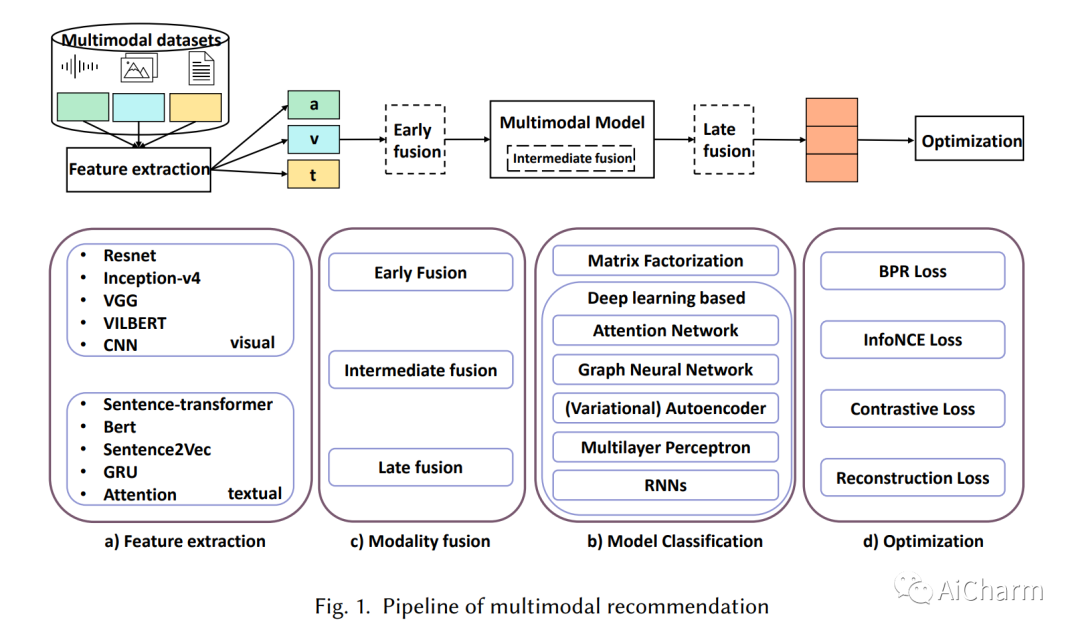
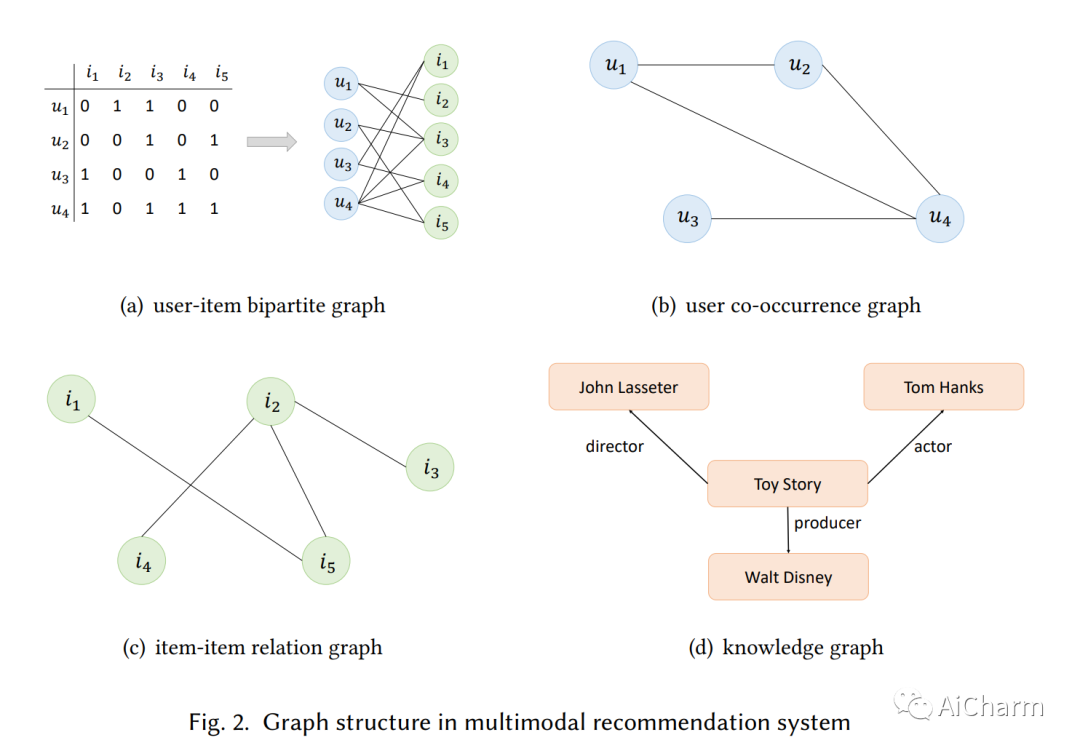
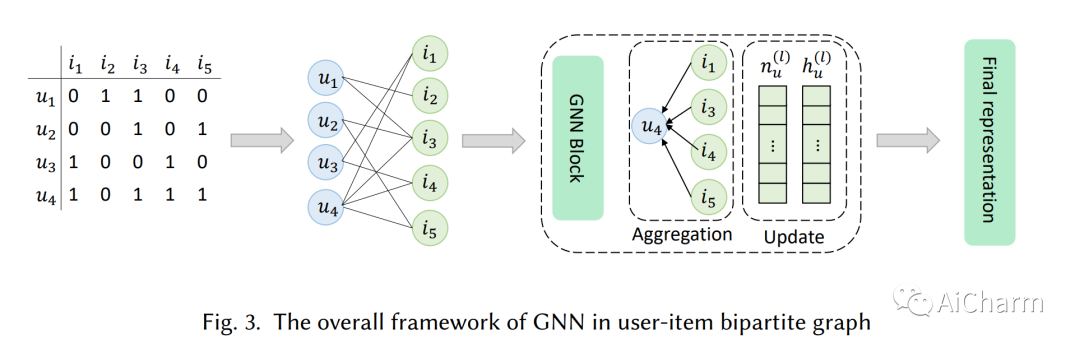
摘要:
推荐系统已经成为流行和有效的工具,通过基于隐性互动(如购买和点击)的用户偏好和物品属性建模,帮助用户发现他们感兴趣的物品。人类通过处理模态信号(如音频、文本和图像)来感知世界,这启发了研究人员建立一个能够理解和解释不同模态数据的推荐系统。这些模型可以捕捉到不同模态之间的隐藏关系,并可能恢复单模态方法和隐性互动所不能捕捉到的互补性信息。本调查的目的是对最近关于多模态推荐的研究工作进行全面回顾。具体来说,它展示了一个清晰的管道,每一步都有常用的技术,并按所使用的方法对模型进行分类。此外,我们还设计了一个代码框架,帮助该领域的新研究人员理解原理和技术,并轻松运行SOTA模型。
Recommendation systems have become popular and effective tools to help users discover their interesting items by modeling the user preference and item property based on implicit interactions (e.g., purchasing and clicking). Humans perceive the world by processing the modality signals (e.g., audio, text and image), which inspired researchers to build a recommender system that can understand and interpret data from different modalities. Those models could capture the hidden relations between different modalities and possibly recover the complementary information which can not be captured by a uni-modal approach and implicit interactions. The goal of this survey is to provide a comprehensive review of the recent research efforts on the multimodal recommendation. Specifically, it shows a clear pipeline with commonly used techniques in each step and classifies the models by the methods used. Additionally, a code framework has been designed that helps researchers new in this area to understand the principles and techniques, and easily runs the SOTA models. Our framework is located at:
Subjects: cs.CV、cs.CL、cs.LG
2.Offsite-Tuning: Transfer Learning without Full Model
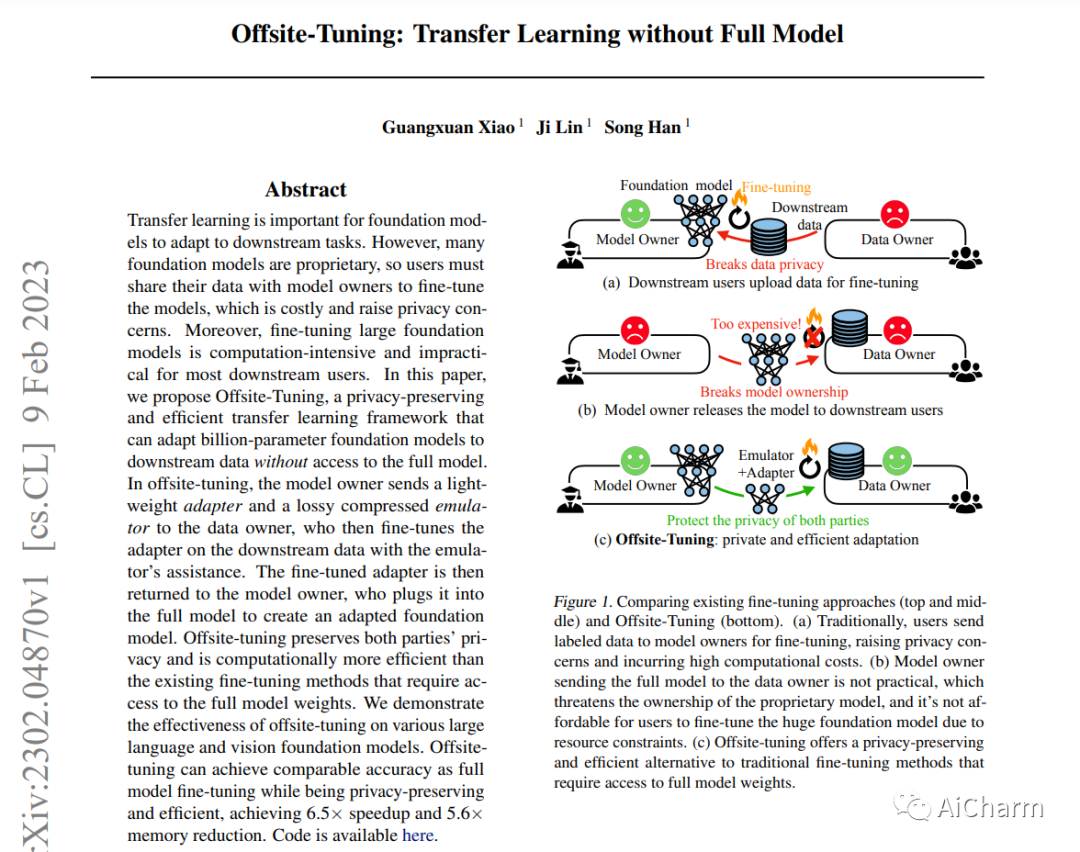
标题:场外调谐:没有完整模型的转移学习
作者:Guangxuan Xiao, Ji Lin, Song Han
文章链接:https://arxiv.org/abs/2302.04870v1
项目代码:https://github.com/mit-han-lab/offsite-tuning
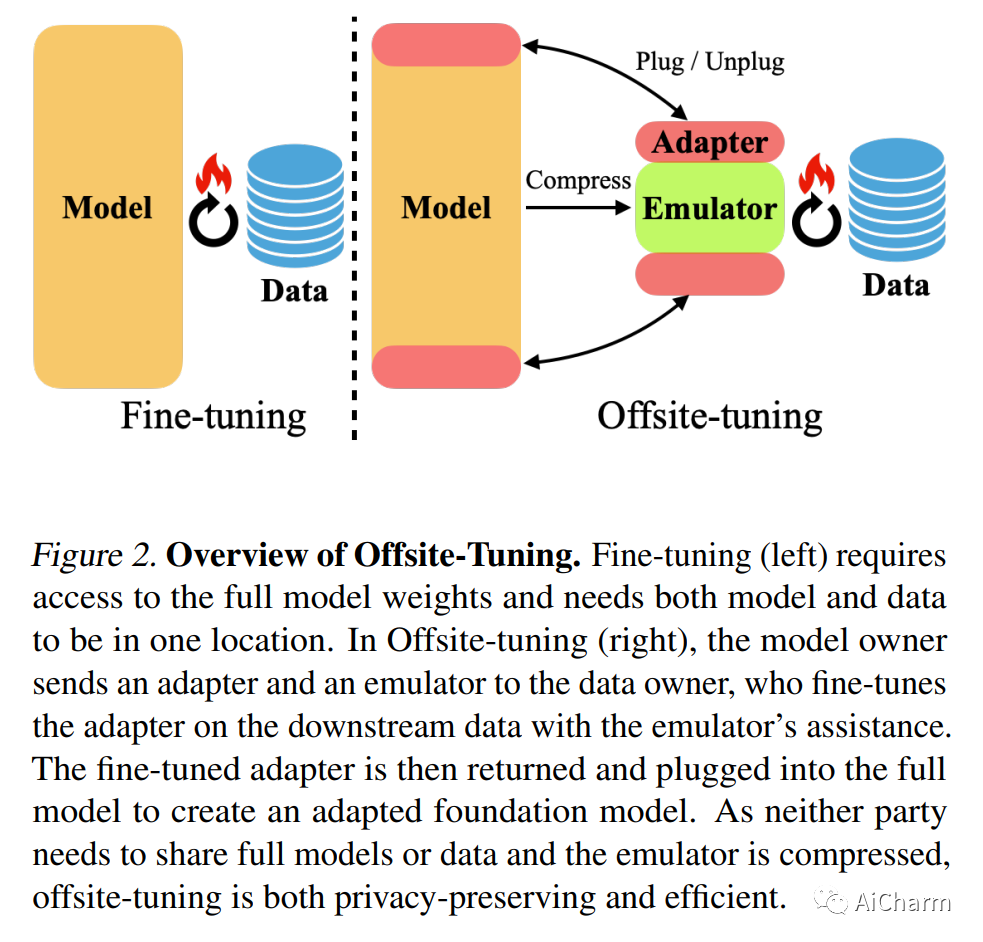
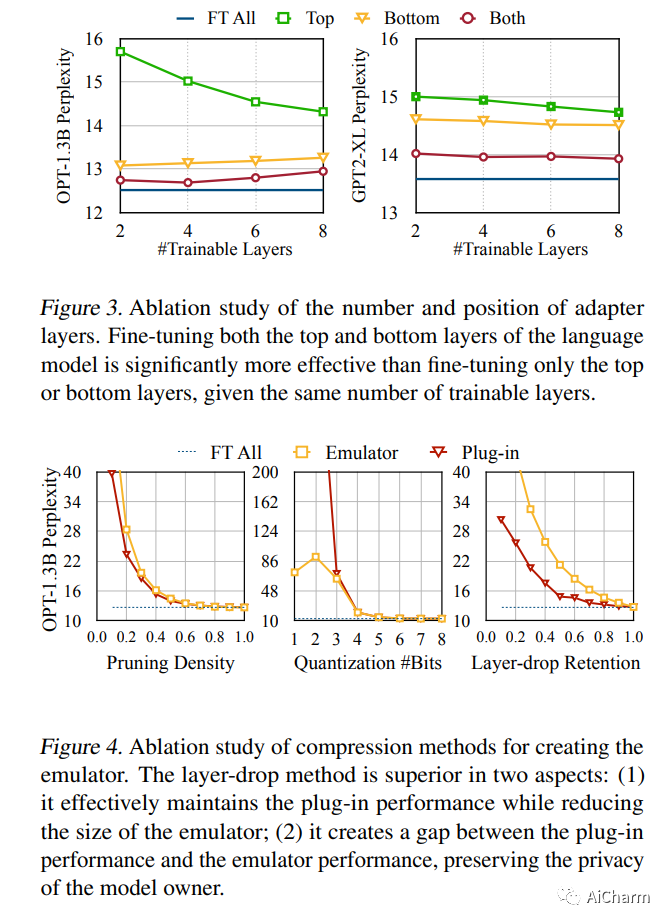
摘要:
迁移学习对于基础模型适应下游任务很重要。然而,许多基础模型是专有的,所以用户必须与模型所有者分享他们的数据以微调模型,这是很昂贵的,并引起了隐私问题。此外,微调大型地基模型是计算密集型的,对大多数下游用户来说不切实际。在本文中,我们提出了Offsite-Tuning,一个保护隐私和高效的迁移学习框架,它可以在不接触完整模型的情况下将十亿个参数的基础模型适应于下游数据。在异地调优中,模型所有者向数据所有者发送一个轻量级的适配器和一个有损压缩的仿真器,然后在仿真器的帮助下对下游数据的适配器进行微调。然后,微调后的适配器被返回给模型所有者,后者将其插入完整的模型中,以创建一个适应的基础模型。场外微调保留了双方的隐私,并且比现有的需要访问完整模型权重的微调方法在计算上更有效率。我们在各种大型语言和视觉基础模型上证明了非现场调整的有效性。异地微调可以达到与全模型微调相当的精度,同时又能保护隐私和效率,实现了6.5倍的速度提升和5.6倍的内存减少。
Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at this https URL.
3.Drawing Attention to Detail: Pose Alignment through Self-Attention for Fine-Grained Object Classification

标题:对细节的关注:通过自我关注进行细粒度物体分类的姿势对准
作者:Salwa Al Khatib, Mohamed El Amine Boudjoghra, Jameel Hassan
文章链接:https://arxiv.org/abs/2302.04800v1
项目代码:https://github.com/salwaalkhatib/p2p-net
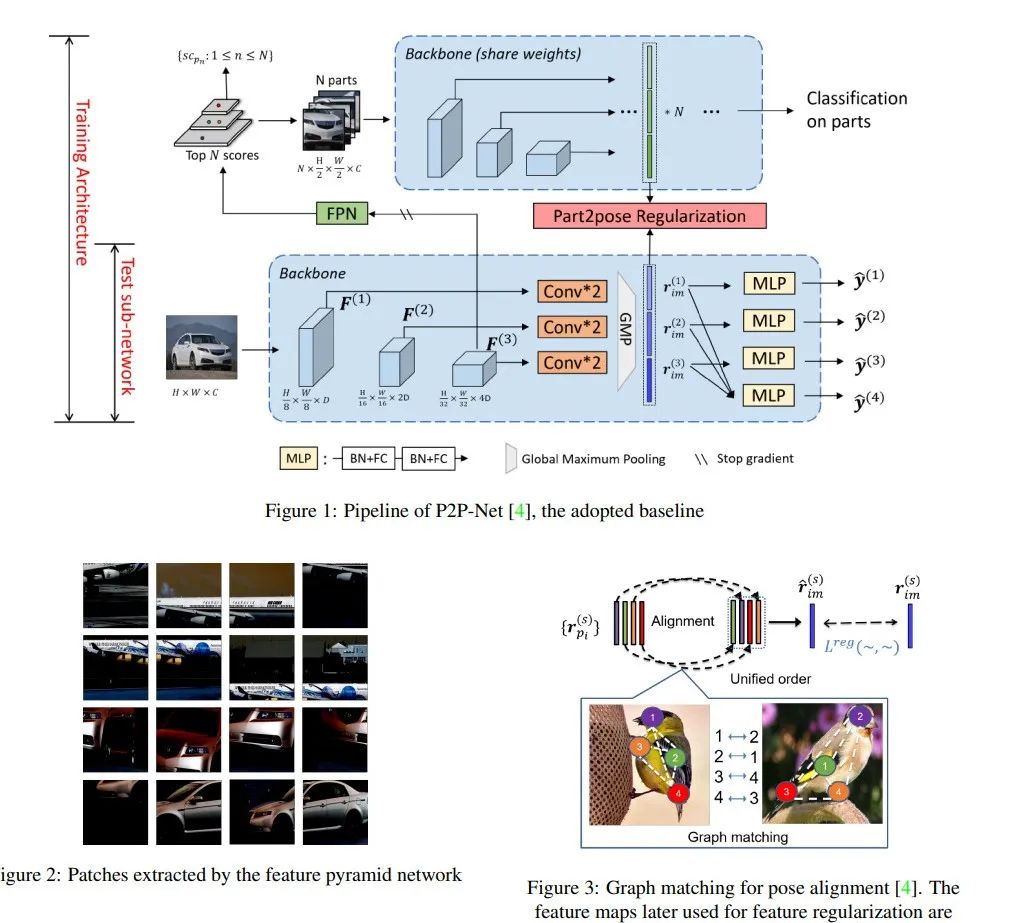
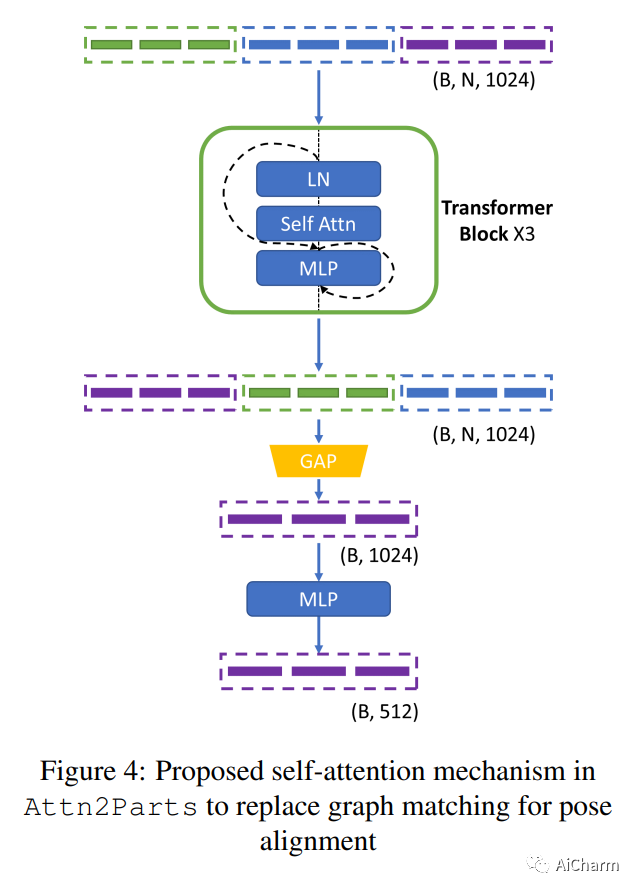
摘要:
开放世界中的类内变化导致了分类任务的各种挑战。为了克服这些挑战,人们引入了细粒度分类,并提出了许多方法。一些方法依靠定位和使用图像中可区分的局部部分来实现对视角变化、类内差异和局部部分变形的不变性。我们的方法受到P2P-Net的启发,提供了一个端到端可训练的基于注意力的部件对齐模块,其中我们用一个自我注意力机制取代了其中使用的图形匹配组件。注意力模块能够在相互关注的同时学习零件的最佳排列,然后再对全局损失做出贡献。
Intra-class variations in the open world lead to various challenges in classification tasks. To overcome these challenges, fine-grained classification was introduced, and many approaches were proposed. Some rely on locating and using distinguishable local parts within images to achieve invariance to viewpoint changes, intra-class differences, and local part deformations. Our approach, which is inspired by P2P-Net, offers an end-to-end trainable attention-based parts alignment module, where we replace the graph-matching component used in it with a self-attention mechanism. The attention module is able to learn the optimal arrangement of parts while attending to each other, before contributing to the global loss.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











