






InceptionV3在InceptionV2的基础上将标准的卷积操作分解为1xN卷积和Nx1卷积两个步骤,这种分解模式可以显著降低参数量和计算量,同时在一定程度上保持了特征提取的能力。

InceptionV3A与InceptionV2结构相同,即5x5卷积使用两个3x3的卷积代替,目的是减少参数量和计算量——大卷积分解成小卷积。


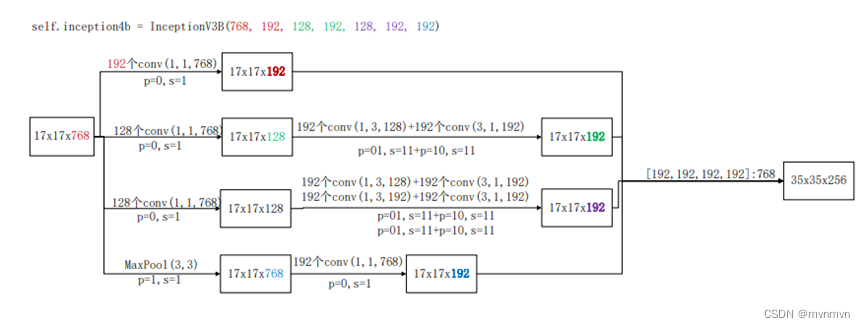
InceptionV3B将InceptionV2结构中3x3的卷积使用1x3和3x1的卷积组合来代替,5x5的卷积使用俩个1x3和3x1的卷积组合来代替,目的也是减少参数量和计算量———小卷积分解为非对称卷积。
采用这种分解在模型的早期网络层上不能有效发挥作用,但是在中等特征图大小(m×m,其中m在12和20之间的范围)上取得了非常好的效果。
使用3x3的卷积代替5x5的卷积,输入512通道特征图,输出128通道特征图:
参数量:512×3×3×128+128×3×3×128=737280
计算量:512×3×3×128×W×H+128×3×3×128×W×H=737280×W×H
W×H是特征图尺寸,假设卷积层的输入输出特征图尺寸保持一致
使用1x3和3x1的卷积组合代替5x5的卷积,输入512通道特征图,输出128通道特征图:
参数量:512×1×3×128+128×3×1×128+128×1×3×128+128×3×1×128=344064
计算量:512×1×3×128×W×H+128×3×1×128×W×H+128×1×3×128×W×H+128×3×1×128×W×H=344064×W×H
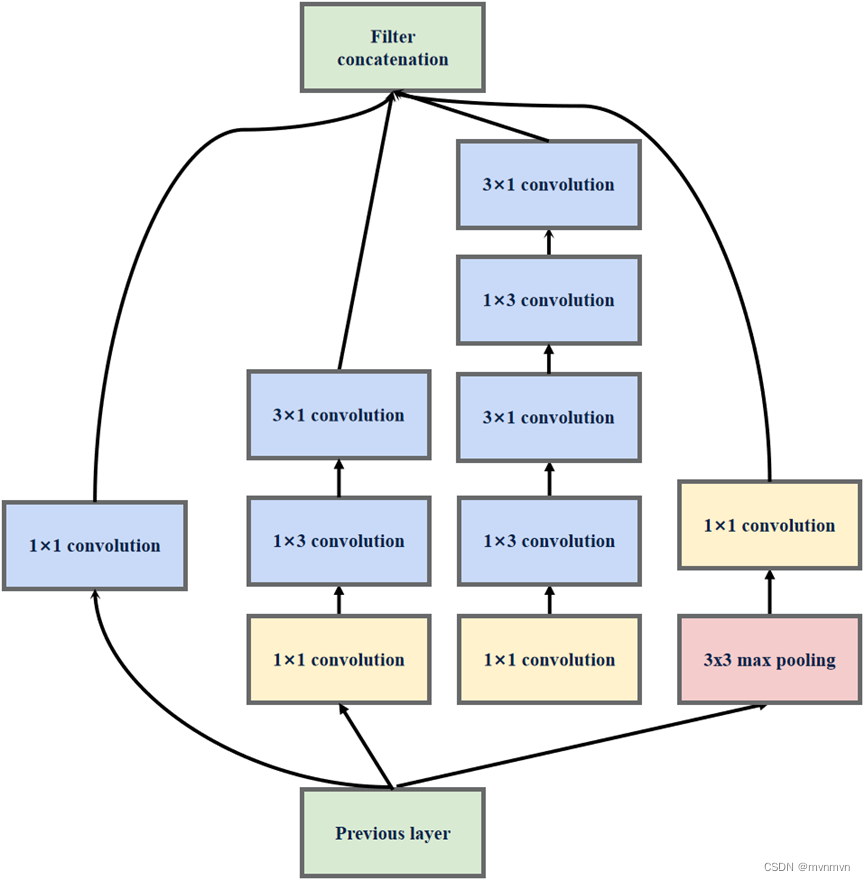
InceptionV3C该结构主要用于扩充通道数,网络变得更宽,该结构被放置在所以放在GoogLeNet(InceptionV3)的最后。


import torch.nn as nn
import torch
from torchsummary import summary
import cv2
from torchvision import transforms
class GoogLeNetV3(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNetV3, self).__init__()
self.aux_logits = aux_logits
# 3个3×3卷积替代7×7卷积
self.conv1_1 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.conv1_2 = BasicConv2d(32, 32, kernel_size=3, stride=1)
self.conv1_3 = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1)
# 池化层
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 80, kernel_size=3)
self.conv3 = BasicConv2d(80, 192, kernel_size=3, stride=2)
self.conv4 = BasicConv2d(192, 192, kernel_size=3, padding=1)
self.inception3a = InceptionV3A(192, 64, 48, 64, 64, 96, 32)
self.inception3b = InceptionV3A(256, 64, 48, 64, 64, 96, 64)
self.inception3c = InceptionV3A(288, 64, 48, 64, 64, 96, 64)
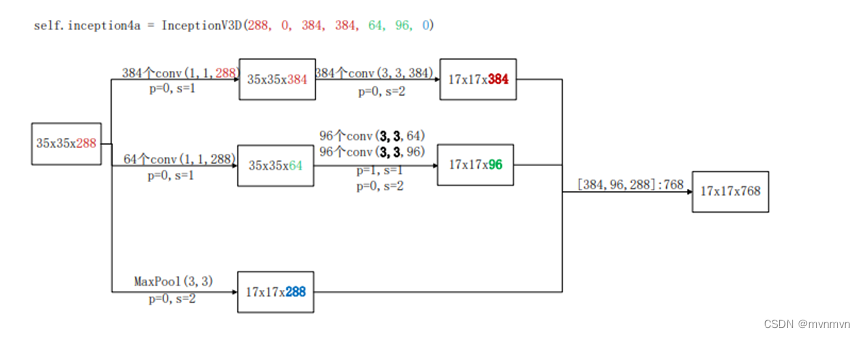
self.inception4a = InceptionV3D(288, 0, 384, 384, 64, 96, 0)
self.inception4b = InceptionV3B(768, 192, 128, 192, 128, 192, 192)
self.inception4c = InceptionV3B(768, 192, 160, 192, 160, 192, 192)
self.inception4d = InceptionV3B(768, 192, 160, 192, 160, 192, 192)
self.inception4e = InceptionV3D(768, 0, 384, 384, 64, 128, 0)
if self.aux_logits == True:
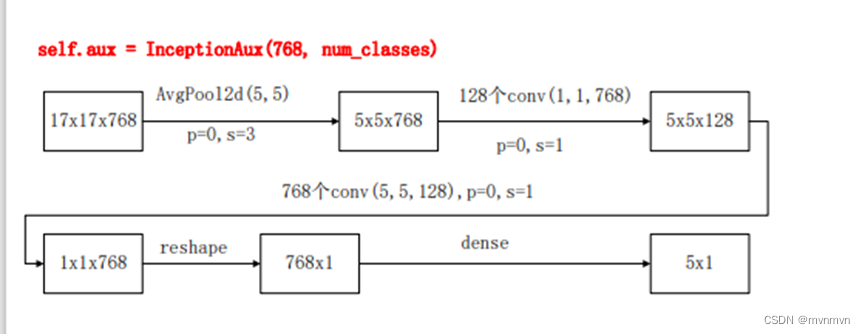
self.aux = InceptionAux(in_channels=768, out_channels=num_classes)
self.inception5a = InceptionV3C(1280, 320, 384, 384, 448, 384, 192)
self.inception5b = InceptionV3C(2048, 320, 384, 384, 448, 384, 192)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.5)
self.fc = nn.Linear(2048, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# #[16,3,224,224]调整为[16,3,299,299]
# hwsize = 299
# x2 = torch.randn(16,3,hwsize,hwsize)
# for m in range(x.shape[0]):
# tmp = x[m, :, :, :] #tensor([3,224,224])
# mintmp = torch.min(tmp)
# maxtmp = torch.max(tmp)
# tmp2 = (tmp- mintmp)/maxtmp #/maxtmp
# if 1:
# toPIL = transforms.ToPILImage() # 这个函数可以将张量转为PIL图片,由小数转为0-255之间的像素值
# img_PIL = toPIL(tmp2) # 张量tensor转换为图片
# img_PIL.save('random.jpg') # 保存图片;img_PIL.show()可以直接显示图片
# img = cv2.imread('random.jpg', 1) # 0代表单通道,1代表3通道
# else:
# img = self.tensor_to_image(tmp2)
#
# img2 = cv2.resize(img, (hwsize, hwsize))
# # toTensor = transforms.ToTensor()#图片转换为张量tensor
# # img_tensor = toTensor(img)
# img3 = torch.tensor(img2).float()
# img4 = img3 / 255.0
# img5 = img4.permute(2,0,1)
# img6 = img5 * maxtmp + mintmp
# x2[m,:,:,:]=img6
# s=1
# x = x2
# N x 3 x 299 x 299
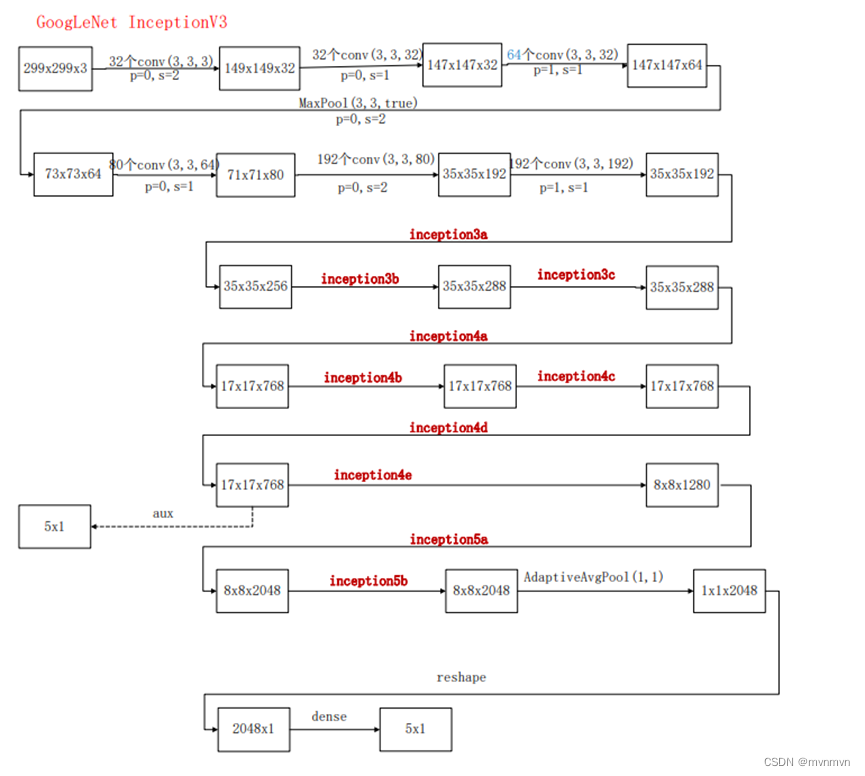
x = self.conv1_1(x)
# N x 32 x 149 x 149
x = self.conv1_2(x)
# N x 32 x 147 x 147
x = self.conv1_3(x)
# N x 64 x 147 x 147
x = self.maxpool1(x)
# N x 64 x 73 x 73
x = self.conv2(x)
# N x 80 x 71 x 71
x = self.conv3(x)
# N x 192 x 35 x 35
x = self.conv4(x)
# N x 192 x 35 x 35
x = self.inception3a(x)
# N x 256 x 35 x 35
x = self.inception3b(x)
# N x 288 x 35 x 35
x = self.inception3c(x)
# N x 288 x 35x 35
x = self.inception4a(x)
# N x 768 x 17 x 17
x = self.inception4b(x)
# N x 768 x 17 x 17
x = self.inception4c(x)
# N x 768 x 17 x 17
x = self.inception4d(x)
# N x 768 x 17 x 17
if self.training and self.aux_logits: # eval model lose this layer
aux = self.aux(x)
# N x 768 x 17 x 17
x = self.inception4e(x)
# N x 1280 x 8 x 8
x = self.inception5a(x)
# N x 2048 x 8 x 8
x = self.inception5b(x)
# N x 2048 x 8 x 8
x = self.avgpool(x)
# N x 2048 x 1 x 1
x = torch.flatten(x, 1)
# N x 2048
x = self.dropout(x)
x = self.fc(x)
# N x 1000(num_classes)
if self.training and self.aux_logits: # 训练阶段使用
return x, aux
return x
# 对模型的权重进行初始化操作
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# InceptionV3A:BasicConv2d+MaxPool2d
class InceptionV3A(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):
super(InceptionV3A, self).__init__()
# 1×1卷积
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
# 1×1卷积+3×3卷积
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
# 1×1卷积++3×3卷积+3×3卷积
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),
BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),
BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
# 3×3池化+1×1卷积
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 拼接
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# InceptionV3B:BasicConv2d+MaxPool2d
class InceptionV3B(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):
super(InceptionV3B, self).__init__()
# 1×1卷积
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
# 1×1卷积+1×3卷积+3×1卷积
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1]),
BasicConv2d(ch3x3, ch3x3, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小
)
# 1×1卷积+1×3卷积+3×1卷积+1×3卷积+3×1卷积
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),
BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]),
BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]),
BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]),
BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小
)
# 3×3池化+1×1卷积
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 拼接
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# InceptionV3C:BasicConv2d+MaxPool2d
class InceptionV3C(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):
super(InceptionV3C, self).__init__()
# 1×1卷积
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
# 1×1卷积+1×3卷积+3×1卷积
self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1)
self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1])
self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0])
# 1×1卷积+3×3卷积+1×3卷积+3×1卷积
self.branch3_0 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),
BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),
)
self.branch3_1 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1])
self.branch3_2 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0])
# 3×3池化+1×1卷积
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2_0 = self.branch2_0(x)
branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1)
branch3_0 = self.branch3_0(x)
branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1)
branch4 = self.branch4(x)
# 拼接
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# InceptionV3D:BasicConv2d+MaxPool2d
class InceptionV3D(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):
super(InceptionV3D, self).__init__()
# ch1x1:没有1×1卷积
# 1×1卷积+3×3卷积,步长为2
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2)
)
# 1×1卷积+3×3卷积+3×3卷积,步长为2
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),
BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), # 保证输出大小等于输入大小
BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, stride=2)
)
# 3×3池化,步长为2
self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))
# pool_proj:池化层后不再接卷积层
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 拼接
outputs = [branch1,branch2, branch3]
return torch.cat(outputs, 1)
# 辅助分类器:AvgPool2d+BasicConv2d+Linear+dropout
class InceptionAux(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv1 = BasicConv2d(in_channels=in_channels, out_channels=128, kernel_size=1)
self.conv2 = BasicConv2d(in_channels=128, out_channels=768, kernel_size=5, stride=1)
self.dropout = nn.Dropout(p=0.7)
self.linear = nn.Linear(in_features=768, out_features=out_channels)
def forward(self, x):
# N x 768 x 17 x 17
x = self.averagePool(x)
# N x 768 x 5 x 5
x = self.conv1(x)
# N x 128 x 5 x 5
x = self.conv2(x)
# N x 768 x 1 x 1
x = x.view(x.size(0), -1)
# N x 768
out = self.linear(self.dropout(x))
# N x num_classes
return out
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = GoogLeNetV3().to(device)
summary(model, input_size=(3, 299, 299))















 5185
5185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









