






1.ReXTime: A Benchmark Suite for Reasoning-Across-Time in Videos

标题: ReXTime:视频中跨时空推理的基准测试套件
作者: Jr-Jen Chen, Yu-Chien Liao, Hsi-Che Lin, Yu-Chu Yu, Yen-Chun Chen, Yu-Chiang Frank Wang
文章链接:https://arxiv.org/abs/2406.19392
项目代码:https://rextime.github.io/
摘要:
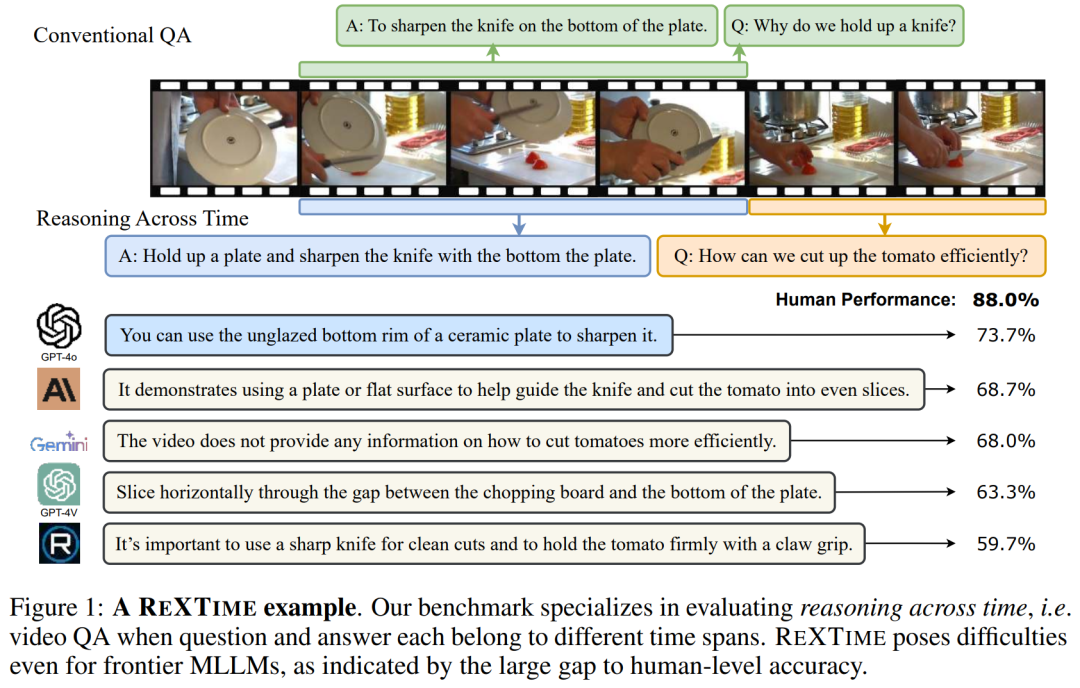
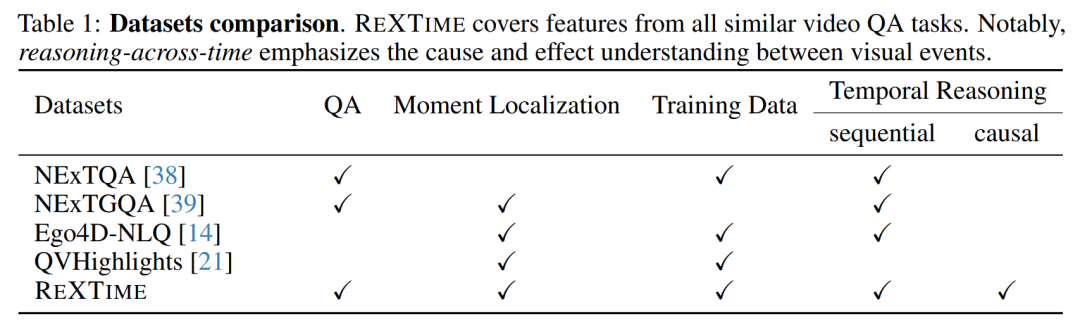
我们介绍了 ReXTime,这是一个基准测试,旨在严格测试 AI 模型在视频事件中执行时间推理的能力。具体来说,ReXTime专注于跨时间推理,即当问题及其相应的答案出现在不同的视频片段中时,可以像人类一样理解。这种推理形式需要对视频片段之间的因果关系有深入的理解,甚至对前沿的多模态大型语言模型也提出了重大挑战。为了促进这种评估,我们开发了一个用于生成时间推理问答对的自动化管道,大大减少了对劳动密集型手动注释的需求。我们的基准测试包括 921 个经过仔细审查的验证样本和 2,143 个测试样本,每个样本都经过手动管理,以确保准确性和相关性。评估结果表明,虽然前沿大型语言模型的表现优于学术模型,但它们仍然落后于人类的表现,准确率差距为14.3%。此外,我们的管道创建了一个包含 9,695 个机器生成样本的训练数据集,无需手动操作,实证研究表明,这可以通过微调来增强跨时间推理。
这篇论文试图解决什么问题?
这篇论文介绍了一个名为REXTIME的基准测试套件,旨在严格测试人工智能模型在视频事件中进行跨时推理的能力。具体来说,REXTIME专注于跨时推理,即类似人类的理解方式,当问题和其对应的答案出现在不同的视频片段中。这种推理形式要求对视频片段间因果关系有高级的理解,对现有的前沿多模态大型语言模型(MLLMs)构成了重大挑战。
论文的主要贡献包括:
-
提出REXTIME基准测试:这是第一个全面评估视频事件中因果关系的跨时推理能力的基准测试,包含2143个测试样本,显示出前沿MLLMs在人类水平性能上仍有显著差距。
-
发现MLLMs的共同弱点:即使在最先进的MLLMs中,当问题和答案的时间跨度不重叠时,它们的推理能力也表现不佳。通过新提出的QA-IoU度量方法,REXTIME能够量化地验证AI模型的跨时推理能力。
-
开发LLM辅助数据管道:通过这个管道,可以生成高质量的样本,并减少人工干预,节省了55%的总体成本。此外,纯机器生成的训练集在微调精度上显示出改进,为未来的研究提供了起点。
-
评估视频时刻定位:为了评估AI模型是否能够准确地将其答案定位到正确的视频片段,论文还考虑了视频时刻定位的评估。
-
提供大量机器生成的样本:REXTIME的自动化管道创建了一个包含9695个样本的训练数据集,这些样本无需手动努力即可生成,实证研究表明这可以通过微调增强跨时推理。
总的来说,这篇论文通过开发REXTIME基准测试套件,旨在推动和评估AI模型在视频理解和跨时推理方面的能力,特别是在因果关系理解方面。
论文如何解决这个问题?
论文通过以下几个关键步骤来解决跨时推理的挑战:
-
开发REXTIME基准测试套件:创建了一个新的基准测试,专注于评估AI模型在视频事件中进行因果关系推理的能力。这个基准测试包括921个验证样本和2143个测试样本,每个样本都经过人工审核以确保准确性和相关性。
-
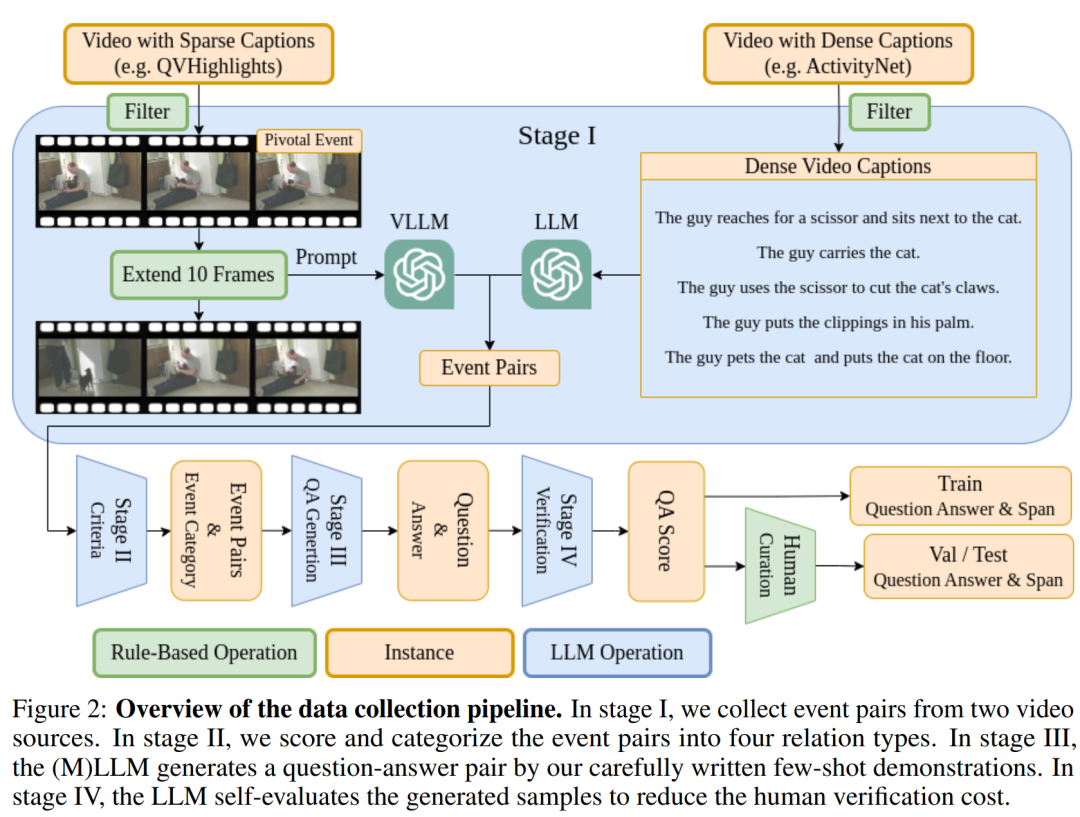
自动化数据生成管道:提出了一个大型语言模型(LLM)辅助的数据生成管道,以最小化人工努力并降低成本。这个管道通过使用少量示例(few-shot demonstrations)来引导LLM生成问题-答案(QA)对,从而在保持逻辑正确性的同时增加响应的多样性。
-
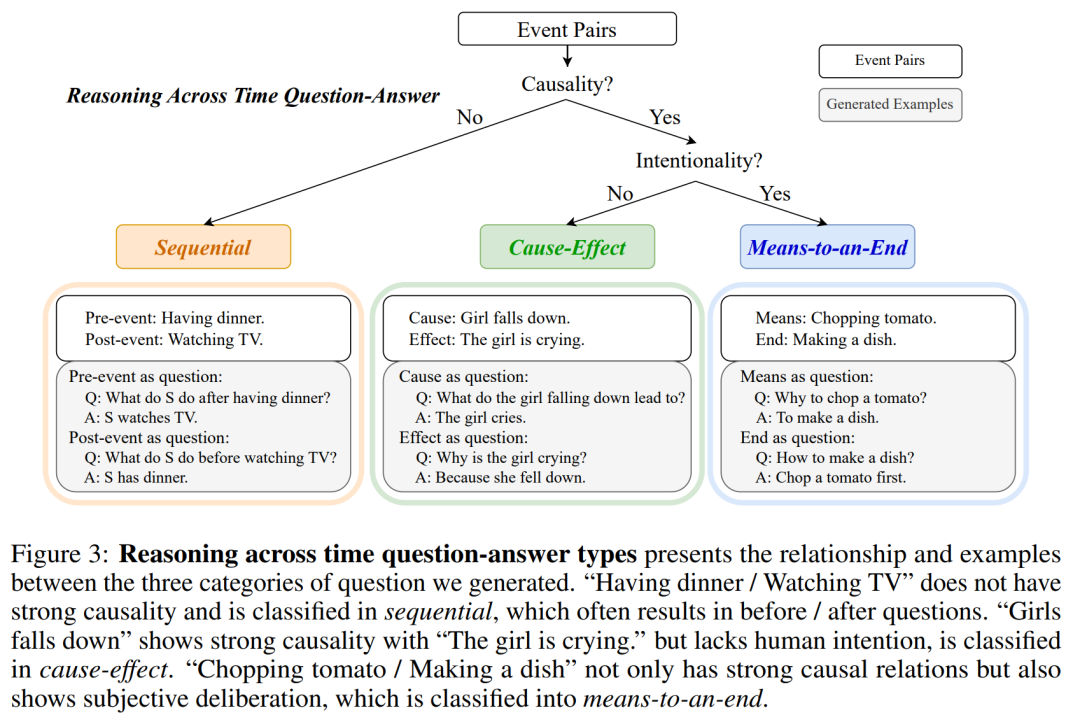
事件对的提取和分类:从视频字幕中提取事件对,并将它们分类为三种关系类型:手段-目的(means-to-an-end)、因果关系(cause-effect)和顺序关系(sequential)。这有助于生成具有不同时间跨度的问题和答案。
-
质量与多样性的平衡:通过使用特定的事件属性和时间关系来调节MLLM,解决了生成逻辑上不正确响应的问题,同时保持了响应的多样性。
-
自动数据验证:为了减少人工验证的成本,论文中的LLM能够自我评估其生成的QA对的逻辑正确性,从而有效减少了需要人工审核的样本数量。
-
多模态理解评估:要求模型输出所选答案的时间跨度,并使用交并比(IoU)作为评估指标,以更好地反映模型的多模态理解能力。
-
生成训练数据集:通过自动化管道生成了9695个机器生成的样本,这些样本无需手动努力即可创建,为未来的研究提供了一个起点。
-
实证研究:通过实验评估了前沿的大型语言模型和学术模型在REXTIME基准测试上的性能,显示出即使最先进的模型也存在显著的改进空间。
通过这些方法,论文不仅提出了一个针对视频事件跨时推理的挑战性基准测试,而且还展示了如何通过自动化和人工审核相结合的方式高效地生成高质量的训练和测试数据。此外,论文还通过实验结果展示了现有模型在这一任务上的局限性,并为未来的研究提供了改进的方向。
论文做了哪些实验?
论文中进行了一系列实验来评估REXTIME基准测试套件的有效性,并测试不同模型在跨时推理任务上的性能。以下是论文中提到的主要实验:
-
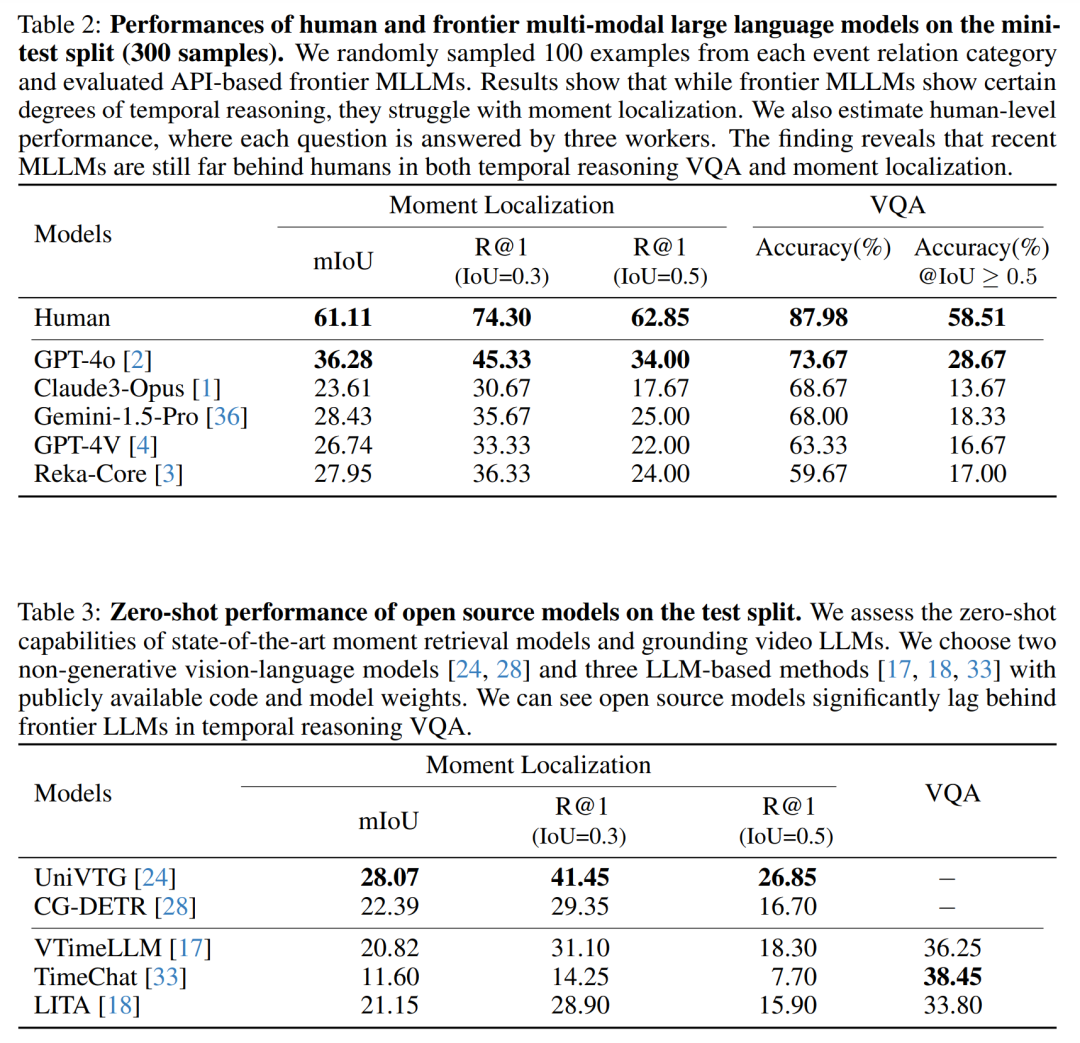
人类与模型性能比较:展示了人类在视频问答(VQA)任务上的准确性,并与顶级多模态大型语言模型(MLLMs)的性能进行了比较。这揭示了现有模型与人类水平之间的性能差距。
-
模型性能评估:测试了不同的MLLMs,包括GPT-4V、GPT-4o、Gemini、Claude和Reka-Core,在REXTIME数据集上的VQA准确性和时刻定位能力。
-
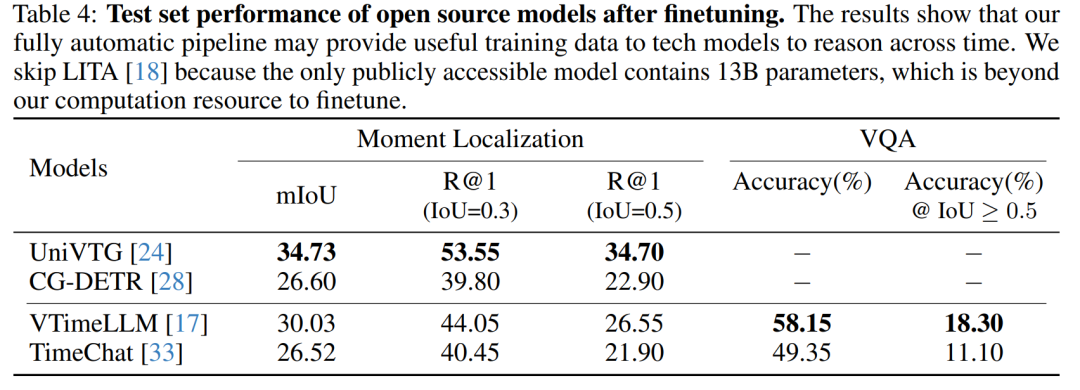
开源模型的零样本(Zero-shot)性能:评估了几种开源模型在没有经过微调的情况下,在REXTIME测试集上的性能。
-
开源模型的微调(Fine-tuning)性能:在REXTIME数据集上微调了一些开源模型,并评估了微调后的性能提升。
-
数据集统计分析:介绍了REXTIME数据集的统计信息,包括跨时推理样本的数量、证书长度(Certificate Length, C.L.)和问题-答案交集(Question-Answer Intersection over Union, QA-mIoU)。
-
数据分布分析:分析了REXTIME数据集中问题类型、问题长度和视频持续时间的分布。
-
模型的多模态理解能力评估:通过要求模型输出所选答案的时间跨度,并使用IoU作为评估指标,来评估模型的多模态理解能力。
-
自动化数据生成管道的效率评估:通过比较自动化生成的数据与人工创建的数据的成本和效率,展示了自动化管道的优势。
-
模型的因果关系理解能力评估:通过生成的问题-答案对,评估了模型在理解事件之间因果关系方面的能力。
这些实验不仅验证了REXTIME基准测试的有效性,也揭示了现有模型在视频理解和跨时推理任务上的局限性,并为未来的研究提供了有价值的见解。
论文的主要内容:
REXTIME基准测试套件的论文主要内容可以总结如下:
-
问题定义:论文首先定义了跨时推理问题,即在视频事件中,问题和答案出现在不同视频片段的情况下,AI模型如何进行有效的因果关系推理。
-
REXTIME基准测试套件:介绍了REXTIME基准测试套件,这是一个专门设计来评估AI模型进行视频事件跨时推理能力的工具。它包含了921个验证样本和2143个测试样本,这些样本都经过了人工审核以确保准确性和相关性。
-
自动化数据生成管道:提出了一个利用大型语言模型(LLM)辅助的数据生成管道,以减少人工注释的工作量,并显著降低数据生成成本。
-
样本生成和分类:描述了如何从视频字幕中提取事件对,并将它们分类为三种关系类型:手段-目的、因果关系和顺序关系,以生成具有不同时间跨度的问题和答案。
-
评估指标:定义了评估AI模型跨时推理能力的性能指标,包括VQA准确性和时刻定位的IoU指标。
-
实验结果:展示了前沿大型语言模型在REXTIME基准测试上的性能,并与人类表现进行了比较,揭示了现有模型与人类水平之间的性能差距。
-
开源模型的性能:评估了开源模型在REXTIME基准测试上的零样本和微调后的性能,指出了它们在跨时推理任务上的局限性。
-
数据集统计分析:提供了REXTIME数据集的统计信息,包括样本数量、证书长度和问题-答案交集等指标。
-
未来研究方向:讨论了跨时推理领域的潜在研究方向,包括改进数据生成管道、增强模型的因果推理能力、提高模型的可解释性等。
-
社会影响和伦理考量:简要讨论了视频理解和跨时推理技术在社会应用中的潜在影响,包括隐私保护和伦理问题。
论文通过提出REXTIME基准测试套件,不仅为视频跨时推理领域提供了新的评估工具,也为未来的研究提供了有价值的见解和方向。
2.Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads

标题: Fibottention:具有不同注意力的视觉表示学习
作者:Ali Khaleghi Rahimian, Manish Kumar Govind, Subhajit Maity, Dominick Reilly, Christian Kümmerle, Srijan Das, Aritra Dutta
文章链接:https://arxiv.org/abs/2406.19391
项目代码:https://github.com/Charlotte-CharMLab/Fibottention



摘要:
视觉感知任务主要由视觉转换器 (ViT) 架构解决,尽管它们很有效,但由于计算自我注意力的二次复杂度,它们遇到了计算瓶颈。这种低效率主要是由于自我注意力头捕获了冗余的令牌交互,反映了视觉数据中固有的冗余。许多工作旨在降低ViT中自我注意力的计算复杂性,从而开发高效和稀疏的变压器架构。在本文中,从效率的角度来看,我们意识到在 ViT 中引入任何稀疏自注意力策略都可以保持较低的计算开销。然而,这些策略是次优的,因为它们通常无法捕捉到细粒度的视觉细节。这一观察结果促使我们提出了一种通用的、高效的、稀疏的架构,称为 Fibottention,用于在斐波那契数列上构建的具有超线性复杂性的近似自注意力。Fibottention 中的关键策略包括:它排除了近似代币以减少冗余,在设计上采用结构化的稀疏性来减少计算需求,并在注意力头之间整合了类似 inception 的多样性。这种多样性确保了通过不重叠的令牌交互捕获互补信息,优化了视觉表示学习的 ViT 中的性能和资源利用率。我们将 Fibottention 机制嵌入到多个专用于视觉任务的先进变压器架构中。Fibottention仅利用自我注意力头中2-6%的元素,与ViT及其变体相结合,在 – 图像分类、视频理解和机器人学习任务三个领域的九个数据集中,与标准ViT相比,始终如一地实现了显著的性能提升。
这篇论文试图解决什么问题?
这篇论文试图解决的主要问题是视觉变换器(Vision Transformer,简称ViT)架构在处理视觉感知任务时面临的计算瓶颈问题。尽管ViT架构在多个领域表现出了有效性,但它们在计算自注意力(self-attention)时具有二次复杂度,这导致了显著的计算成本。这种低效率主要是因为自注意力头捕获了冗余的token交互,这反映了视觉数据内在的冗余性。
论文中提到,尽管已有多种工作致力于减少ViT中自注意力的计算复杂度,发展了高效和稀疏的变换器架构,但这些策略在降低计算开销的同时,往往无法捕获到细粒度的视觉细节,因此被认为是次优的。为了解决这一问题,论文提出了一种名为Fibottention的通用、高效的稀疏架构,它基于斐波那契序列来近似自注意力,具有超线性复杂度,旨在优化ViT在视觉表示学习中的性能和资源利用率。
具体来说,Fibottention的关键策略包括:
-
排除邻近的token以减少冗余。
-
通过设计引入结构化稀疏性以降低计算需求。
-
在不同的注意力头之间引入多样性,确保通过不重叠的token交互捕获补充信息。
通过这些策略,Fibottention能够在只使用自注意力头中2-6%的元素的情况下,与ViT及其变体结合使用,在图像分类、视频理解、机器人学习任务等多个数据集和领域中,相比标准ViT实现显著的性能提升。
论文如何解决这个问题?
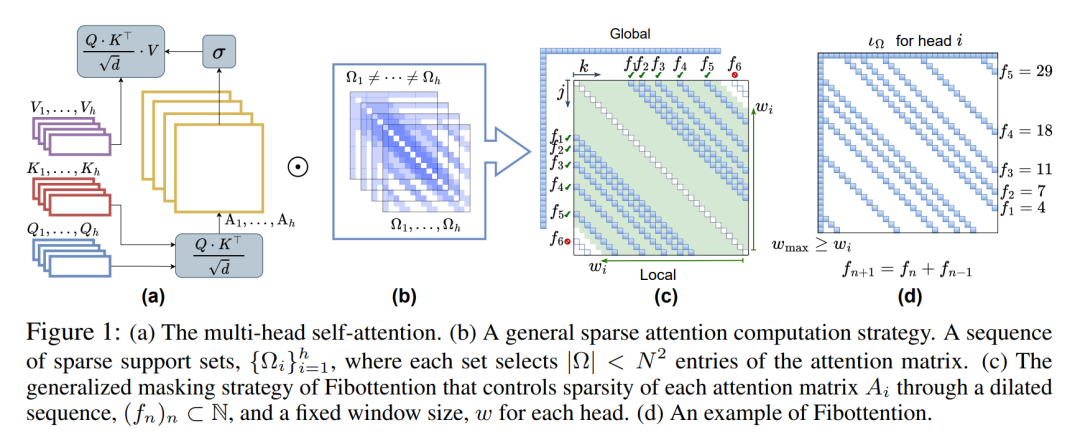
论文通过提出一种名为Fibottention的新型稀疏自注意力机制来解决视觉变换器(ViT)中的计算瓶颈问题。Fibottention的设计基于以下几个关键策略:
-
基于斐波那契数列的稀疏模式:Fibottention利用斐波那契数列来确定token之间的交互模式,从而减少冗余的自注意力计算。这种方法通过排除邻近的token来减少冗余,并采用结构化稀疏性来降低计算需求。
-
多尺度的注意力窗口:通过在不同的注意力头中使用不同大小的窗口,Fibottention能够在不同尺度上捕获局部级别的token信息,这有助于提高视觉任务的性能。
-
多样性的注意力头:Fibottention在不同的注意力头中引入了类似Inception网络的多样性,确保通过非重叠的token交互来捕获补充信息,从而优化性能和资源利用率。
-
高效的计算复杂度:Fibottention的设计目标是实现超线性的计算复杂度,即O(N log N),这比传统的自注意力计算的二次复杂度O(N^2)要低得多。
-
通用性和兼容性:Fibottention被设计为一种通用的、可插拔的自注意力替换方案,可以轻松集成到现有的多种ViT架构中,如vanilla ViT、CVT、Swin Transformer和TimesFormer等。
-
实验验证:论文通过在多个视觉任务(图像分类、视频理解、机器人学习)和数据集上的广泛实验,验证了Fibottention的有效性。实验结果表明,Fibottention在保持或提高性能的同时,显著减少了计算量。
-
代码开源:为了促进社区的进一步研究和开发,作者还公开了Fibottention的代码。
通过这些策略,Fibottention旨在解决ViT在处理大规模视觉数据时面临的计算效率问题,同时保持或提高模型的性能。
论文做了哪些实验?
论文中进行了一系列的实验来评估Fibottention的性能和效率。以下是实验的主要方面:
-
图像分类任务:在CIFAR-10、CIFAR-100和ImageNet-1K等数据集上评估Fibottention的有效性。使用Top-1准确率作为性能指标。
-
不同ViT变体的集成:将Fibottention集成到不同的ViT架构中,包括ViT-Base、ViT-Tiny、Swin-Base和CVT-Base,以展示其在不同模型中的鲁棒性。
-
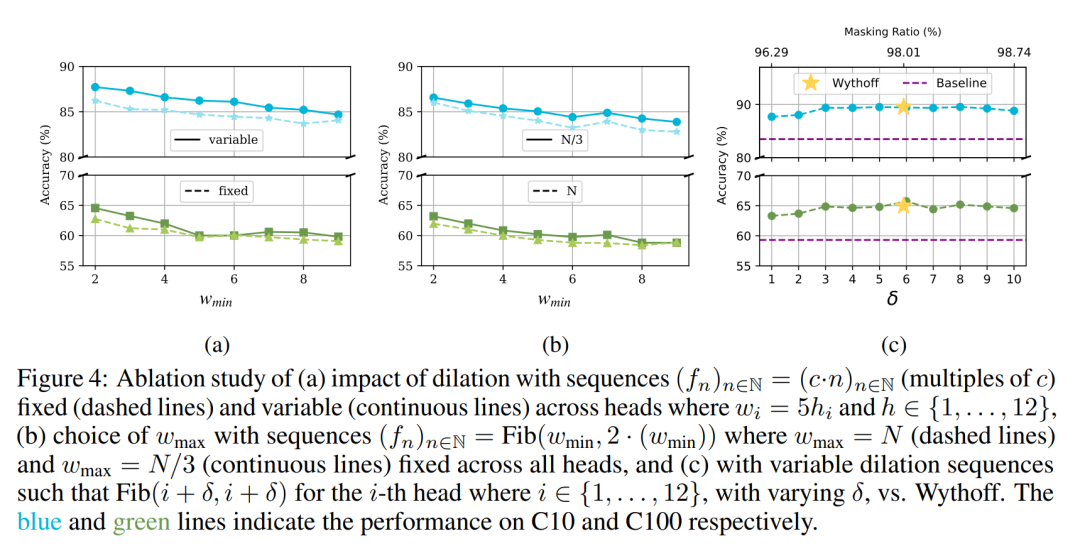
窗口大小的探索:通过改变Fibottention中的窗口大小参数(wmin和wmax),研究其对分类准确率的影响。
-
不同的稀疏注意力模式:比较了不同的稀疏注意力模式,包括Fibottention使用的斐波那契序列和其他序列模式,如2的幂次、3的幂次、平方数列和立方数列。
-
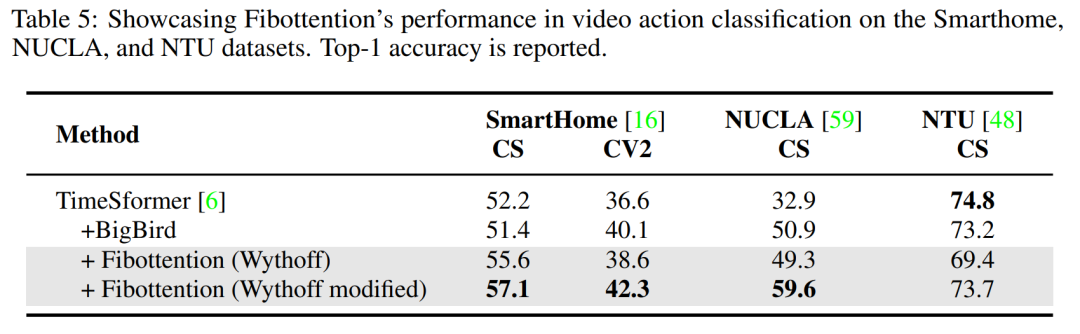
视频动作分类:在Toyota Smarthome、NUCLA和NTU RGB+D等视频数据集上评估Fibottention在视频理解任务中的表现。
-
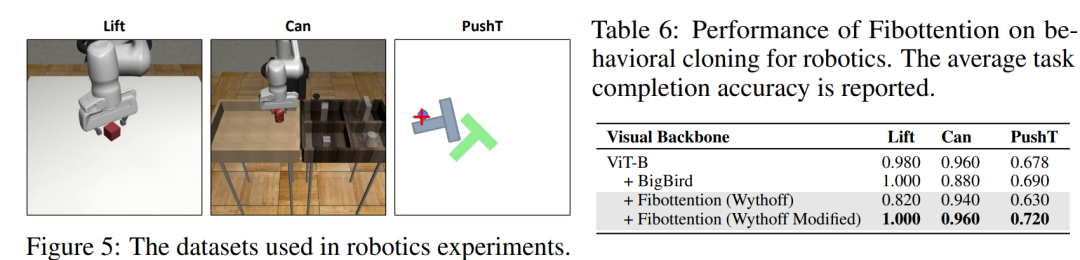
机器人学习任务:在Robomimic和Implicit Behaviour Cloning等机器人学习数据集上测试Fibottention,特别是在行为克隆任务中。
-
性能比较:将Fibottention与其他注意力机制(如BigBird)进行比较,以展示其在不同视觉任务中的性能优势。
-
计算复杂度分析:通过理论分析和实验结果,展示了Fibottention在减少计算量方面的优势。
-
注意力矩阵可视化:通过可视化Fibottention训练前后的注意力矩阵,展示了模型如何集中注意力于图像的特定区域。
-
消融研究:通过一系列的消融实验,分析了Fibottention设计选择的有效性,包括对主对角线的影响、不同窗口大小的组合以及Wythoff序列的选择。
这些实验结果表明,Fibottention在多个视觉任务中都能实现显著的性能提升,同时保持了计算效率,证明了其作为一种有效的稀疏自注意力机制的潜力。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题识别:论文指出了视觉变换器(ViT)架构在处理视觉感知任务时面临的主要问题,即自注意力机制的二次计算复杂度导致的计算瓶颈。
-
Fibottention架构:为了解决这一问题,论文提出了一种新的稀疏自注意力架构Fibottention。该架构基于斐波那契序列设计,通过引入结构化稀疏性和多样性来降低计算复杂度,同时保持或提升性能。
-
关键策略:
-
排除邻近token以减少冗余。
-
使用结构化稀疏性降低计算需求。
-
在不同注意力头中引入多样性,捕获补充信息。
-
-
实验验证:论文通过在多个视觉任务(图像分类、视频理解、机器人学习)和数据集(如CIFAR-10、CIFAR-100、ImageNet-1K等)上的实验,验证了Fibottention的有效性。实验结果表明,Fibottention在减少计算量的同时,能够实现与或超过基线模型的性能。
-
效率与性能:Fibottention通过仅使用自注意力头中2-6%的元素,实现了与ViT及其变体相比的显著性能提升。
-
通用性和兼容性:论文展示了Fibottention可以轻松集成到现有的多种ViT架构中,如vanilla ViT、CVT、Swin Transformer和TimesFormer等。
-
开源代码:为了促进社区的进一步研究和开发,作者公开了Fibottention的代码。
-
未来工作:论文讨论了Fibottention的局限性,并提出了未来工作的方向,包括在大规模数据集上恢复准确性、优化稀疏CUDA内核实现等。
总的来说,这篇论文提出了一种创新的方法来提高ViT架构在视觉任务中的计算效率,同时保持或提升模型性能,为未来在资源受限的环境中部署高效的视觉模型提供了新的可能性。
3.SALVe: Semantic Alignment Verification for Floorplan Reconstruction from Sparse Panoramas

标题: SALVe:从稀疏全景图重建平面图的语义对齐验证
作者:John Lambert, Yuguang Li, Ivaylo Boyadzhiev, Lambert Wixson, Manjunath Narayana, Will Hutchcroft, James Hays, Frank Dellaert, Sing Bing Kang
文章链接:https://arxiv.org/abs/2406.19390
项目代码:https://github.com/zillow/salve

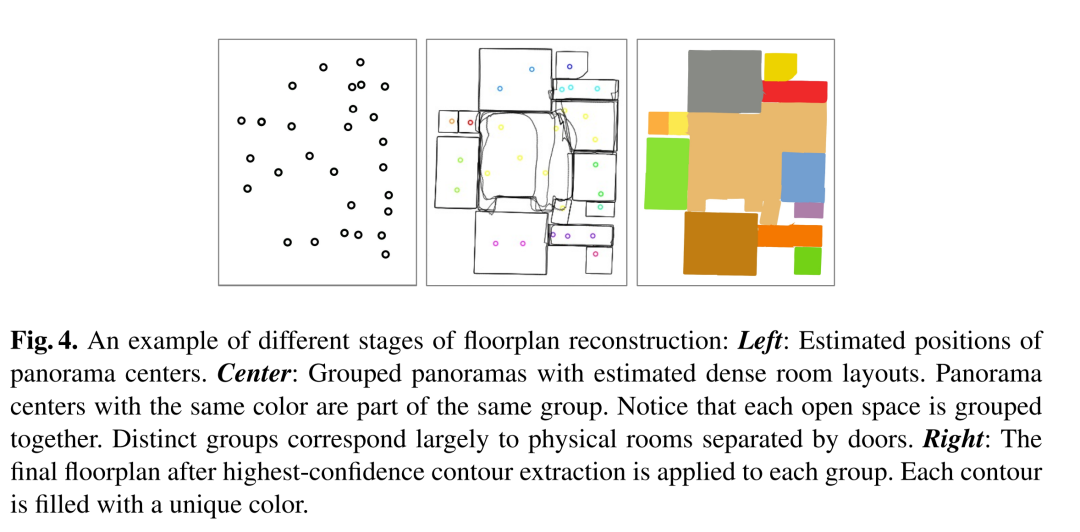
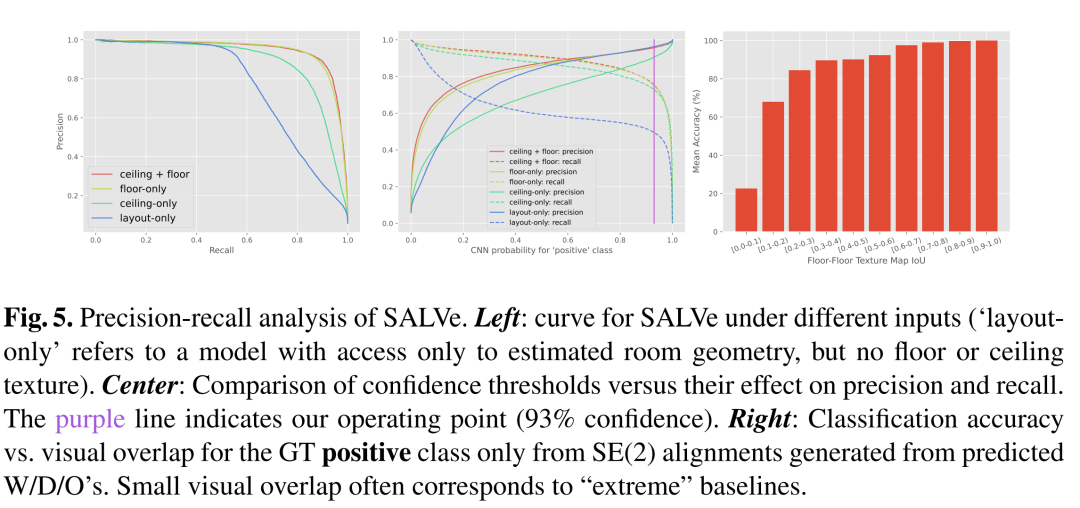

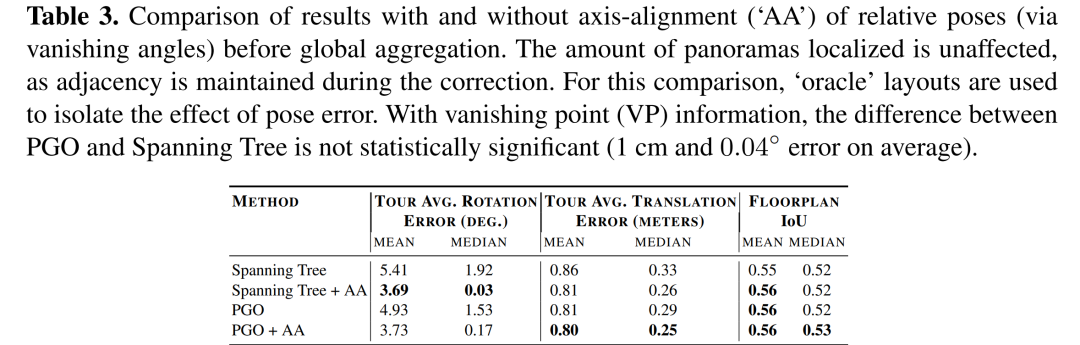


摘要:
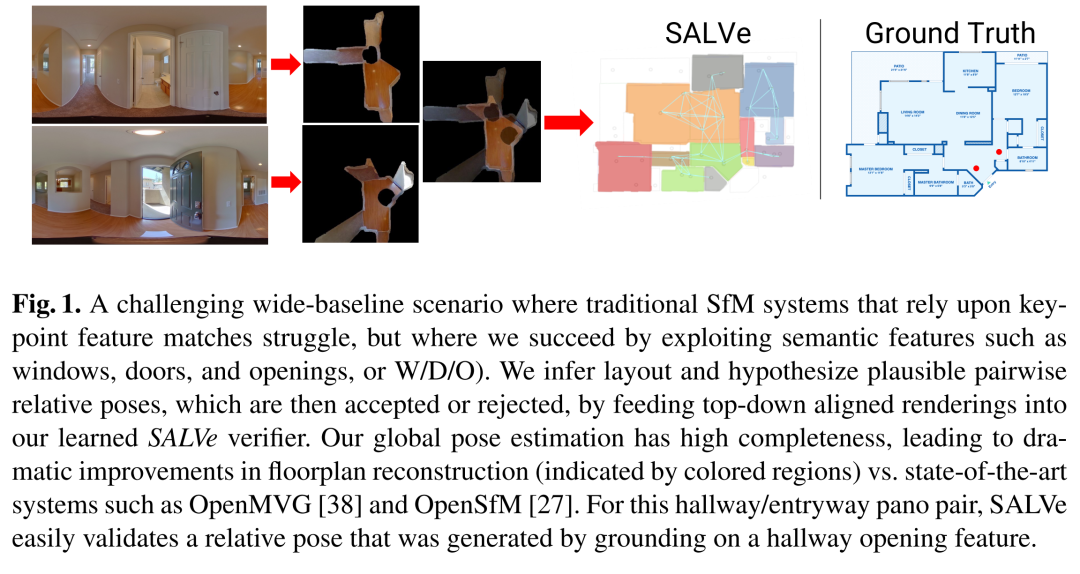
我们提出了一种新的自动 2D 平面图重建系统,该系统由我们新颖的成对学习对齐验证器 SALVe 实现。我们系统的输入是稀疏的 360 度 ∘ 全景图,其语义特征(窗户、门和开口)被推断出来,并用于假设成对的房间邻接或重叠。SALVe 初始化姿态图,随后使用 GTSAM 对其进行优化。计算房间姿势后,将使用 HorizonNet 推断房间布局,并通过拼接最可靠的布局边界来构建平面图。我们通过烧蚀研究对系统的定性和定量进行了验证,表明它在完整性方面比最先进的 SfM 系统高出 200% 以上,同时不牺牲准确性。我们的研究结果指出了我们工作的重要性:81% 的全景图在前 2 个连接组件 (CC) 中定位,89% 在前 3 个 CC 中定位。
这篇论文试图解决什么问题?
这篇论文提出了一个名为SALVe(Semantic Alignment Verification)的系统,旨在解决从稀疏全景图自动重建2D平面图的问题。具体来说,它试图克服以下几个挑战:
-
稀疏输入数据:与传统的结构从运动(Structure-from-Motion, SfM)方法不同,该系统处理的是稀疏捕获的360°全景图,这些图像可能没有足够的视觉重叠,使得传统的基于特征匹配的方法难以应用。
-
高完整性和准确性:传统的SfM方法在室内平面图重建方面往往缺乏完整性,而SALVe系统通过利用语义信息(如窗户、门和开口)来提高重建的完整性和准确性。
-
极端姿态估计:在全景图之间几乎没有视觉重叠的情况下,如何估计它们之间的相对姿态是一个挑战。SALVe通过学习到的语义元素匹配来生成相对姿态假设,并使用深度学习模型来验证这些假设的合理性。
-
全局姿态图优化:一旦计算出相对姿态,如何将它们优化以获得全局一致的姿态图是另一个问题。SALVe使用GTSAM库进行全局优化。
-
平面图构建:最后,如何从优化后的姿态和房间布局中构建平面图也是一个挑战。SALVe通过融合最有信心的布局边界来构建平面图。
总的来说,SALVe系统通过其创新的语义对齐验证器,显著提高了从稀疏全景图中重建室内平面图的完整性和准确性。
论文如何解决这个问题?
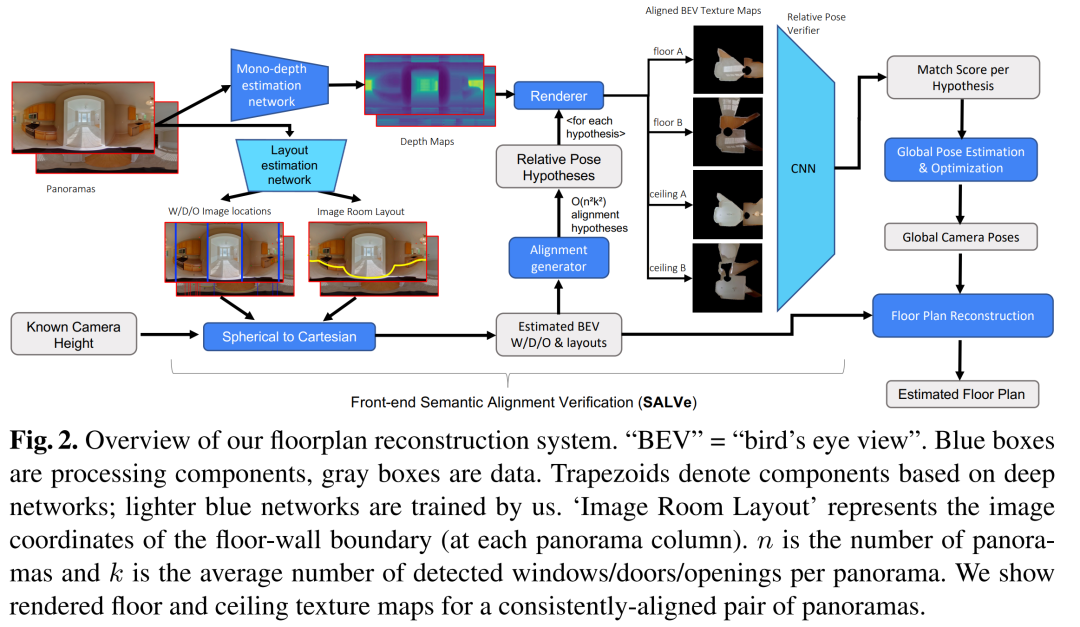
论文通过提出一个名为SALVe(Semantic Alignment Verification)的系统来解决从稀疏全景图自动重建2D平面图的问题。SALVe系统的关键组成部分和解决步骤如下:
-
语义特征推断:系统首先从输入的360°全景图中推断出语义特征,如窗户、门和开口(W/D/O)。这些特征用于假设房间之间的邻接或重叠关系。
-
对齐假设生成:利用检测到的语义对象,系统生成关于全景图之间相对位置的假设。每个语义对象对可以生成两个相对姿态假设,通过在地面平面上对齐它们的中心点,并考虑两种可能的旋转角度。
-
SALVe验证器:SALVe是一个学习到的成对房间对齐验证器,它使用鸟瞰图(BEV)来预测房间对齐的似然分数。给定一个房间对齐的假设,系统会渲染两个全景图的BEV视图,并通过深度卷积神经网络(CNN)来评估它们是否匹配。
-
全局姿态图优化:通过SALVe验证的相对姿态被用来构建一个姿态图,然后使用GTSAM库对这个图进行全局优化,以获得每个全景图在全球坐标系中的姿态。
-
房间布局推断:利用HorizonNet从每个全景图中推断出房间布局,然后根据预测的全景图姿态提取最有信心的房间布局。
-
平面图构建:最后,通过将最有信心的房间布局边界拼接起来,构建出整个平面图。
-
系统验证:通过定性和定量的实验以及消融研究来验证系统的性能,展示了SALVe在完整性和准确性方面相较于现有最先进SfM系统的显著提升。
通过这些步骤,SALVe系统能够处理具有非常大基线的全景图对,并生成比传统SfM技术更完整、更准确的室内平面图。
论文做了哪些实验?
论文中进行了一系列实验来验证SALVe系统的性能和有效性。以下是实验的主要类型和内容:
-
定性分析:通过视觉比较展示了SALVe系统重建的平面图与真实平面图、以及其他系统(如OpenMVG和OpenSfM)的结果之间的差异。
-
定量分析:
-
布局估计和W/D/O检测精度:使用2D IoU(Intersection over Union)来评估预测的房间布局与真实布局之间的相似度,并使用1D IoU来评估窗户、门和开口(W/D/O)检测的准确性。
-
相对姿态分类精度:评估SALVe模型在区分正确和错误对齐假设方面的准确性,包括平均准确率、精确度、召回率和F1分数。
-
全局姿态估计精度和完整性:通过比较估计的姿态图与真实姿态图来评估姿态估计的准确性,包括平移误差和旋转误差,并报告在最大连通分量中定位的全景图的百分比。
-
-
消融研究:展示了不同类型输入对结果的影响,例如仅使用地板或天花板纹理图、仅使用布局信息、以及使用不同的CNN架构。
-
与现有技术的比较:将SALVe系统与现有的SfM系统(如OpenMVG和OpenSfM)进行了比较,以展示其在全局姿态估计和平面图重建方面的性能提升。
-
不同全局姿态估计技术的比较:比较了使用不同全局聚合方法(如最小生成树和姿态图优化)的性能。
-
使用ZInD数据集:使用了Zillow Indoor Dataset(ZInD)进行评估,这是一个大规模的室内全景图数据集,包含了多个房间的全景图、布局和W/D/O注释。
-
评估指标:使用了多种评估指标来全面评估系统的性能,包括布局估计精度、W/D/O检测精度、相对姿态分类精度、全局姿态估计精度和完整性,以及最终的平面图重建精度。
这些实验结果表明,SALVe系统在平面图重建的完整性和准确性方面均优于现有的最先进系统。
论文的主要内容:
这篇论文提出了一个名为SALVe(Semantic Alignment Verification)的系统,用于从稀疏全景图自动重建2D平面图。以下是论文的主要内容总结:
-
问题背景:室内几何重建对于虚拟旅游、建筑分析、虚拟布景和自主导航等多种应用至关重要。然而,传统的基于图像的重建方法存在数据带宽、设备成本和劳动力数量等方面的限制。
-
SALVe系统:SALVe是一个新颖的成对学习对齐验证器,它利用全景图中的语义特征(如窗户、门和开口)来假设房间的邻接或重叠关系,并初始化一个姿态图,随后使用GTSAM进行优化。
-
关键创新:SALVe系统的主要创新在于使用深度学习模型来验证房间对齐的假设。通过渲染鸟瞰图(BEV)并使用CNN评估匹配的合理性,系统能够有效地处理大基线场景。
-
系统流程:SALVe系统的工作流程包括:生成对齐假设、使用SALVe验证器验证假设、全局姿态图优化、房间布局推断和平面图构建。
-
实验验证:通过定性和定量实验以及消融研究,论文展示了SALVe系统在完整性和准确性方面相较于现有最先进SfM系统的显著提升。
-
相关工作:论文回顾了地板平面图重建、SfM和极端基线姿态估计等领域的相关研究,并讨论了SALVe系统的创新之处。
-
实验结果:使用ZInD数据集进行的实验表明,SALVe系统在全局姿态估计的准确性和完整性方面均优于现有的SfM系统。
-
讨论与未来工作:论文讨论了SALVe系统的潜在改进方向,包括提高相机定位完整性、处理具有家具的室内环境、优化运行时间等。
-
伦理和社会影响:论文最后讨论了平面图重建技术在隐私保护、数据安全和社会影响方面的责任和挑战。
总的来说,SALVe系统通过结合语义特征和深度学习技术,为室内平面图重建领域提供了一种新颖且有效的解决方案。
















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











