







场景题
一、项目
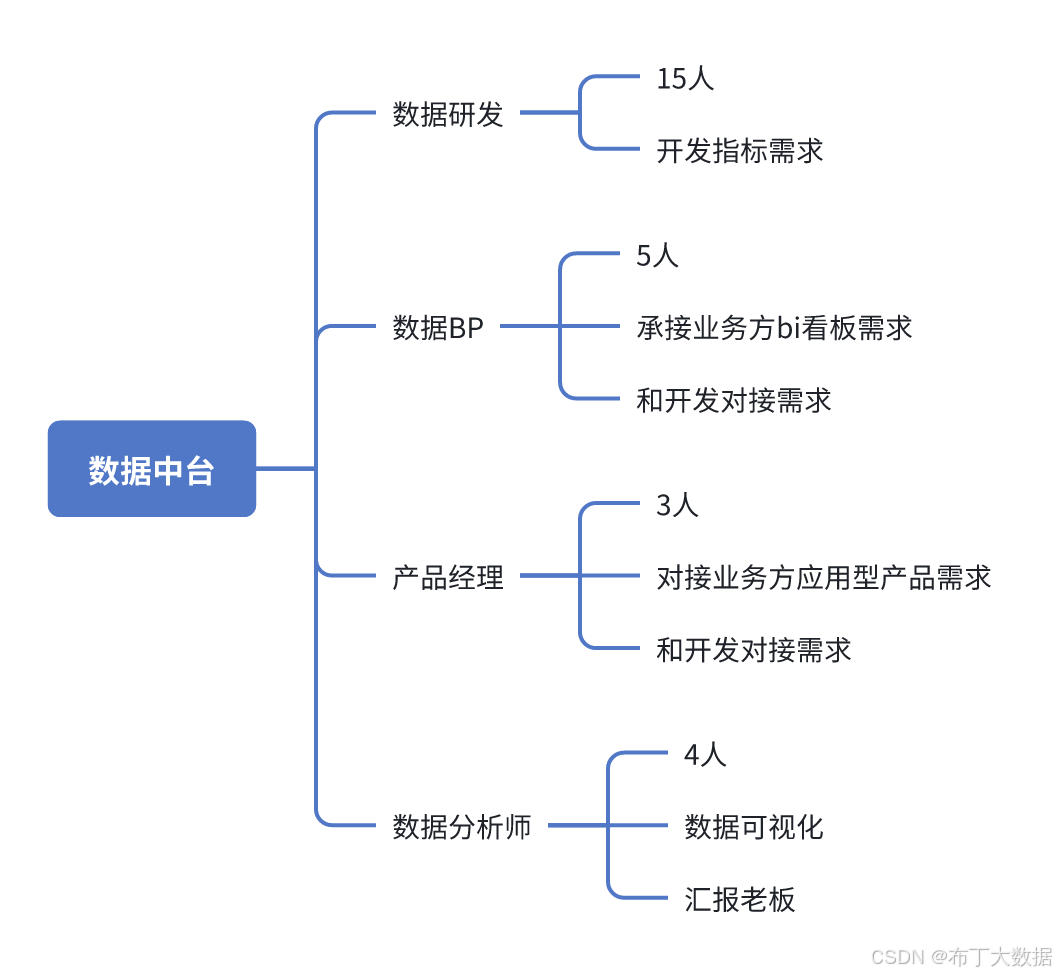
1. 部门架构?
2. 数仓开发流程?
2.1 和产品/业务对接需求,通过需求评审会和产品、后端、前端一起评审需求
2.2 梳理数据源&上下游现状,沟通指标的开发维度、周期、使用者的角色等等细节,撰写技术方案、接口文档和开发文档,进行人天工作量排期,飞书项目管理项目进度和指标口径文档等
2.3 开发模型,梳理模型,有无现成数据源的字段可以使用,无现成字段需新接入数据源(通过API或者datax同步数据源到数仓中),有数据源直接开发中间层和应用层
2.4 自己数据校验、后端测试联调测试、业务验证数据
2.5 dqc质量监控配置,数据有效性、唯一性、一致性
2.6 开上线会,各方对齐完成进度以及卡点,任务上线,回刷数据,app版本更新
3. 介绍项目,你在项目中担任的职责、作出的成果,以及遇到的挑战和解决办法?
例:
我在数据中台,主要负责内部数据app产品的交易域/财务域的离线指标开发
在我来的时候,这里的数据仓库建设体系已经相对成熟,我除了做一些日常的需求指标开发之外,额外做了一些性能优化、数据治理、和质量监控的工作,使得整个数仓体系更加健全。
比如像性能优化这个点,我们使用的是dataworks进行开发指标的,本身其实它的计算引擎maxcompute性能已经优化的挺好的了,但是对于一些数据量较大的单分区上亿级别的表来说的话,执行任务耗费时间会较长可能达到半小时,我们一般的任务基本上是秒级别,延迟一点的5分钟以内基本上也完成了。这种大表我的优化策略首先是通过日志诊断慢sql的原因,是数据倾斜,还是小文件过多,还是单个map/reduce任务产生的切片/实例数量过多,导致整体任务时长延长,定位出具体的问题之后,再通过相应的手段去解决。像数据倾斜的话,一般可以通过使用随机前缀或后缀、二次MapReduce、提前使用Combiner等解决。小文件过多的话可以手动执行命令进行小文件的合并等等,任务产出时间提前了将近一半。
除了任务产出的时间优化,还有查询性能优化,我们有部分指标数据是通过接口传递给后端的,之前的架构是一个接口里面融合了几百个指标,查询数据量较大,导致前端页面查询数据时耗时较长,有的要一次3-5秒,用户体验较差。我通过近1年数据加redis缓存、接口里使用事先预计算的物化视图、去除现在接口中不需要的部分逻辑,来减少数据的扫描量,加快前端查询的速度,接口性能提升33%。
另外还有一些针对表和接口的质量监控,通过python脚本自动化调用接口的值写入表中,进行数据的校验,配置DQC增加任务的报警机制,弱规
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











