







MySql 数据存储概述
MySQL是一款数据持久型数据库,数据存储是在磁盘当中的,但是鉴于数据库的高性能要求直接使用磁盘进行数据操作这显然是不能够满足的,因此基于缓存的优化就必不可少了,涉及有 bufferPool,changeBuffer,三大缓存链表 等,又基于数据的一致性考虑(内存与磁盘数据一致),引入了redoLog 体系
数据是以怎样的数据结构存储的(基于innoDB引擎下)
1、当新建一张表时,如下图在MySQL data 文件夹中会建立以表名为名称的如下后缀的两个文件

2、数据存储结构构成
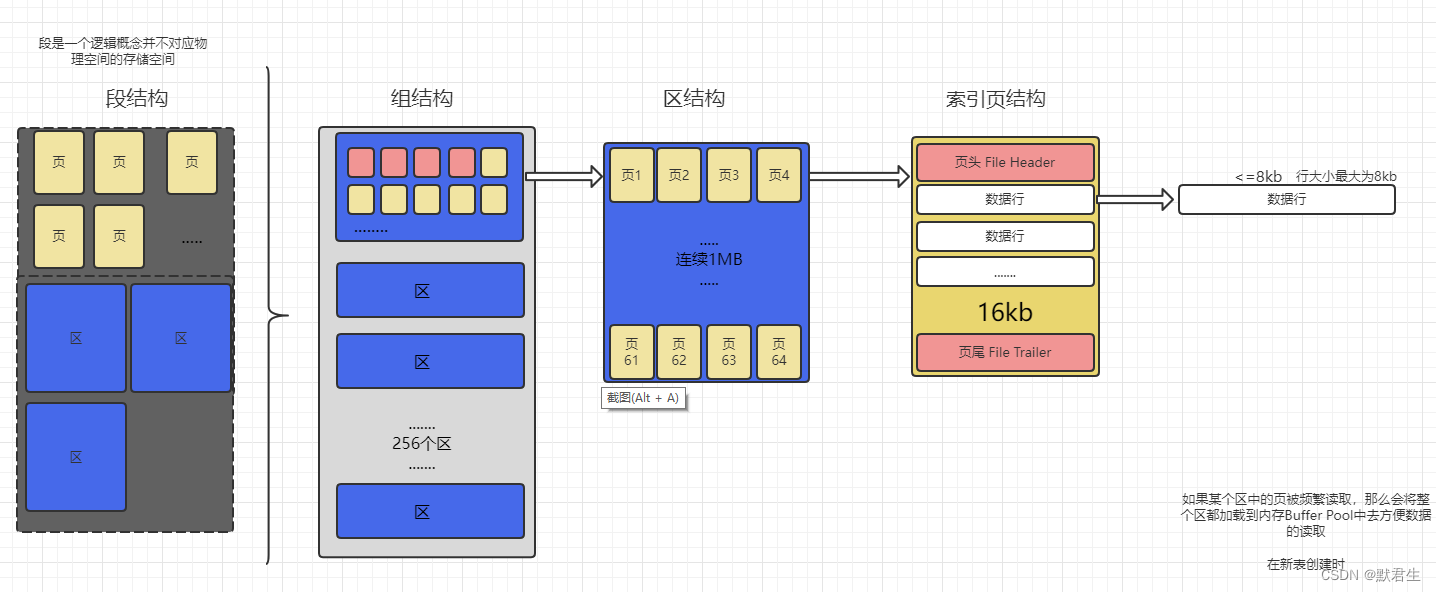
这里的结构设计大多是在考虑机械硬盘的读取效率问题,将相关的数据聚集区分尽可能的避免随机IO的发生。
在缓存的应用上围绕这“局部性原理”所作的缓存预加载也是尽可能的避免过多的IO操作导致新能下降
此处有个问题:跨页读取问题
数据是存储在页上的,如果多个页在物理存储上的距离过大就会造成不同磁道上读取数据,会造成磁盘磁头的的移动,这种物理摆动会大大的影响数据的读取效率,因此需要在磁道上尽量读取连续数据,减少磁头的移动
解决:
采用“区”结构使用1MB存储64个页,这样即使跨页读取相关数据,在同一个或多个区的可能性高,那么地址就都是连续的了,大大降低了磁头移动寻址的可能。
3、数据交互最小端元“页” 的结构
数据也是MySQL中磁盘与内存交互的最小数据单元,默认大小为16kb,可以更改不过要为操作系统交互单元PageCache 4kb 的整数倍,也就是说你要查询一条数据对于缓存来说它拿到的是16kb数百条数据,因为内存向磁盘要数据最少都要是16kb
- -页结构如图
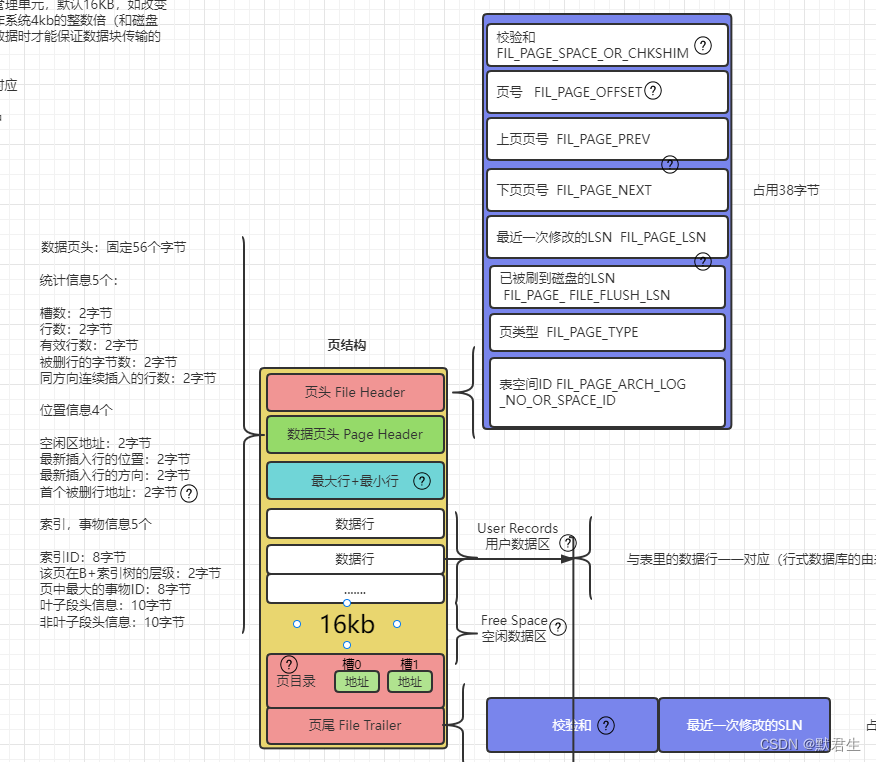
页号: 全局唯一,占用4个字节,(1字节8比特,可以推断)每个INNODB种最多可以拥有 2^(4*8)-1 约42亿个页,以每页默认的16kb来计算,可以计算出存储上限约63TB
** 上下页号:** 组成双向链表的特定结构
校验和: 一个页的完整传输的校验值
LSN: LSN(log sequence number):日志序列号,在数据页头部,LSN记录当前页最后一次修改的LSN号,用于在recovery时对比重做日志LSN号决定是否对该页进行恢复数据。record_type 分别为2,3
最大行+最小行: 页创建默认存在,这两行不存储真实数据作为数据行链表的头和尾
用户数据区: 被数据行占用的区域
空闲数据区: 未被数据行占用的区域
首个被删行地址: 垃圾链表的头节点
页目录: 优化页种数据查找的一种结构,页种的槽记录了已8条数据为一组的最后一条数据的地址信息,查找数据时能以二分法先查找对应的槽后遍历其中最多八条数据
问题:页在操作系统中的读取原子性问题
数据在操作系统上传输通常是以4kb为一个数据块来传输的,如果在传输的过程种一个页的16kb在操作系统层面(操作系统page cache 传输块为4kb)如果在一个页的传输过程种被中断就会产生残缺的页数据,造成数据的不一致。
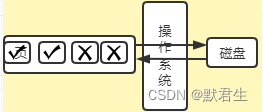
解答:通过页头和页尾的校验和以CRM32算法校验数据的完整性,以确保数据页交互操作的完整性。(页是存储引擎与内存和磁盘交互数据的最小单元,必须保证其数据传输的原子性)
页是B+树的对应节点,也就是说B+树上一个节点就是一个页数据16kb ,B+树最终索引到的是某一个页数据,要查找到具体的某一行数据仍然需要在对应的页中再次进行查找*
那么页内数据是如何查找的呢?我们看一下下面的问题。
问题:一个数据页有16kb大小,其中的数据通常也是有数百行的单向链表,那么在一个具体的数据页种查找某一条数据也是要索引数百次的,这样的效率显然是不满足数据查找的高性能要求的,MySQL 内部是如何优化的呢?
**解答:MySQL 在页内部有一块 “页目录”区域,将数据行以8行为一组将最后一行的地址记录在 其种的“槽”结构上,为了快速判断数据是否到达8个的上限,是否开辟新的 “槽”,在每个行的最后一条数据种用 n_owned 记录了这个 “槽”内的行数量。
当查询数据时,如有10条数据,其中最小行(Infimum )独占一个槽,1~8 数据行一组占一个槽,9,10 数据行加最大行(Supremum )占用一个槽,共三个槽 **
结构如下
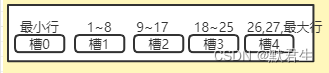
查找时以二分法查找到对应的槽,后遍历其中的八条数据找到对应的数据行
((查找槽+最大槽)/2)=下一个比较槽
查找id为19的数据:(0+4)/2 =2,在槽2提取记录数据的id值比较 17<19,再次计算(2+4)/2=3,提取id比较 25>19 即确定数据在槽3中 遍历其中八条数据找到19,完成查询
因为以上疑问,所以MySQL在页结构中增加了 “页目录区域” 用以页内数据查找
4、最后是数据最终存放的“行”结构了

据以上图中可以看出,MySQL 对空值(NULL)是有经行特殊处理的以节省存储空间,对于超大字段的存储也是经过溢出页处理的。
总结
MySQL 结构上分为 段(逻辑)——>组——>区——>页——>行,的存储层级,辅以B+树的数据结构关联所有页,业内行数据首尾相连辅以“页目录”进行二分查找,其以上结构核心皆在提升其数据的查询性能。
以上内容如有谬误或歧义欢迎评论指导















 6263
6263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









