







引言
在现代编程中,Lambda表达式(也称为匿名函数或闭包)已经成为了一种非常流行的编程范式。它允许我们定义简短、一次性的函数对象,而无需显式地定义它们。在C++11及之后的版本中,Lambda表达式得到了官方的支持,为C++程序员带来了极大的便利。本文将详细解释Lambda表达式的概念、语法以及如何使用它们。
Lambda表达式的概念
Lambda表达式是一种匿名函数,即没有具体名称的函数。它可以捕获其所在作用域的变量,并在需要时执行特定的操作。Lambda表达式通常用于实现回调函数、并行计算、排序算法等场景。
Lambda表达式的语法
Lambda表达式的语法相对简单,其基本形式如下:
[capture](parameters) -> return_type { body }
[capture]:捕获子句,用于指定Lambda表达式可以访问的外部变量及其访问方式(值捕获或引用捕获)。(parameters):参数列表,与普通函数的参数列表类似,用于指定Lambda表达式的输入参数。-> return_type:返回类型说明符,用于指定Lambda表达式的返回类型。如果Lambda表达式的返回类型可以由编译器自动推导,则可以省略该部分。{ body }:Lambda表达式的主体,即函数体,包含要执行的代码。
Lambda表达式的使用
下面我们将通过几个示例来演示Lambda表达式的使用。
示例1:无参数、无返回值的Lambda表达式
#include <iostream>
int main() {
auto lambda = [] {
std::cout << "Hello, Lambda!" << std::endl;
};
lambda(); // 调用Lambda表达式
return 0;
}在这个示例中,我们定义了一个无参数、无返回值的Lambda表达式,并将其赋值给lambda变量。然后,我们像调用普通函数一样调用lambda()。
示例2:有参数、有返回值的Lambda表达式
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::sort(numbers.begin(), numbers.end(), [](int a, int b) {
return a < b; // 定义了比较函数
});
// 输出排序后的结果
for (int num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}在这个示例中,我们使用了一个Lambda表达式作为std::sort函数的第三个参数。这个Lambda表达式接受两个整数参数a和b,并返回一个布尔值,用于指示a是否小于b。通过这种方式,我们告诉std::sort函数如何对整数进行排序。
示例3 -- 对回调函数使用lambda 表达式
原程序
#include<iostream>
using namespace std;
bool compare(int a,int b){ // 比较前者是否大于后者
return a>b;
}
// 回调函数 -- 获取两数的最大值
int getMax(int a,int b,bool(*compare)(int a,int b))
{
if(compare(a,b)){
return a;
}
else
return b;
}
int main()
{
int a = 55,b=99;
bool (*funcp)(int ,int ) = compare;
cout<<getMax(a,b,funcp)<<endl;
return 0;
}改进为 lambda 表达式
// 接下来- 我们 可以吧compare 这个函数 改进为 lambda 表达式:
int main()
{
int a = 555,b=99;
//bool (*funcp)(int ,int ) = compare;
cout<<getMax(a,b, [](int a,int b) ->bool {
return a>b;})<<endl;
return 0;
}
在这个例子中:
getMax 函数接受两个整数 a 和 b ,以及一个比较函数 compare 。这个比较函数是一个指向函数
的指针,它接受两个整数并返回一个布尔值。
在 main 函数中,我们调用 getMax ,并直接在调用点定义了一个匿名的 lambda 函数。这个
lambda 函数接受两个整数并返回一个表示第一个整数是否大于第二个整数的布尔值。
这个 lambda 函数在 getMax 中被用作比较两个数的逻辑。根据 lambda 函数的返回值, getMax
返回较大的数。
这个例子展示了如何直接在函数调用中使用匿名 lambda 函数,使代码更加简洁和直接。这种方法在需
要临时函数逻辑的场合非常有用,尤其是在比较、条件检查或小型回调中。
在 Lambda 表达式中,参数捕获是指 Lambda 表达式从其定义的上下文中捕获变量的能力。这使得
Lambda 可以使用并操作在其外部定义的变量。捕获可以按值(拷贝)或按引用进行。
让我们通过一个简单的示例来展示带参数捕获的 Lambda 表达式。
Lambda 表达式的捕获列表
三种捕获方式
第一种捕获方式: [x,y] --> 指定变量捕获
auto add=[x,y]()->int{
return x +y;
}
第二种捕获方式: --> = 一键全部
auto mul=[=]()->int{ // = 捕获上面的所有变量
//x++; //这种方式的捕获是没法修改变量的值 --> 可读 只能使用
//y = 10;
return x*y*z;
};
第三种捕获方式: --> & 一键全部,并且能拿到他们的地址,进行修改
auto modifAndMul=[&]()->int{ // = 捕获上面的所有变量
y = 10; //可读可写
return x*y*z;
};全部整合实例代码;
#include <iostream>
using namespace std;
int main()
{
int x = 10;
int y = 30;
auto add=[x,y]()->int{
//x++; //这种方式的捕获是没法修改变量的值 --> 可读 只能使用
//y = 10;
return x +y;
};
cout << add()<<endl;
int z = 5;
auto mul=[=]()->int{ // = 捕获上面的所有变量
//x++; //这种方式的捕获是没法修改变量的值 --> 可读 只能使用
//y = 10;
return x*y*z;
};
int c=66; // 下面的定义的变量 = 就捕获不到 --> 但是不了的 初始化一般都设置在函数的开头
cout << mul()<<endl;
// 用引用的方式来进行捕获,类似指针,进行地址访问
auto modifAndMul=[&]()->int{ // = 捕获上面的所有变量
y = 10; //可读可写
return x*y*z;
};
cout << modifAndMul()<<endl<<"y = "<<y<<endl;;
return 0;
}输出结果:
说明
在这个例子中:
第一个 Lambda 表达式 sum 按值捕获了 x 和 y (即它们的副本)。这意味着 sum 内的 x 和 y
是在 Lambda 定义时的值的拷贝。
第二个 Lambda 表达式 multiply 使用 [=] 捕获列表,这表示它按值捕获所有外部变量。
第三个 Lambda 表达式 modifyAndSum 使用 [&] 捕获列表,这表示它按引用捕获所有外部变量。
因此,它可以修改 x 和 y 的原始值。
这个示例展示了如何使用不同类型的捕获列表(按值和按引用)来控制 Lambda 表达式对外部变量的访问和修改。按值捕获是安全的,但不允许修改原始变量,而按引用捕获允许修改原始变量,但需要注意引用的有效性和生命周期问题。
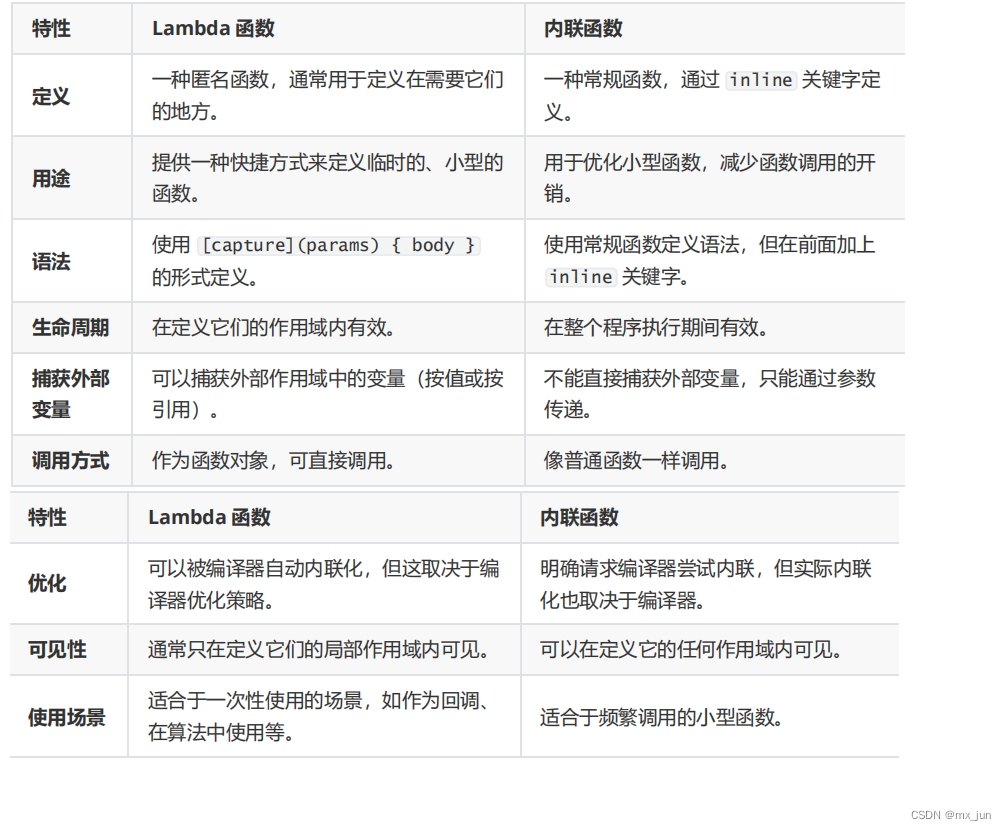
请注意,虽然 Lambda 函数和内联函数在某些方面有相似之处,如它们都可以被编译器优化以减少调用开销,但它们在设计和用途上有明显的不同。Lambda 函数的核心优势在于它们的匿名性和对外部变量的捕获能力,而内联函数则主要关注于提高小型函数的性能。
内联函数
概念
内联函数(Inline Function)是C++中一种特殊的函数,其定义直接在每个调用点展开。这意味着编译器会尝试将函数调用替换为函数本身的代码,这样可以减少函数调用的开销,尤其是在小型函数中。
特点
1. 减少函数调用开销:内联函数通常用于优化小型、频繁调用的函数,因为它避免了函数调用的常规开销(如参数传递、栈操作等)。
2. 编译器决策:即使函数被声明为内联,编译器也可能决定不进行内联,特别是对于复杂或递归函数。
3. 适用于小型函数:通常只有简单的、执行时间短的函数适合做内联。4. 定义在每个使用点:内联函数的定义(而非仅仅是声明)必须对每个使用它的文件都可见,通常意味着将内联函数定义在头文件中。
使用方法
通过在函数声明前添加关键字 inline 来指示编译器该函数适合内联:
inline int max(int x, int y) {
return x > y ? x : y;
}
示例
#include <iostream>
inline int add(int a, int b) {
return a + b;
}
int main() {
int result = add(5, 3); // 编译器可能会将此替换为:int result = 5 + 3;
std::cout << "Result: " << result << std::endl;
return 0;
}在这个示例中,函数 add 被定义为内联函数。当它被调用时,编译器可能会将函数调用替换为函数体内的代码。
注意事项
过度使用的风险:不应滥用内联函数,因为这可能会增加最终程序的大小(代码膨胀)。对于大型函数或递归函数,内联可能导致性能下降。
编译器的决定:最终是否将函数内联是由编译器决定的,即使函数被标记为 inline 。
适用场景:最适合内联的是小型函数和在性能要求高的代码中频繁调用的函数。
内联函数是一种用于优化程序性能的工具,但需要合理使用,以确保代码的可维护性和性能的平衡。
Lambda 函数和内联函数在 C++ 中的相似之处和区别:















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









