









文章目录
这里讨论IP分组到它们最终目的端的传递、转发和路由选择,这是相当重要的一章!所谓传递 Delivery 是指「在网络层控制下,用底层的网络对一个分组进行处理的方法」(在链路中),所谓转发 Forwarding 是指「将一个分组传递到下一站点的方法」(在路由器内部),所谓路由选择 Routing 是指「在转发过程中创建路由表的方法」。
路由选择协议 routing protocol 用于不断地更新「在转发和路由选择中要查找的路由表」。这里也讨论常用的单播和多播路由 multicast routing 协议。
RIP的讨论可从下列请求评论中找到:
1131, 1245, 1246, 1247, 1370, 1583, 1584, 1585, 1586, 1587, 1722, 1723, 2082, 2453
OSPF的讨论可从下列请求评论中找到:
1131, 1245, 1246, 1247, 1370, 1583, 1584, 1585, 1586, 1587, 2178, 2328, 2329, 2370
BGP的讨论可从下列请求评论中找到:
1092, 1105, 1163, 1265, 1266, 1267, 1364, 1392, 1403, 1565, 1654, 1655, 1665, 1771,
1772, 1745, 1774, 2283
22.1 传递
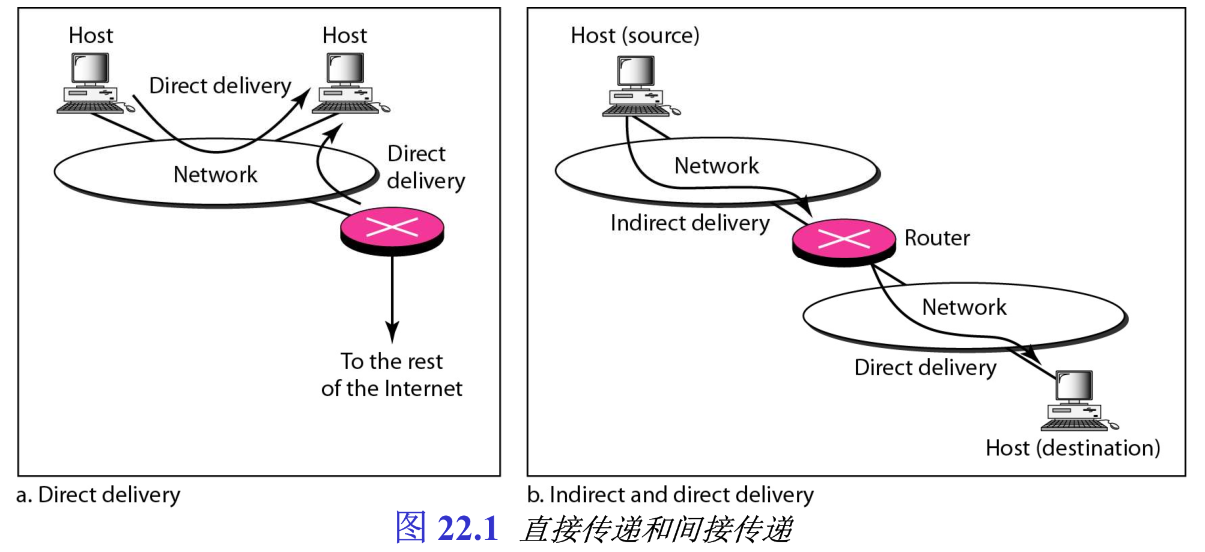
网络层负责用底层物理网络处理分组,我们定义这种处理为分组的传递。分组传递到最终目的端,可使用两种不同的方法:直接传递和间接传递,如图22.1所示。注意,一个传递永远包含一个直接传递和 0 0 0 个或多个间接传递;最后的传递总是直接传递。
- 直接传递
direct delivery就是分组的最终目的端主机与发送方都连接在同一个物理网络上。当分组的源端和目的端都在同一个物理网络上,或者传递是在最后一个路由器与目的主机之间进行时,就出现直接传递。
发送方很容易确定传递是否是直接传递,方法是提取出分组目的端的网络地址和掩码,并与它所连接的网络地址进行比较,如果相同则直接传递。 - 间接传递
indirect delivery是指,目的主机与发送方不在同一个物理网络上,分组就是间接传递。在间接传递中,分组从一个路由器传送到另一个路由器,直到它到达「与最终目的端连接在同一个物理网络上的路由器」为止。
22.2 转发
转发是指将分组路由到它的目的端。转发要求主机或路由器有一个路由表。当主机有分组要发送时,或路由器已收到一个分组要转发时,就要查找路由表,以便求得到达最终目的端的路由。
但是,这种简单方法对于今天的互联网(如因特网)已经是不可能的,因为路由表中的项目数已使得路由表的查询效率很低。
22.2.1 转发技术
有些转发技术可以使路由表的大小成为可管理的,同时也可以处理一些问题(如安全性问题)。此处简要讨论这些方法。
1. 路由方法与下一跳方法
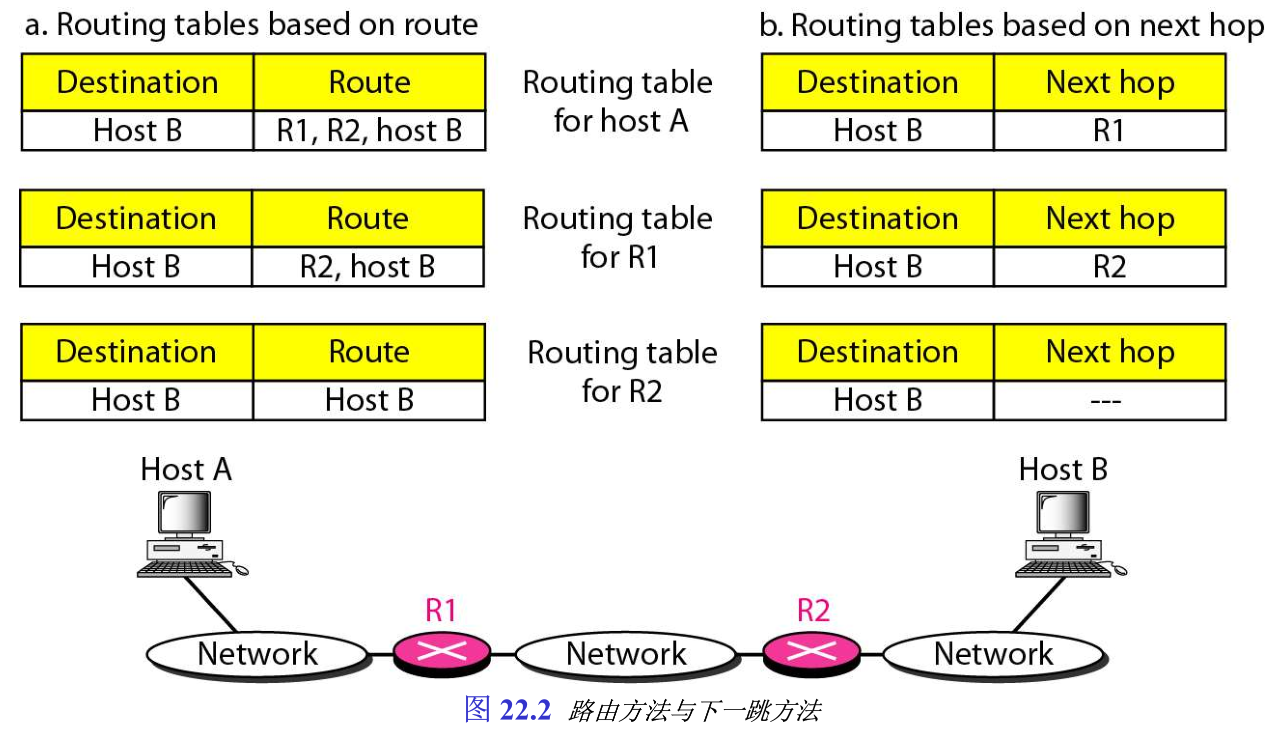
在路由表中保留完整路由信息的技术,称为路由方法 route method 。
第一种减少路由表中内容的技术,称为下一跳方法 next-hop method 。在这种方法中,在路由表中只保留下一跳地址,而不保留完整的路由信息。路由表中各项目必须彼此协调,图22.2表示使用这种技术可以简化路由表:
2. 特定主机方法与特定网络方法
第二种使路由表减少、使查找过程简化的技术,称为特定网络方法 network-specific method ,此处不是对连接在同一个物理网络上的所有主机都有一个项目,这种技术称为特定主机方法 host-specific method ,而是仅用一个项目来定义这个目的网络本身的地址,即将连接在同一网络上的所有主机看作是一个项目。
例如,有1000个主机连接在同一个网络上,则在路由表上仅用一个项目而不是1000个项目,图22.3表示了这个概念。
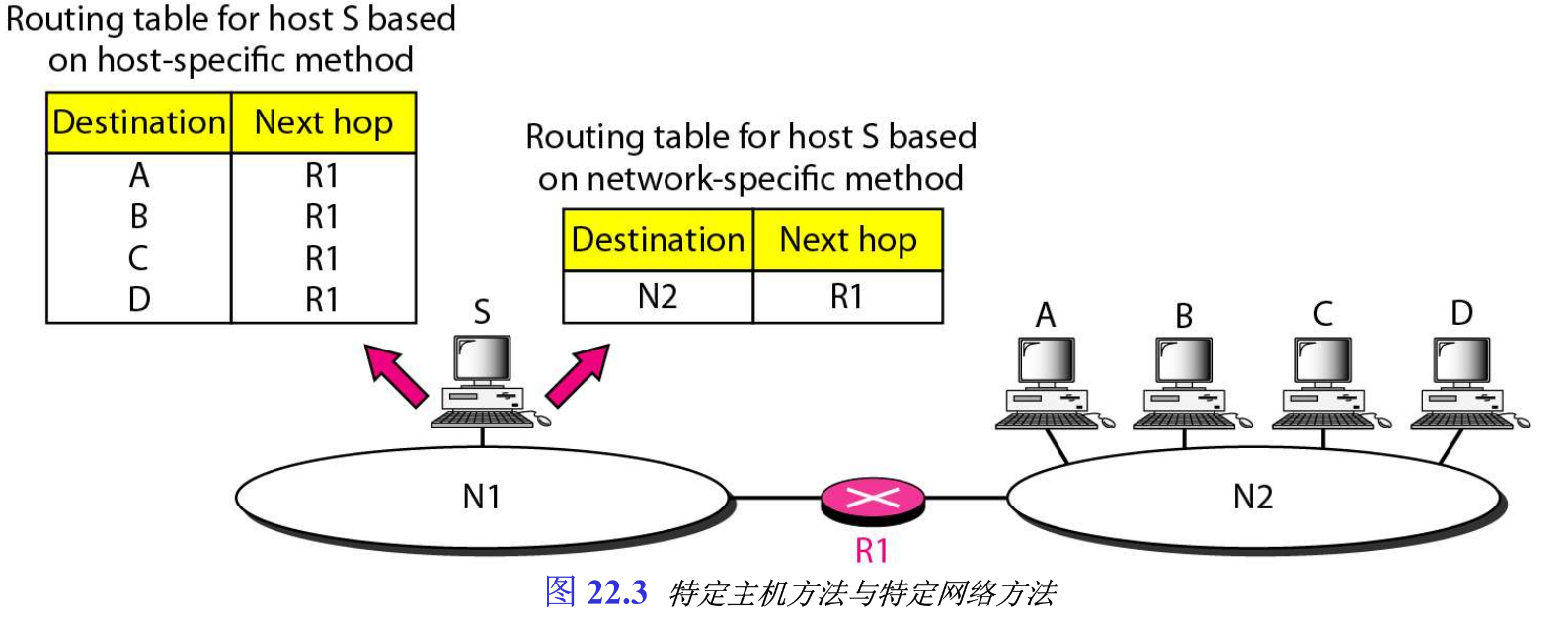
当然,特定主机路由选择可以用于如检查路由或提供安全措施等目的。
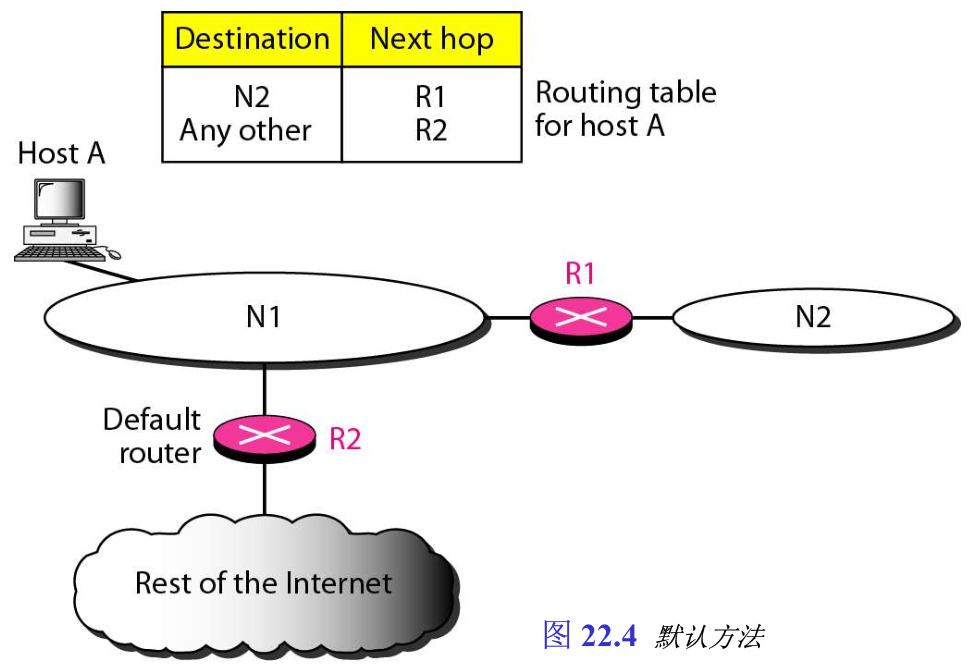
3. 默认方法
另一种简化路由表的技术是默认方法 default method 。在图22.4中,主机A连接到具有两个路由器的网络上,路由器R1用来将分组转发到连接网络N2的主机,但是对因特网的其余部分,则使用路由器R2。因此,可不必将整个因特网中的所有网络都列出,主机A可以仅使用一个称为默认的项目(通常定义网络地址为
0.0.0.0
0.0.0.0
0.0.0.0)。
22.2.2 转发过程
假定主机和路由器使用无类寻址(因为分类寻址可作为无类地址的一种特殊情况处理),在无类寻址中,路由器对涉及到的每一个地址块都需要有一行信息。路由表需要根据网络地址(地址块的第一个地址)进行查询,但很遗憾,在分组中只有目的地址而没有网络地址。为了解决这个问题,在路由表中需要包含掩码
/
n
/n
/n 。因此,对相应的地址块,我们需要有包含该掩码的附加列。图22.5表示了无类寻址的一个简单转发模块。
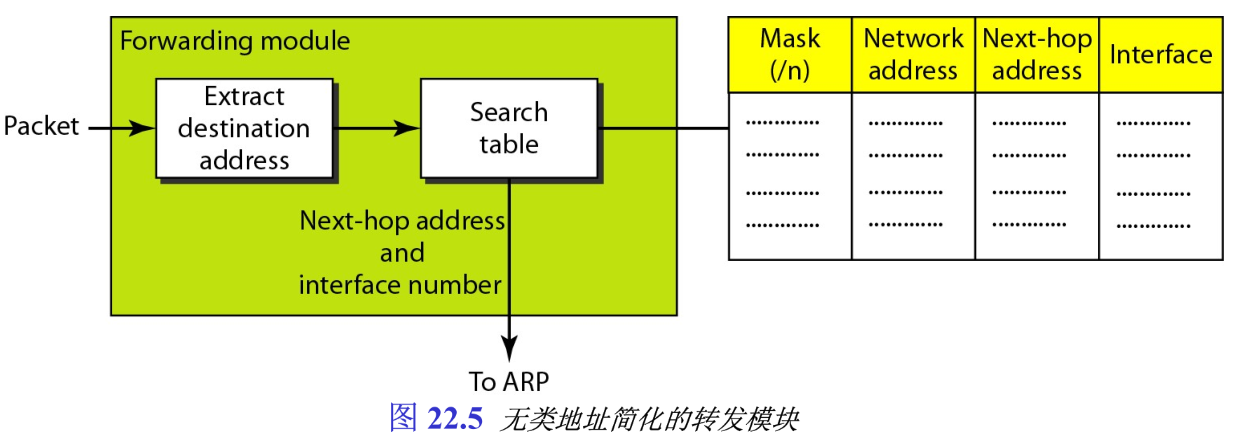
注意,在无类寻址中,一个路由表至少要有4列:掩码、网络地址、下一跳地址、接口,通常有更多的列。
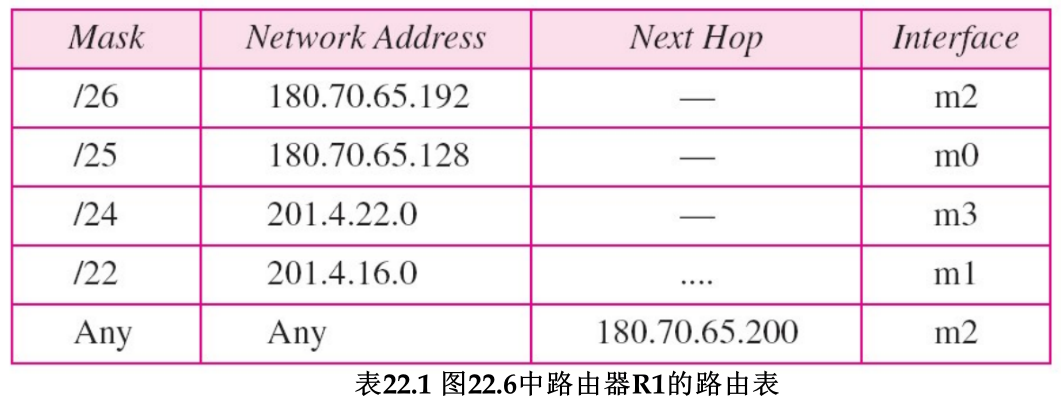
【例22.1】利用图22.6的网络配置,做出R1的路由表。
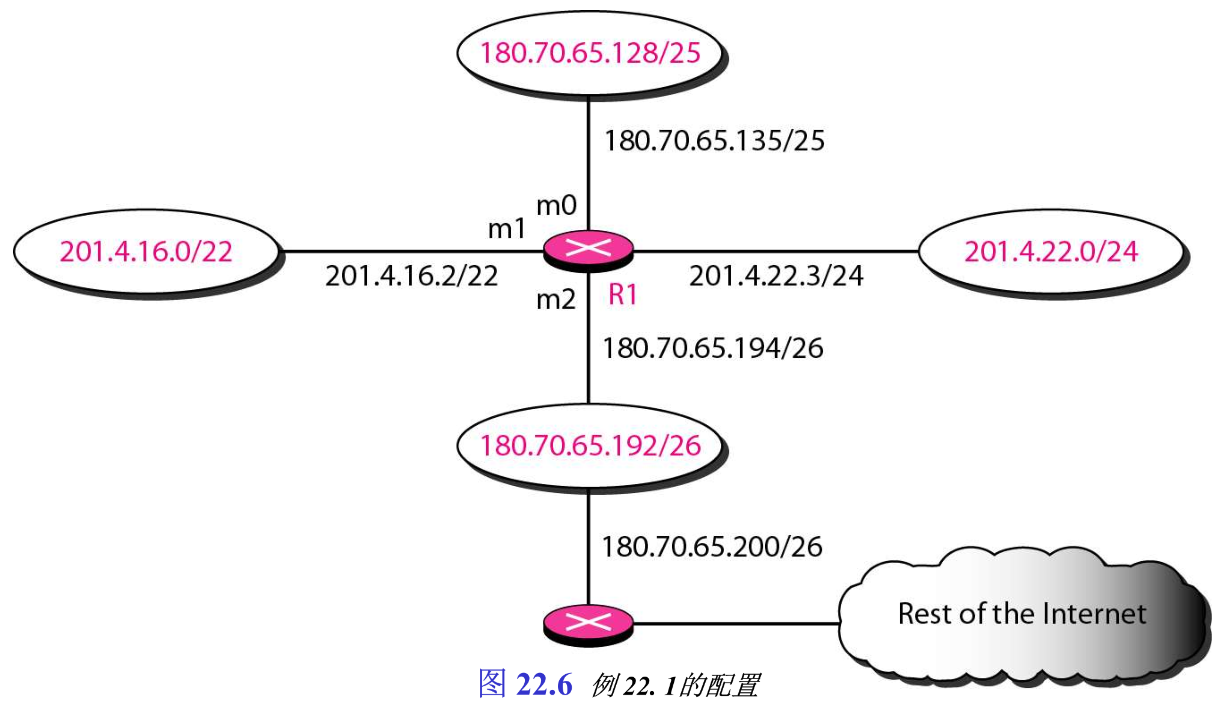 解:表22.1是图22.6中路由器R1的路由表:
解:表22.1是图22.6中路由器R1的路由表:
【例22.2】如果图22.6中的一个目的地址为
180.70.65.140
180.70.65.140
180.70.65.140 的分组到达路由器R1,说明其转发过程。
解:路由器执行下列步骤:
(1)第一个掩码 (
/
26
/26
/26) 作用于这个目的地址,其结果是
180.70.65.128
180.70.65.128
180.70.65.128 ,它与对应的网络地址不匹配;
(2)第二个掩码(
/
25
/25
/25)作用于这个目的地址,其结果是
180.70.65.128
180.70.65.128
180.70.65.128 ,它与对应的网络地址匹配。将下一跳地址 next-hop address 和接口号
m
0
m_0
m0 传送到ARP,做进一步处理。
【例22.3】如果图22.6中的一个目的地址为
201.4.22.35
201.4.22.35
201.4.22.35 的分组到达路由器R1,说明其转发过程。
解:路由器执行下列步骤:
(1)第一个掩码 (
/
26
/26
/26) 作用于这个目的地址,其结果是
201.4.22.0
201.4.22.0
201.4.22.0 ,它与对应的网络地址不匹配;
(2)第二个掩码(
/
25
/25
/25)作用于这个目的地址,其结果是
201.4.22.0
201.4.22.0
201.4.22.0 ,它与对应的网络地址不匹配;
(3)第三个掩码(
/
24
/24
/24)作用于这个目的地址,其结果是
201.4.22.0
201.4.22.0
201.4.22.0 ,它与对应的网络地址匹配。分组的目的地址和接口号
m
3
m_3
m3 传送到ARP。
【例22.4】如果图22.6中的一个目的地址为
18.24.32.78
18.24.32.78
18.24.32.78 的分组到达路由器R1,说明其转发过程。
解:这时所有掩码作用于这个目的地址,都与网络地址不匹配。当它到达表的尾部时,模块将下一跳地址
180.70.65.200
180.70.65.200
180.70.65.200 和接口号
m
2
m_2
m2 传送到ARP。这就是需要通过路由器,转发到因特网某处的输出包。
关于转发过程,需要说明的还有以下几点。
1. 地址聚合
我们使用无类寻址时,路由表的项目数量很可能增多,因为无类寻址的意图是将整个地址空间划分成可管理的地址块。而路由表增大,将进一步增加查找时间。为了缓解这个问题,我们设计了地址聚合 address aggregation 思想。
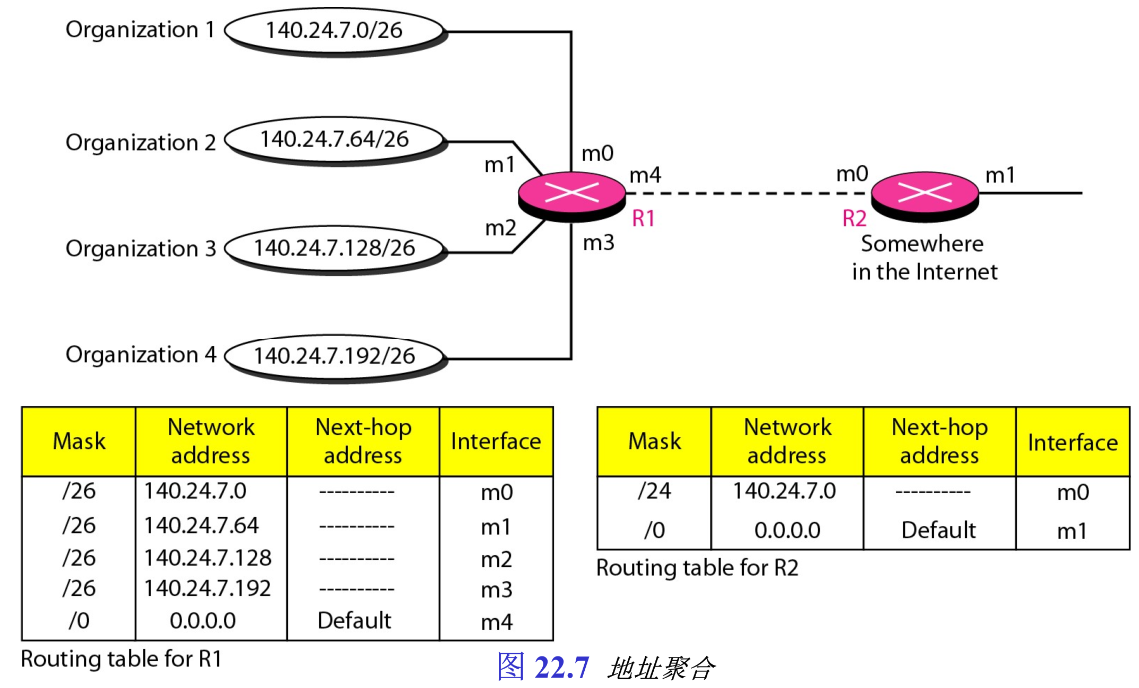
在图22.7中有两个路由器,路由器R1连接到四个组织机构的网络,每个组织机构的网络都使用
64
64
64 个地址;路由器R2在远离R1的某个地方。路由器R1的路由表较长,因为分组必须要正确地路由到适当的组织机构网络。而路由器R2的路由表很短,对于路由器R2来说,不管到哪个组织机构,任一目的地址为
140.24.7.0
140.24.7.0
140.24.7.0 到
140.24.7.255
140.24.7.255
140.24.7.255 的分组,都是从接口
m
0
m_0
m0 发送,因为四个组织机构的地址块被聚合为一个较大的地址块,所以这个称为地址聚合。如果每个组织机构的地址没有聚合成一块地址,那么路由表R2将有较长的路由表。
注意,尽管地址聚合的思想与子网化的思想类似,但这里没有一个共同的站点。地址聚合和特定网络方法也很像,但是后者是将连接在同一网络上的所有主机看作是一个项目,不能跨越网络;而地址聚合中每个组织机构的网络都是独立的,此外我们还可有若干级的聚合。
2. 最长掩码匹配
如果在图22.7中,其中一个组织机构在地理位置上与其他三个不相邻,将会发生什么?例如,组织机构4由于某种原因,没有连接到路由器R1,我们能否还用地址聚合的思想,以及还能对组织机构4指派地址块 140.24.7.192 / 26 140.24.7.192/26 140.24.7.192/26 吗?
由于无类寻址的路由选择中,使用另一个最长掩码匹配 longest mask matching 原则,回答是“可行”。这一原则指明在路由表中掩码存放是按最长的到最短的次序。即如果有三个掩码
/
27
,
/
26
,
/
24
/27, /26, /24
/27,/26,/24 ,则
/
27
/27
/27 必定是第一个项目,而
/
24
/24
/24 必定是最后一个项目。如果用这一原则,看看组织机构4如果与另外三个组织机构分离,情形会怎样,如图22.8所示。
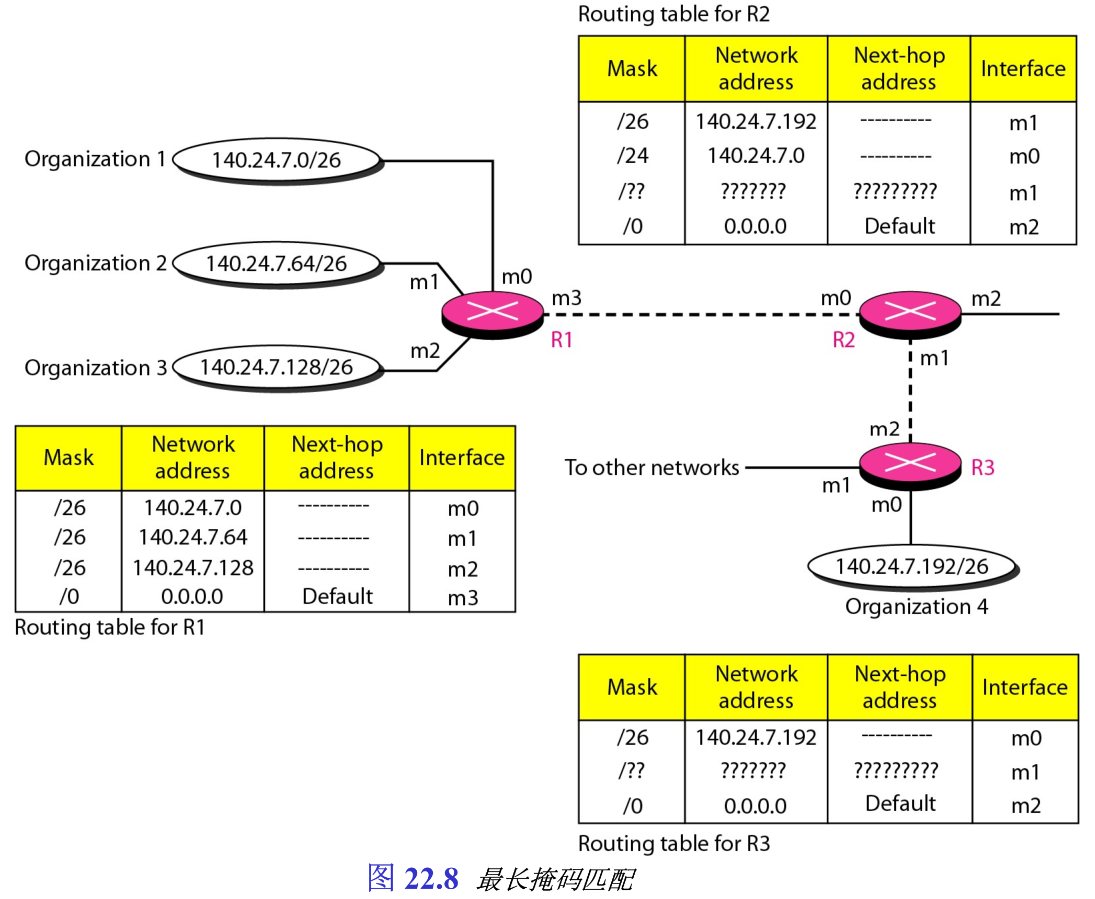
假定一个分组到达目的地址是
140.24.7.200
140.24.7.200
140.24.7.200 的组织机构4,将路由表R2中第一个掩码作用于它,得到网络地址
140.24.7.192
140.24.7.192
140.24.7.192 。该分组正确通过接口
m
1
m_1
m1 而到达组织机构4,但是,如果路由表不按最长的前缀存储,作用于掩码
/
24
/24
/24 将给出分组到路由器R1的、不正确的路由选择。
3. 分层路由选择
为了解决巨大的路由表问题,我们可在路由表中建立层次结构。第1章中已经提过,今天的因特网具有层次结构,即因特网被划分为国际的和国内的ISP,国内的ISP又被划分为地区ISP,地区ISP再进一步划分为本地ISP。如果路由表也像因特网一样具有层次结构,那么可降低路由表的长度。
让我们考虑本地ISP情况。本地ISP可被分配一个单地址块,该块是具有某一前缀长度的大块。本地ISP将这个块划分为不同大小的一些小块。如果分配给本地ISP的地址块以 a . b . c . d / n a.b.c.d /n a.b.c.d/n 开始,那么这个ISP可建立以 e . f . g . n / m e.f.g.n/m e.f.g.n/m 开始的一些块,其中 m > n m > n m>n ,而对于每个客户, m m m 是可变的。
这如何降低路由表的长度呢?因特网的其余部分不必知道这样的划分。对因特网的其余部分来说,本地ISP的所有客户都被定义为 a . b . c . d / n a.b.c.d/n a.b.c.d/n ;在「这个大块中的每个分组」的目的地址都路由到本地ISP。对于所有这些客户来说,它们在世界上的每个路由器中都只有一项,且都属于同一组。
当然,在本地ISP内部,路由器必须识别出子块并路由到目的客户。如果某一客户是一个较大的组织机构,那么它也可以通过子网化和划分它的子块为更小的子块(子块的子块),建立另一个层次。这就是分层路由选择 hierarchical routing !注意,在无类路由选择中,只要我们遵循无类寻址规则,层次的级是没有限制的。
【例22.5】考虑图22.9。区域ISP被授予以地址 120.14.64.0 120.14.64.0 120.14.64.0 开始的 16384 16384 16384 个地址。区域ISP决定将这个块划分为 4 4 4 个子块,每块 4096 = 2 12 4096 = 2^{12} 4096=212 个地址。其中的 3 3 3 个子块分别指派给 3 3 3 个本地 ISP,而第 2 2 2 子块保留作将来使用。注意:由于原始块的掩码是 / 18 /18 /18 ,因此每块的掩码是 / 20 /20 /20 。
- 第一个本地ISP将它的块划分成
8
=
2
3
8 = 2^3
8=23 个较小的子块,每一个指派给一个小的ISP。每个小的ISP对
128
=
2
7
128 = 2^7
128=27 个家庭(
H001到H128)提供服务,每个家庭使用 4 = 2 2 4 = 2^2 4=22 个地址。例如,小的ISP会向H001发送目的地址为 [ 120.14.64.0 , 120.14.64.3 ] [120.14.64.0,\ 120.14.64.3] [120.14.64.0, 120.14.64.3] 的分组。 - 第二个本地ISP将它的块划分成
4
=
2
2
4 =2^2
4=22 个子块,并将地址指派给
4
4
4 个大型的组织机构(
LOrg01到LOrg04)。 - 第三个本地ISP将它的块划分成
16
=
2
4
16 = 2^4
16=24 个子块,并将每个子块指派给一个小型的组织机构(
SOrg01到SOrg16),每一个小型的组织机构有 256 256 256 个地址,掩码是 / 24 /24 /24 。
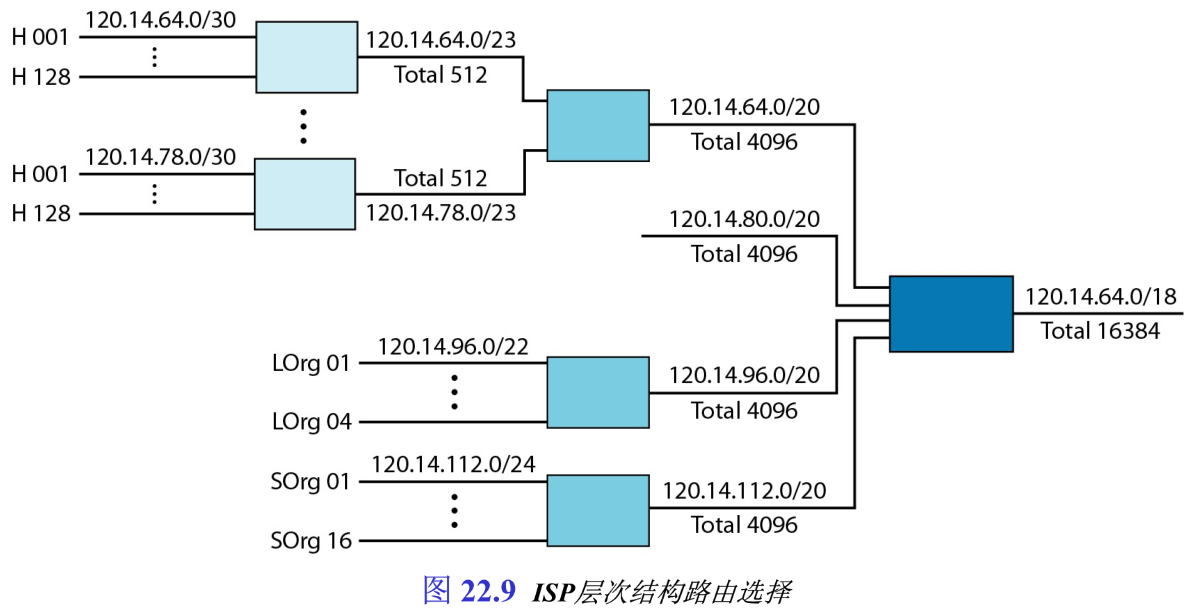
在这种配置中,存在层次结构。在因特网上的所有路由器,都会将带有「从 120.13.64.0 120.13.64.0 120.13.64.0 到 120.14.127.255 120.14.127.255 120.14.127.255 的目的地址」的分组发送到ISP。
4. 地理路由选择
为了更进一步地缩小路由表的大小,我们需要将分层路由选择扩充为包含地理的路由——必须将整个地址空间划分为数量不多的几个大块,指派一个大块给北美、一个大块给欧洲、一个给亚洲、一个给非洲等。欧洲以外ISP的路由器,在它们的路由表中将只有到欧洲的一个项目;北美以外ISP的路由器,也只有到北美的一个项目。
22.2.3 路由表
现在讨论路由表,主机或路由器要转发IP分组,就要有一个路由表,并给每个目的端设置一个项目。路由表可以是静态的,也可以是动态的。
1. 静态路由表
静态路由表 static routing table 包含有人工输入的信息。网络管理人员将每一个目的地址的路由输入到路由表中。当路由表生成后,因特网中的变化无法自动在路由表中更新。路由表必须由网络管理员手动改变。
静态路由表用在不会经常改动的小型互联网中,或用于故障查找的试验互联网中。对于像因特网这样的大型互联网,静态路由表是极差的方法。
2. 动态路由表
动态路由表 dynamic routing table 使用一个动态路由选择协议,如RIP、OSPF、BGP,因而可以周期性地进行更新。当因特网发生变化时,例如当某个路由器关闭或某条链路中断,动态路由选择协议就自动更新所有路由器(最后也将在所有主机中)的路由表。
为了有效地传递IP分组,一个大的互联网如因特网需要动态地更新路由表。本文后面将详细讨论三种动态路由选择协议。
3. 路由表格式
如前所述,对于无类寻址的路由表,最小列数是
4
4
4 ,但是今天的路由表甚至有更多的列数。应当明白,列数与厂商有关,并不是所有列在不同的路由器中都有。目前路由器的路由表中,一些常有字段如图22.10所示:

- 掩码。这个字段定义应用于该表项的掩码。
- 网络地址。这个字段定义分组必须传递到的最终的网络地址。在特定主机路由选择的情况下,该字段定义目的主机的地址。
- 下一跳地址。这个字段定义分组必须传递到的下一跳路由器的地址。在路由方法中,该字段保留完整的路由信息。
- 接口。这个字段显示接口的名称。
- 标记。这个字段定义多达
5
5
5 个标记。所谓标记就是一个通/断开关,它表示或者存在或者不存在。这五个标记是:
U
U
U(工作)、
G
G
G(网关)、
H
H
H(特定主机)、
D
D
D(由于重定向而增加的)、
M
M
M(由于重定向而修改的)。
- U U U(工作)标记指出路由器正在工作。如果没有这个标记,就表示路由器已不工作,这时分组无法转发,因而将被丢弃。
- G G G(网关)标记指出目的端是另一个网络。分组必须传递到下一跳路由器以便传递(间接传递)。如果没有这个标记,就表示目的端在这个网络中(直接传递)。
- H H H(特定主机)标记指出在地址字段的项目是一个特定主机地址。如果没有这个标记,就表示这个地址只是目的端的网络地址。
- D D D(由于重定向而增加的)标记指出由于ICMP报文中的重定向报文,而在主机路由表中增加了「到这个目的端的路由选择信息」。
- M M M(由于重定向而增加的)标记指出由于ICMP报文中的重定向报文,而修改了「到这个目的端的路由选择信息」。我们已在第21章中讨论了重定向与ICMP协议。
- 引用计数。这个字段给出在任何时候使用本路由的用户个数。例如,如果有 5 5 5 个人在同样的时间,从本路由器连接到这个相同的(目的)主机,则这一列的值是 5 5 5 。
- 使用。这个字段指出经过本路由器发送到相应的目的端的分组数。
有几个用于查找路由信息和路由表内容的实用程序,这里讨论两个:netstat和ifconfig。
4. 实用程序 netstat, ifconfig
【例22.6】在UNIX或者Linux操作系统下,可用于查找路由信息和路由表内容的一个命令是 netstat 。
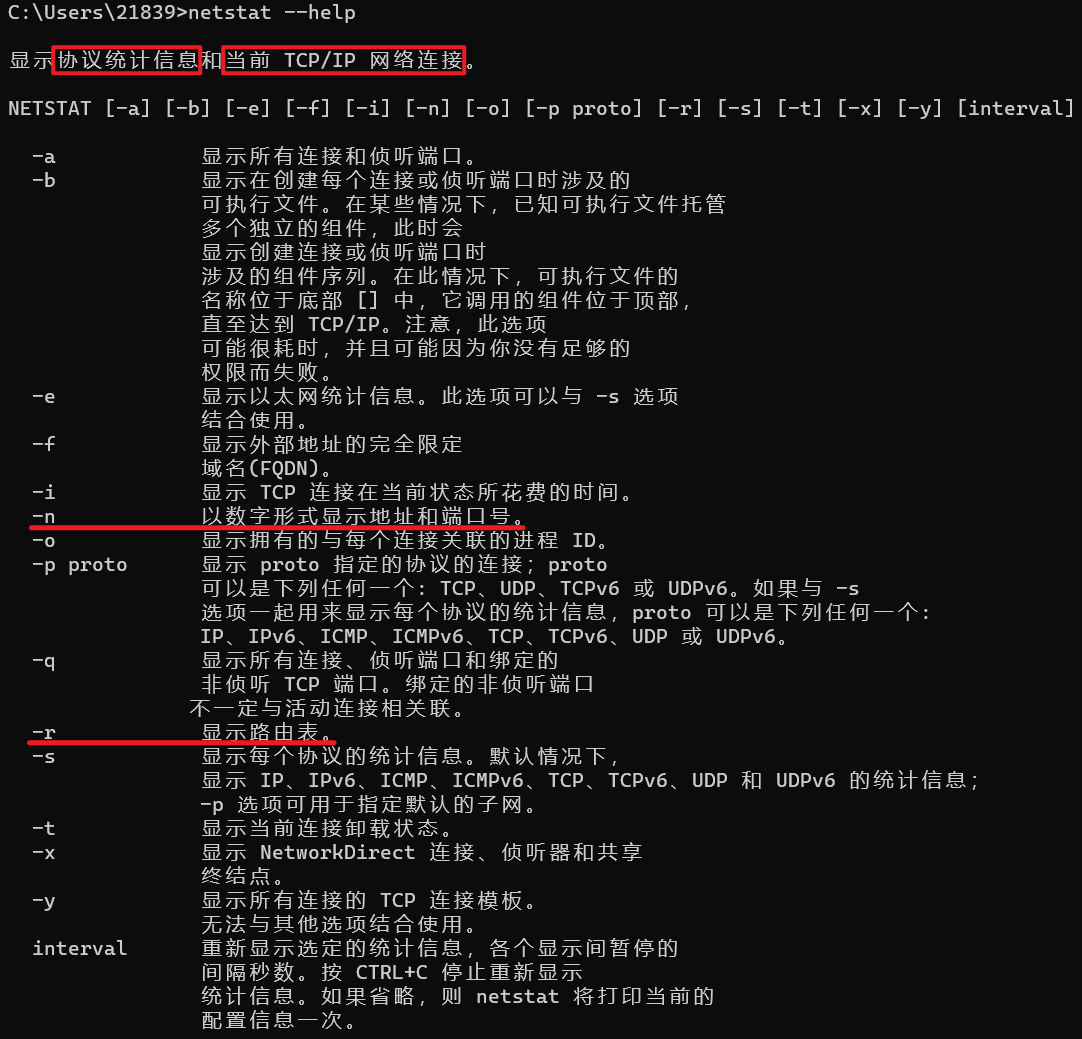
下面显示了一个默认服务器的内容列表。在命令中使用了两个选项 r 和 n ,其中选项 r 表示我们对路由表感兴趣,而选项 n 是查找地址的数字形式。注意:这是一个主机的路由表,而不是路由器的,主机也需要路由表。

注意,上表中列的次序与我们表示的是不同的。此处目的端列定义网络地址;UNIX中的网关 gateway 与路由器同义,该列定义下一跳地址;值
0.0.0.0
0.0.0.0
0.0.0.0 表示传递是直接的;最后一行中的
G
G
G 表示通过了一个路由器(默认路由器)到达目的端,没有
G
G
G 标记就表示传递是直接的。Iface列定义接口,主机只有一个实际的端口 eth0 ,它是指连接到以太网的接口
0
0
0 。第二个接口
l
0
l_0
l0 ,实际上是虚拟回送接口,它包含主机用回送地址
127.0.0.0
127.0.0.0
127.0.0.0 接收的分组。
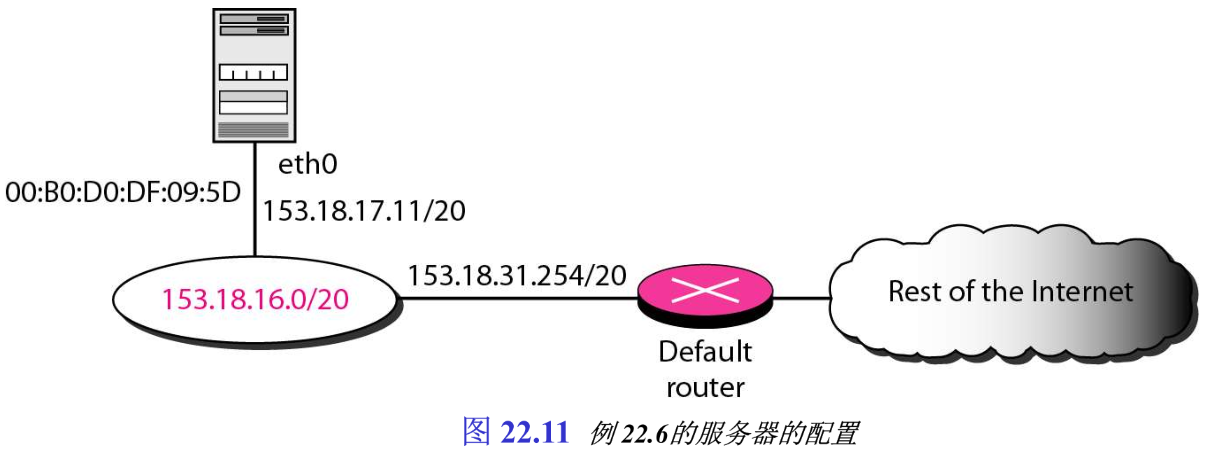
通过在给定接口(etho0)上使用 ifconfig 命令(即 interfaces config),可以查找到有关服务器IP地址和接口物理地址更多的信息。

从上述信息中,我们可推断出服务器的配置,如图22.11所示:
22.3 单播路由选择协议
路由表可以是静态的,也可以是动态的。静态路由表是由人工输入项目,而动态路由表在互联网中某处有变化时,就自动地更新。当前,互联网需要动态路由表。只要在互联网中有些变化,路由表就应当尽快地更新。例如,当一个路由器不通了,路由表就必须更新;而当发现有一条较好的路由时,路由表也需要更新。
由于需要有动态路由表,因而产生了多种路由选择协议。路由选择协议是一些规则和过程的组合,使得在互联网中的各路由器、能够彼此互相通知这些变化——路由选择协议使得旧金山的路由器能够知道得克萨斯的网络故障。路由选择协议还包括一些过程,用来合并从其他路由器接收到的信息。
22.3.1 优化原则
路由器从网络接收到分组,并将其转发到另一个网络。一个路由器通常连接到多个网络,当它接收到分组时,它应该将分组转发到哪个网络呢?这个决定是基于最优化原则而做出的,哪一个可用路径是最佳路径?优化这一名词的定义是什么?
一种方法是给网络指定一个通过代价 One approach is to assign a cost for passing through a network ,称这个代价为度量 metric 。然而,给每个网络指定的度量取决于协议的类型。
- 有些简单协议,如路由信息选择协议
RIP,同等对待每个网络,即通过每个网络的代价都是一样treat all networks as equals,其跳数为 1 1 1 。因此,如果分组经过 10 10 10 个网络,才到达目的端,则总的代价是 10 10 10 跳。 - 其他协议,如开放最短路径优先
OSPF,允许网络管理员基于所需服务类型,指定通过网络的代价,即通过一个网络的路由可以有不同的代价。例如,如果最大吞吐量是所期望的服务类型,则一条卫星链路要比一条光纤线路具有更小的度量;另一方面,如果最小延迟是所期望的服务类型,则光纤线路比卫星链路具有更小的度量。OSPF允许每个路由器有几个基于(不同)服务类型的路由表。 - 还有一些协议以完全不同的方式定义度量。在边界网关协议
BGP中,准则就是「可由网络管理员设置的策略」the criterion is the policy, which can be set by the administrator,该策略定义应当选择什么路径。
22.3.2 域内部和域间路由选择协议
今天的互联网是非常大的,以致于仅使用一个路由选择协议,就无法处理更新所有路由器中路由表的任务。为此,需要将互联网划分为多个自治系统 autonomous system ,即一个单一的管理机构管辖下的一组网络和路由器。
在自治系统内部的路由选择称为域内路由选择 intradomain routing ,在自治系统之间的路由选择称为域间路由选择 interdomain routing 。每一个自治系统可以选择一种或多种域内路由选择协议,处理自治系统内部的路由选择。但是,处理自治系统之间的路由选择,通常只能使用一种域间路由选择协议(见图22.12):
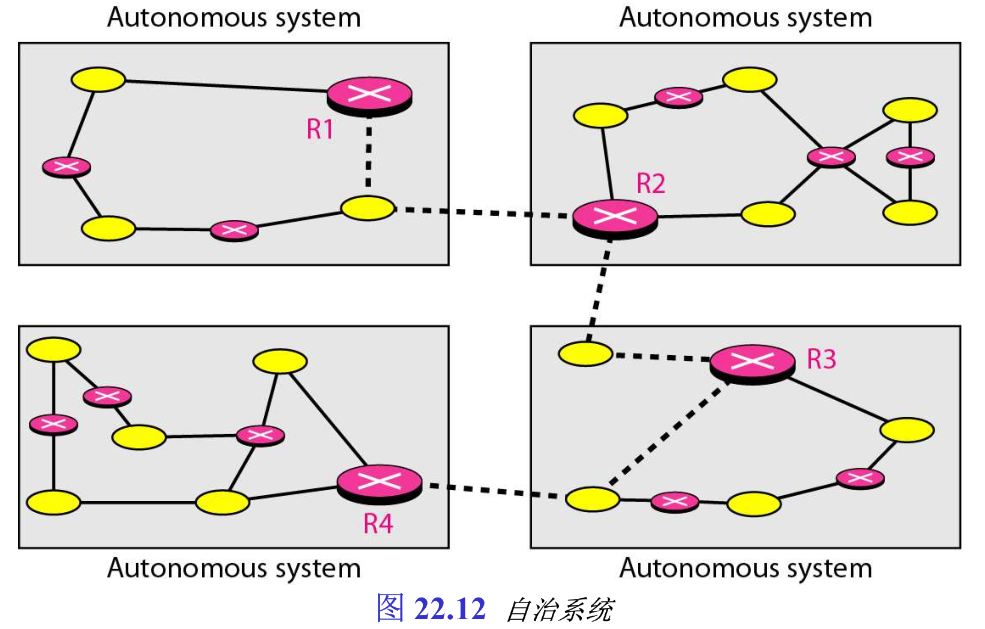
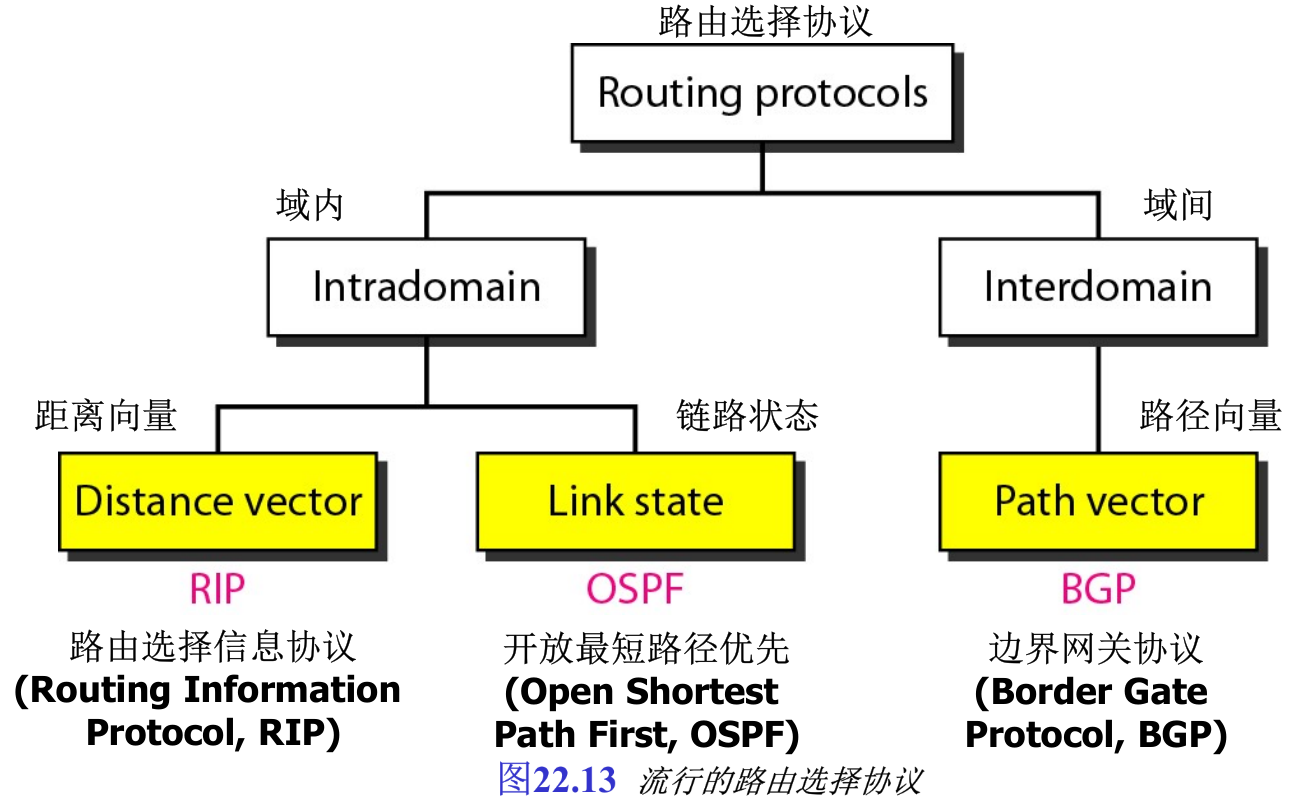
现在有几种域内和域间路由选择协议在使用。这里只讨论几个最流行的协议,两个域内路由选择协议:RIP和OSPF,以及一个域间路由选择协议BGP(见图22.13)——路由选择信息协议 Routing Information Protocol, RIP 是一种距离向量协议,开放最短路径优先 Open Shortest Path First, OSPF 是一种链路状态协议,边界网关协议 Border Gate Protocol, BGP 是一种路径向量协议。
22.3.3 距离向量路由选择
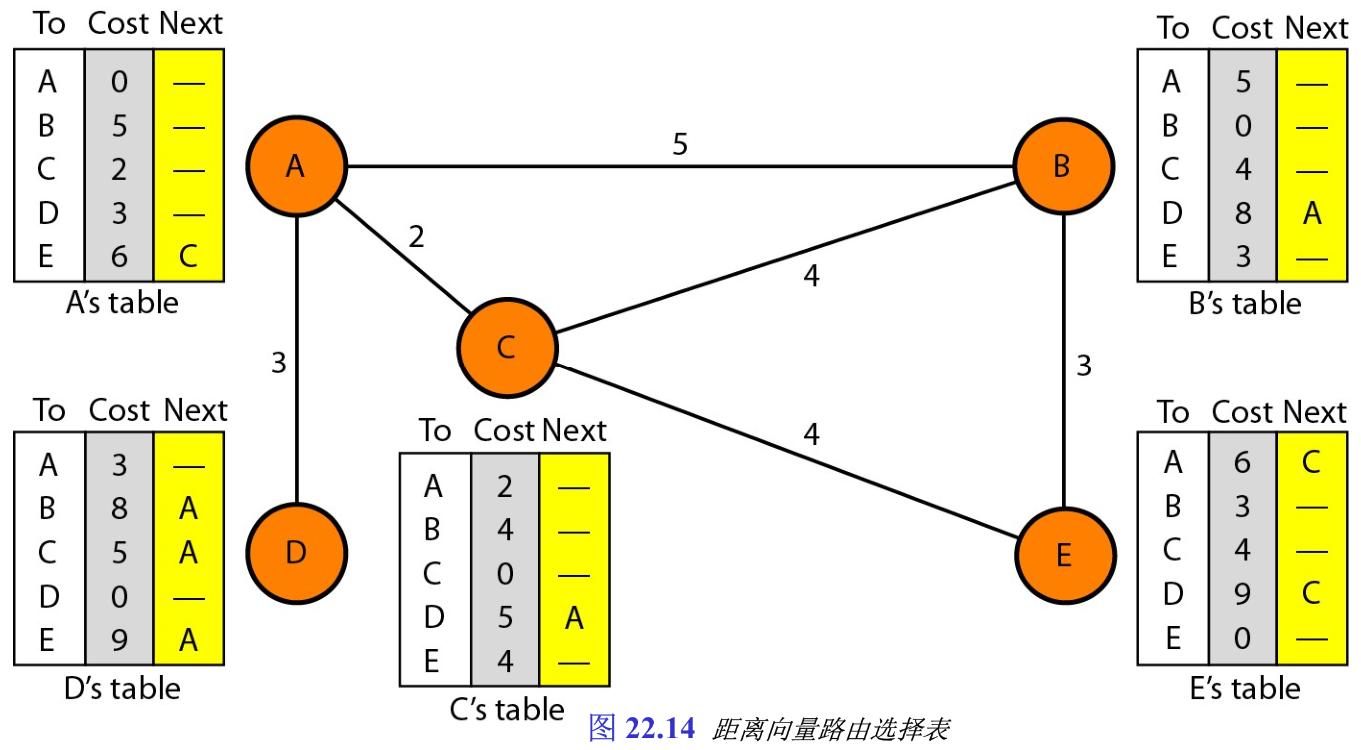
在距离向量路由选择中,任何两个节点之间的代价最低的路由是距离最小的路径 In distance vector routing, the least-cost route between any two nodes is the route with minimum distance 。正如其名,每个节点都保留一张到其他每个节点的最小向量距离(表)a vector (table) of minimum distances to every node ,每个节点也用这张表中所表示的路由中的下一个节点(下一跳路由选择),指导分组流向目的节点。
我们可将节点看做区域中的城市,而将线看做连接城市的道路。一张表就是「可表示城市之间路程最小距离的图」。图22.14表示具有相应表的
5
5
5 个节点的系统,其中节点A的表说明「从该节点如何到达其他节点」,例如到达节点
E
E
E 的代价是
6
6
6 ,其路由是经过
C
C
C 。
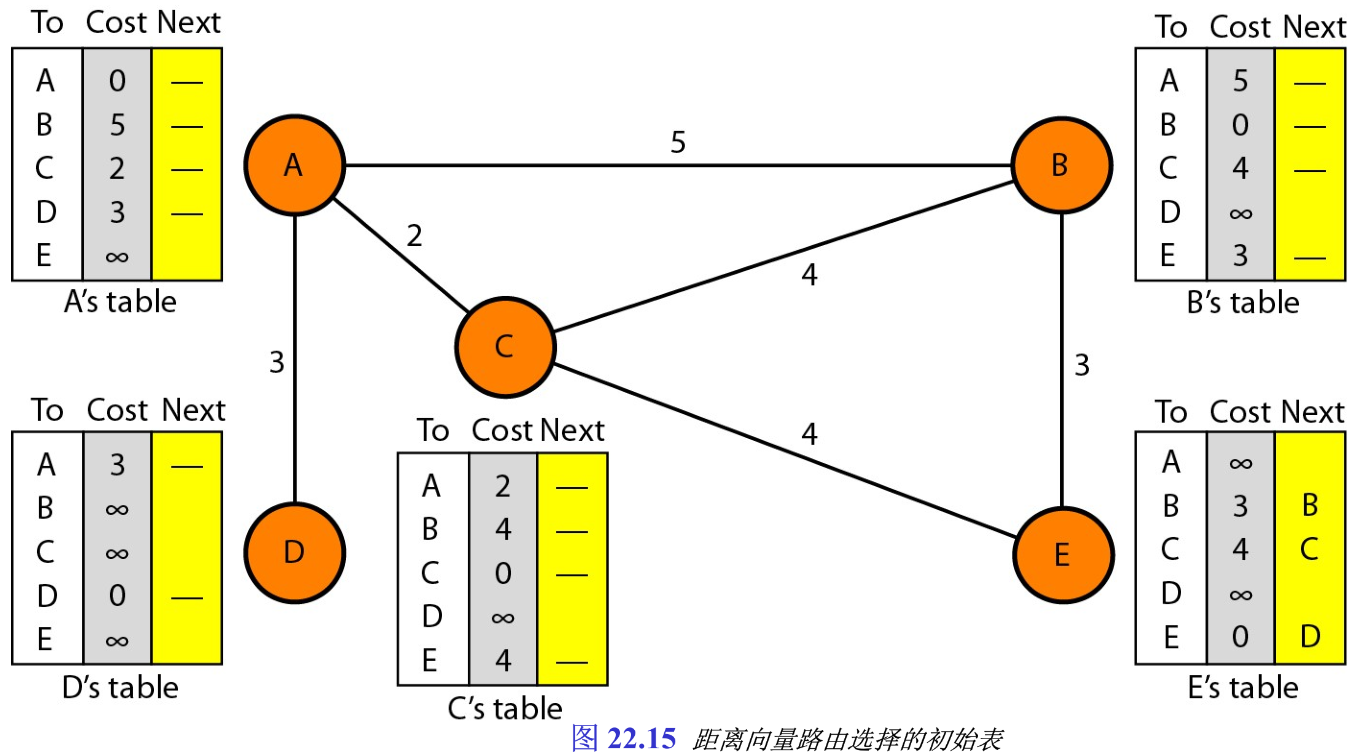
1. 初始化
图22.14中的表都是稳定的,每个节点都知道如何到达其余任一节点及其代价。但是在开始时,并不是这样的。每个节点只知道自身与其直接相连的邻站 immediate neighbor 的距离。所以目前,我们假定每个节点能向邻站发送报文,并得到自己与这些邻站之间的距离。图22.15表示了每个节点的初始表,其中不是邻站的距离标为无穷大(不可达)。
2. 共享
距离向量路由选择的总的思想是「与邻站共享路由信息」,在距离向量路由选择中,每个节点与它的邻站周期性地或有变化时共享它的路由表。尽管节点 A A A 不知道节点 E E E ,但节点 C C C 知道节点 E E E ,如果节点 A A A 共享节点 C C C 的路由表,那么节点 A A A 也知道如何到达节点 E E E 。另外,节点 C C C 不知道如何到达节点 D D D ,但节点 A A A 知道,如果节点 C C C 共享节点 A A A 的路由表,那么节点 C C C 也知道如何到达节点 D D D 。换言之,相邻站的两个节点 A A A 和 C C C 如果彼此帮助,那么就可以改进它们的路由表。
只是还有一个问题,与每个邻站需共享表中多少项?一个节点并不知道邻站的表,解决的最好方法是每个节点向邻站发送它的完整表,让邻站决定哪些项目是有用的、哪些项目应丢弃。当然,表中第三列(下一个节点 next stop )对邻站是没有用处的,因此当邻站接收到一个表时,第三列用发送方的节点名替代。如果有一行可以用,则下一个节点就是表的发送节点 If any of the rows can be used, the next node is the sender of the table 。所以一个节点仅向任一邻站发送它的表中前两列,即这里的共享仅指共享前二列。
3. 更新算法
当一个节点从它的邻站接收到二列的表时,它需要更新它的路由表。更新用三个步骤:
- 接收节点将在表的第二列中的每一个值之上,加上它与发送节点之间代价的值。这是显然的,因为节点 C C C 说它到目的距离是 x x x 米,而节点 A A A 与 C C C 的距离是 y y y 米,则 A A A 与目的地的距离是 x + y x + y x+y 米。
- 如果接收节点使用来自任一行的信息,接收节点需要把发送节点名加入作为第三列(下一个节点)。
- 接收节点将修改过的、接收到的表,与它的旧表的相应行进行逐行比较。在到达的目的节点项目相同的前提下:
- 如果下一个节点项目不同,则接收节点选取具有最小代价的行;如果最小代价相同,则保持旧的。
- 如果下一个节点项目相同,则接收节点选取新行。例如假定节点 C C C 在前面已经宣布,到节点 X X X 的距离是 3 3 3 ;现在假设节点 C C C 到节点 X X X 没有路径,即节点 C C C 现在宣布,这条路径距离为无穷大;节点 A A A 不能不理睬这个值,即使它的旧项目较小;此后旧的路径不再存在,新的路径距离为无穷大。
图22.16表示了节点
A
A
A 在接收到来自节点
C
C
C 的部分表后,如何更新它的路由表。需要强调的是,一,任何数加无穷大仍为无穷大;二,修改过的表中第一项说明了如何从节点
A
A
A 经过节点
C
C
C 到达节点
A
A
A ,如果节点
A
A
A 需要通过节点
C
C
C 到达它自己,则必须去往节点
C
C
C 然后返回,其距离为
4
4
4 ;三,更新节点
A
A
A(路由表)的唯一好处是最后的项目,原先节点
A
A
A 不知道如何到达节点
E
E
E(距离是无穷大),而现在知道通过节点
C
C
C 、代价是
6
6
6 。
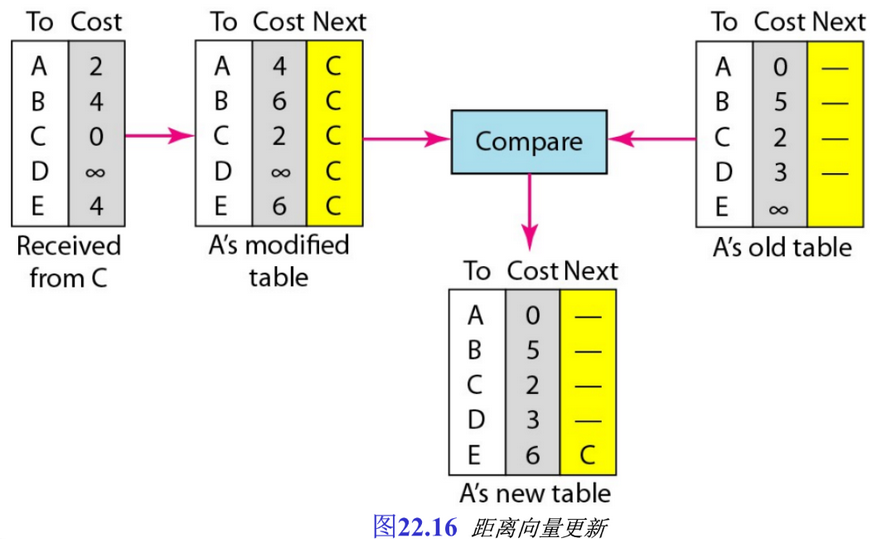
每一节点可用来自其他节点的表更新它的表。在短时间内,如果网络本身没有变化,如链路故障等,那么每一个节点达到一个稳定状态后,它的表的内容保持不变。
4. 何时共享
现在的问题是,一个节点何时向所有相邻节点发送部分的路由表 partial routing table(仅二列,最小距离向量)?周期性地和当表有改变时,就发送该表中的两列。
- 周期更新,其更新时间依赖于所用的距离向量路由选择的协议。通常,每隔 30 30 30 秒,节点发送它的路由表一次,定期更新。
- 触发更新。节点在它的路由表有变化时,向它的邻站节点发送它的二列路由表,这称为触发更新
triggered update。变化是由这些原因引起的:节点接收到邻站的表,引起它自己表的更新;节点检测到邻站链路有故障。
5. 两个节点循环不稳定性 Two-Node Loop Instability
距离向量路由选择的一个问题就是不稳定性,即使用这种协议的网络可能成为不稳定的。要理解这个问题,考察图22.17的情况。
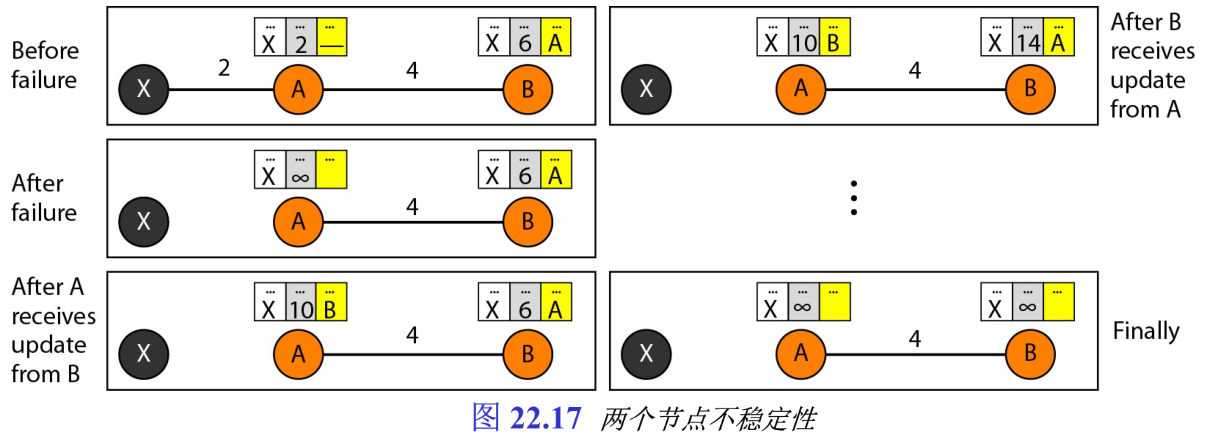
图22.17表示一个有三个节点的系统,仅表示了与讨论有关的路由表部分。开始时,两个节点
A
A
A 与
B
B
B 都知道如何到达节点
X
X
X 。但突然
A
A
A 与
X
X
X 断开,节点
A
A
A 改变它的路由表。如果
A
A
A 立即发送它的表给
B
B
B ,一切都正常。但是,在
B
B
B 接收
A
A
A 的路由表之前,
B
B
B 已发送了它的路由表,该系统变成不稳定。
节点
A
A
A 接收
B
B
B 发来的路由表,它假定
B
B
B 已找到了到达
X
X
X 的路径,于是立即更新它的路由表。基于触发更新策略 triggered update strategy ,
A
A
A 向
B
B
B 发送它的新更新的路由表,现在
B
B
B 认为
A
A
A 的周围环境已改变并更新它的路由表,于是到达
X
X
X 的代价逐渐地增加直到无穷大。这时,
A
A
A 与
B
B
B 两者都知道
X
X
X 不可达 At this moment, both A and B know that X cannot be reached 。
但是在这个过程中,系统是不稳定的 However, during this time the system is not stable ,节点
A
A
A 认为通过
B
B
B 有路径到达
X
X
X ,而节点
B
B
B 认为通过
A
A
A 有路径到达
X
X
X 。如果
A
A
A 接收到目的地为
X
X
X 的一个分组,它向
B
B
B 发送,然后返回到
A
A
A 。同样的,如果
B
B
B 接收到目的地为
X
X
X 的一个分组,它向
A
A
A 发送,然后返回到
B
B
B 。这样分组就在
A
A
A 与
B
B
B 之间来回往返循环。
对于这类不稳定性,已经提出了几个解决办法。
- 定义无穷大
Defining Infinity。第一个明显的解决方法是将一个较小的数值定义为无穷大,例如 100 100 100 。对于前述的情况,系统将在小于 20 20 20 次更新下是不稳定的。事实上,大多数距离向量路由选择协议的实现,都定义两个相邻的节点距离为 1 1 1 ,并认为 16 16 16 为无穷大。这就是说,距离向量路由协议不能用于大的系统the distance vector routing cannot be used in large systems,网络的规模在每个方向不能超过 15 15 15 次跳。 - 分割范围
Split Horizon。另一个解决方法是分割范围。在这种策略中,不是通过每一个接口发送整个表,而是每个节点通过每个接口仅发送它的表的一部分each node sends only part of its table through each interface。按照它的表,如果节点 B B B 认为通过 A A A 到达 X X X 是最佳路径,则节点 B B B 不需要向 A A A 通知这一部分消息,因为这一信息来自 A A A( A A A 已知道),把来自节点 A A A 的信息修改后,发送回节点 A A A 可能会产生混淆。
在前面图22.17情况下,节点 B B B 在向节点 A A A 发送它的表之前,就删除它的路由表中最后一行,节点 A A A 仍保持到 X X X 的距离为无穷大。稍后,当节点 A A A 发送它的路由表到节点 B B B 时,节点 B B B 也修改它的路由表。在第一次更新后,系统成为稳定的,两个节点 A A A 和 B B B 都知道 X X X 是不可达的。 - 分割范围与毒性逆转
Split Horizon and Poison Reverse。使用分割范围策略有一个缺点,距离向量路由协议经常使用定时器,如果没有关于一条路径的新消息,那么节点就在它的表中删除该路径Normally, the distance vector protocol uses a timer, and if there is no news about a route, the node deletes the route from its table。在前面的情况下,当节点 B B B 从「它向节点 A A A 的通知」中删除「到 X X X 的路径」时,节点 A A A 不能推断这是由于分割范围策略(信息源是 A A A ),还是因为节点 B B B 最近没有接收到关于 X X X 的消息。
分割范围策略可与毒性逆转poison reverse策略结合起来。节点 B B B 依旧可公布 X X X 的值,但如果信息源是节点 A A A ,则它用无穷大表示距离、作为警告"不要使用这个值,我知道的这个路径来自你"。
6. 三个节点不稳定性 Three-Node Instability
二个节点不稳定性可用分割范围策略和毒性逆转策略结合起来避免,但如果不稳定性存在于三个节点之间,则稳定性不能保证。如图22.18所示:
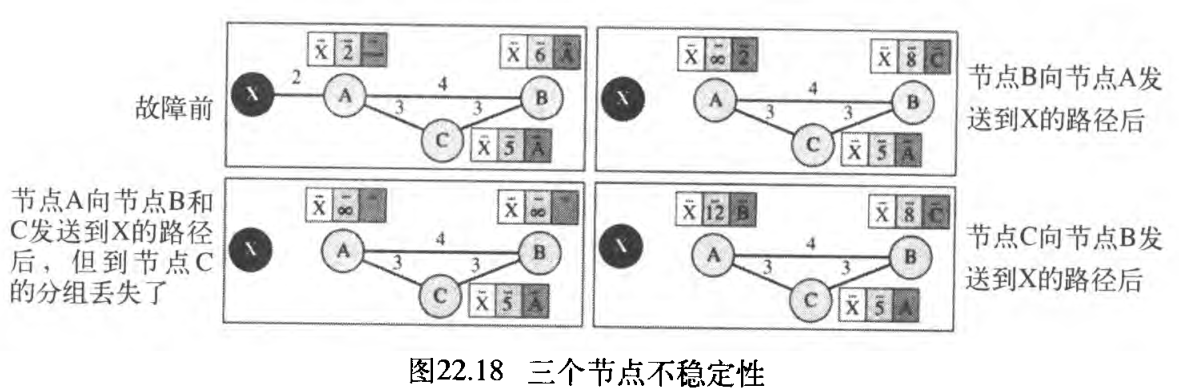
- 假设发现节点 X X X 不可达后,节点 A A A 发送一个分组给节点 B B B 和 C C C ,通知它们路径的情况,节点 B B B 立即更新它的表,可是到 C C C 的分组在网络中丢失,因此永远到达不了 C C C 。
- 节点 C C C 根本不知道,仍认为有一条通过 A A A 到达 X X X 的距离为 5 5 5 的路径。稍后,节点 C C C 向 B B B 发送它的路由表,其中包含有到 X X X 的路径。
- 节点 B B B 此时完全糊涂了。它接收到从 C C C 到 X X X 的路径信息,并按照算法更新它的路由表,其中从 C C C 到达 X X X 的代价为 8 8 8 。这个信息来自 C C C 而不是 A A A ,稍后节点 B B B 向节点 A A A 通知这条路径。
- 节点 A A A 糊涂了并更新它的路由表,指出 A A A 通过 B B B 可达到 X X X ,其代价为 12 12 12 。当然,这个循环在继续。
- 现在节点 A A A 对 C C C 、而不对 B B B 通知到达 X X X 的路径增加了代价,然后节点 C C C 用增加的代价向节点 B B B 通知该路径。节点 B B B 向节点 A A A 重复相同的操作等。当每个节点的代价到达无穷大时,循环停止。
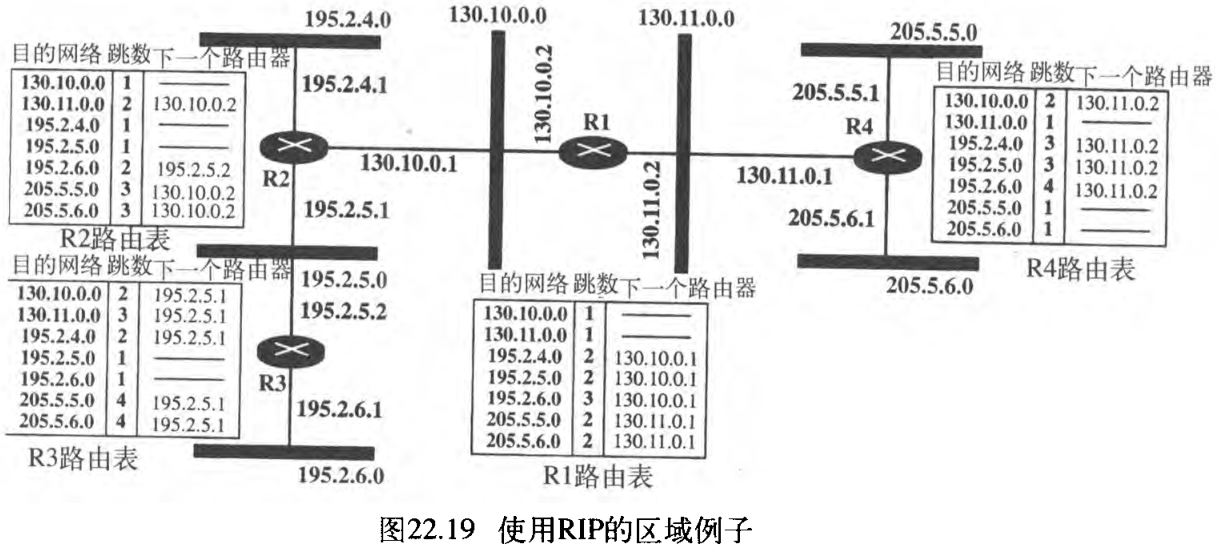
7. RIP(经典协议)
路由选择信息协议 Routing Information Protocol 是一个在自治系统内部使用的域内路由选择协议,它是基于距离向量路由选择的、一个非常简单的协议。RIP基于下列考虑,直接地实现距离向量路由选择:
- 在一个自治系统中,包括了路由器和网络(链路)。路由器有路由表,而网络没有路由表;
- 路由表中的目的端这一列是网络,这意味着,它的第一列定义了目的网络地址;
- RIP用的度量很简单,距离定义为到达目的端的链路(网络)个数
the number of links (networks) to reach the destination。因此,RIP的度量称为跳数hop count; - 16 16 16 就定义为无穷大,即在使用RIP的任何自治系统中,任何路径不能大于 15 15 15 跳。
- 下一个节点这一列,定义为被发送分组所要到达的目的路由器的地址。
图22.19表示了一个具有 7 7 7 个网络和 4 4 4 个路由器的自治系统,也表示了每个路由器的路由表,该表有 7 7 7 个项目,表示了在这个自治系统中如何到达每个网络。
- 路由器R1直接连接到网络 130.10.0.0 130.10.0.0 130.10.0.0 和 130.11.0.0 130.11.0.0 130.11.0.0 ,这意味着对于这两个网络没有下一跳项目。
- 向左边远方 3 3 3 个网络之一发送一个分组,路由器R1需要R2传递该分组。对这 3 3 3 个网络的下一跳项目,是IP地址为 130.10.0.1 130.10.0.1 130.10.0.1 的R2接口。
- 向右边远方
2
2
2 个网络发送一个分组,路由器R1需要IP地址为
130.11.0.1
130.11.0.1
130.11.0.1 的路由器R4。其他表可相似地解释。
22.3.4 链路状态路由选择
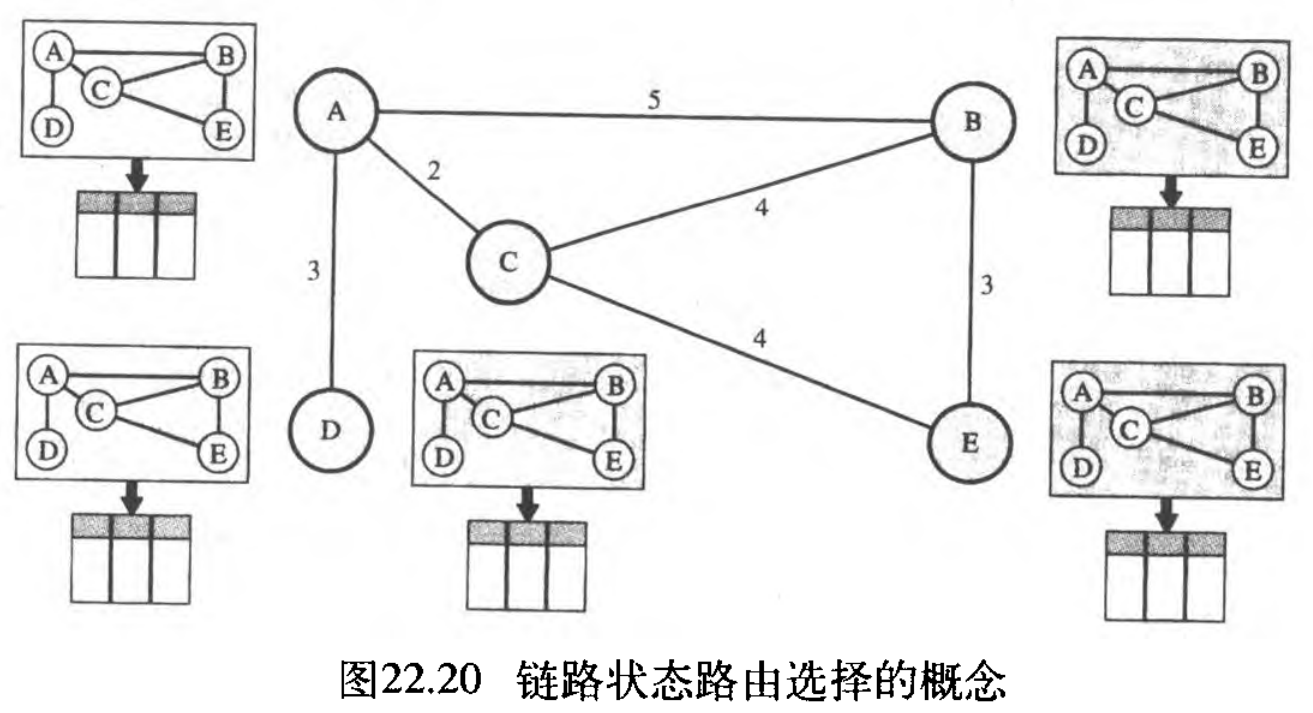
链路状态路由选择与距离向量路由选择的基本原理不同。在链路状态路由选择中,如果域中的每一个节点拥有该域 domain 的整个拓扑结构——所有节点和链路的列表、它们是如何连接的(包括类型、代价/度量、以及链路的接通或断开的状态),这个节点就可根据这个拓扑结构,用 Dijkstra's algorithm 建立一个路由表 if each node in the domain has the entire topology of the domain——the list of nodes and links, how they are connected including the type, cost (metric), and condition of the links (up or down), the node can use Dijkstra's algorithm to build a routing table 。图22.20表示了这一概念。
该图显示了具有
5
5
5 个节点的简单区域,每个节点使用相同的拓扑来建立各自的路由表,但是每个节点的路由表是唯一的,因为计算是基于对该拓扑的不同解释。这类似于一个城市的地图,虽然每个人可能拥有相同的地图,但每个人都需要采取不同的路线,才能到达他们的特定目的地 take a different route to reach her specific destination 。
拓扑必须是动态的,表示每个节点和每个链路的最新状态 The topology must be dynamic, representing the latest state of each node and each link 。如果网络中的任一点有改变(例如,某一链路断开连接) ,则必须更新每个节点的拓扑。
如何使公共拓扑成为动态的,并将其存储在每个节点中?没有一个节点可以在开始时、或在网络上的某处发生变化后,就能知道该拓扑。链路状态路由选择是基于这样的假设——虽然有关拓扑的全局知识并不清晰,但每个节点都有部分知识:它知道自己这一部分的链路状态(类型、条件和成本)it knows the state (type, condition, and cost) of its links 。换言之,整个拓扑可由每一个节点的部分知识复合而成 the whole topology can be compiled from the partial knowledge of each node 。图22.21的域与图22.20的域相同,但它表示了属于每个节点的部分知识。
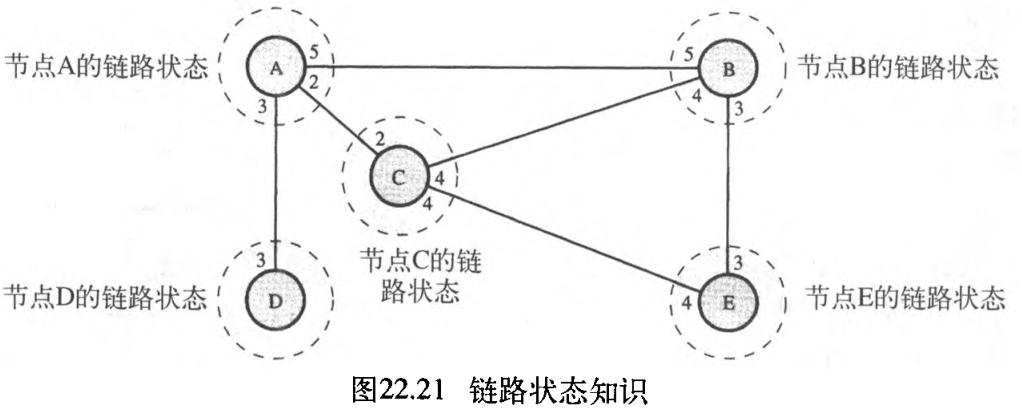
节点
A
A
A 知道它与节点
B
B
B 连接的度量为
5
5
5 ,与节点
C
C
C 连接的度量为
2
2
2 ,与节点
D
D
D 连接的度量为
3
3
3 。节点
C
C
C 知道它与节点
A
A
A 连接的度量为
2
2
2 ,与节点
B
B
B 连接的度量为
4
4
4 ,与节点
E
E
E 连接的度量为
4
4
4 。节点
D
D
D 知道它与节点
A
A
A 连接的度量为
3
3
3 等等。虽然知识有重叠部分,但这个重叠部分保证了为每个节点创建一个公共拓扑(整个域的图景 a picture of the whole domain )。
1. 建立路由表
在链路状态路由选择 link state routing 中,为了保证每个节点都有这样的路由表,其能显示到其余每个节点的成本最低的节点 showing the least-cost node to every other node ,需要做
4
4
4 件事:
- 由每个节点创建链路状态,称为链路状态分组
LSP; - 用一种有效而可靠的方式,向其他每个路由器扩散
LSP,这称为洪泛flooding; - 为每个节点构成一个最短路径树
shortest path tree; - 基于最短路径树计算路由表。
2. 链路状态分组 LSP 的生成
链路状态分组可携带大量信息。但是,我们假定它携带最小的数据量:节点的标识、链路的清单、序列号和寿命 the node identity, the list of links, a sequence number, and age 。前两个是节点标识和链路清单,它们是生成拓扑所需要的。第三个是序列号,它有助于/用于洪泛,并将新的 LSP 与旧的 LSP 区分开来 。第四个是寿命,它防止旧的 LSP 在域中长期保留。LSP 在两种情况下生成:
- 当域的拓扑有变化时
When there is a change in the topology of the domain,触发LSP扩散Triggering of LSP dissemination是快速通知域中任一节点更新其拓扑的主要方法。 - 基于周期性产生
On a periodic basis。在这种情况下,其周期比距离向量路由选择的周期长得多。事实上,这种类型的LSP扩散没有实际的需要there is no actual need for this type of LSP dissemination。这样做是为了确保旧信息从域中删除。
根据实现情况,为定期传播设置的计时器(设定的范围)通常在 60 60 60 分钟或 2 2 2 小时内。一个更长的周期,可以保证洪泛不会在网络上产生太多通信量。
3. LSP 洪泛法
一个节点准备好 LSP 之后,必须将其向所有其他节点扩散,而不仅仅是其邻站。这个过程称为洪泛,按下列几步进行:
- 创建节点将其
LSP的副本,从每个接口发出; - 接收到
LSP的每个节点,将其与可能已有的副本进行比较compares it with the copy it may already have。如果新到达的LSP是比较旧的(用列序号检验),则丢弃该LSP;如果是比较新的,则该节点执行下面的工作:
a. 它丢弃旧的LSP,保留新的LSP;
b. 节点从它的每个接口发送一份副本,但分组到达的接口除外。这保证了洪泛会在域中的某处停止(其中某个节点只有一个接口)。
4. 最短路径树的构成:Dijkstra算法
接收到所有的 LSP 后,每个节点就有了完整的拓扑副本,然而,拓扑结构不足以找到「到其他节点的最短路径」;需要一个最短路径树 shortest path tree 。
树是由节点与链路组成的图 A tree is a graph of nodes and links ,其中有一个节点称为根,所有其他节点都可从根开始通过唯一的一条路径 only one single route 到达。最短路径树是根与其他节点之间路径最短的一个树 A shortest path tree is a tree in which the path between the root and every other node is the shortest 。对每个节点,我们都需要创建一个「以该节点为根的最短路径树」。
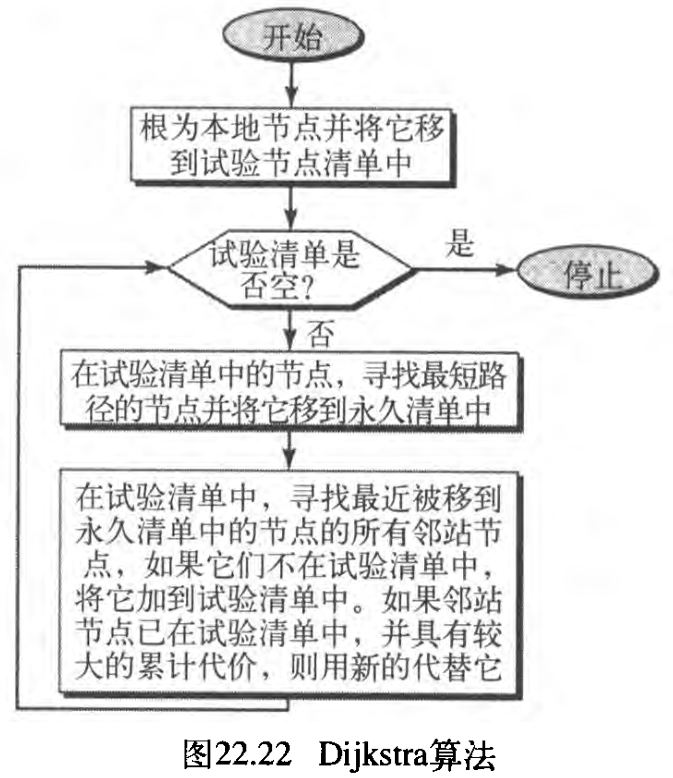
Dijkstra algorithm 从图创建一个最短路径树。该算法将节点划分成两个集合:试验的和永久的 tentative and permanent 。它会找到当前节点的邻居节点,使其成为临时的,检查它们,如果它们通过标准,则使其成为永久的。我们可以用图22.22中的流程图,非形式化地定义该算法。
- 将根节点设置为本地节点,并将其移动到临时列表
Set root to local node and move it to tentative list。 - 在临时列表中的节点中,将有着路径最短的节点移动到永久列表
Among nodes in tentative list, move the one with the shortest path to permanent list。 - 将最近被移动(到永久列表中)的节点的每个未处理邻站节点,添加到临时列表中(如果还没有这么做的话)。如果邻站节点已在临时列表中,且具有较大的累积代价,则用新的替换它
Add each unprocessed neighbor of last moved node to tentative list if not already there. If neighbor is in the tentative list with larger cumulative cost, replace it with new one。
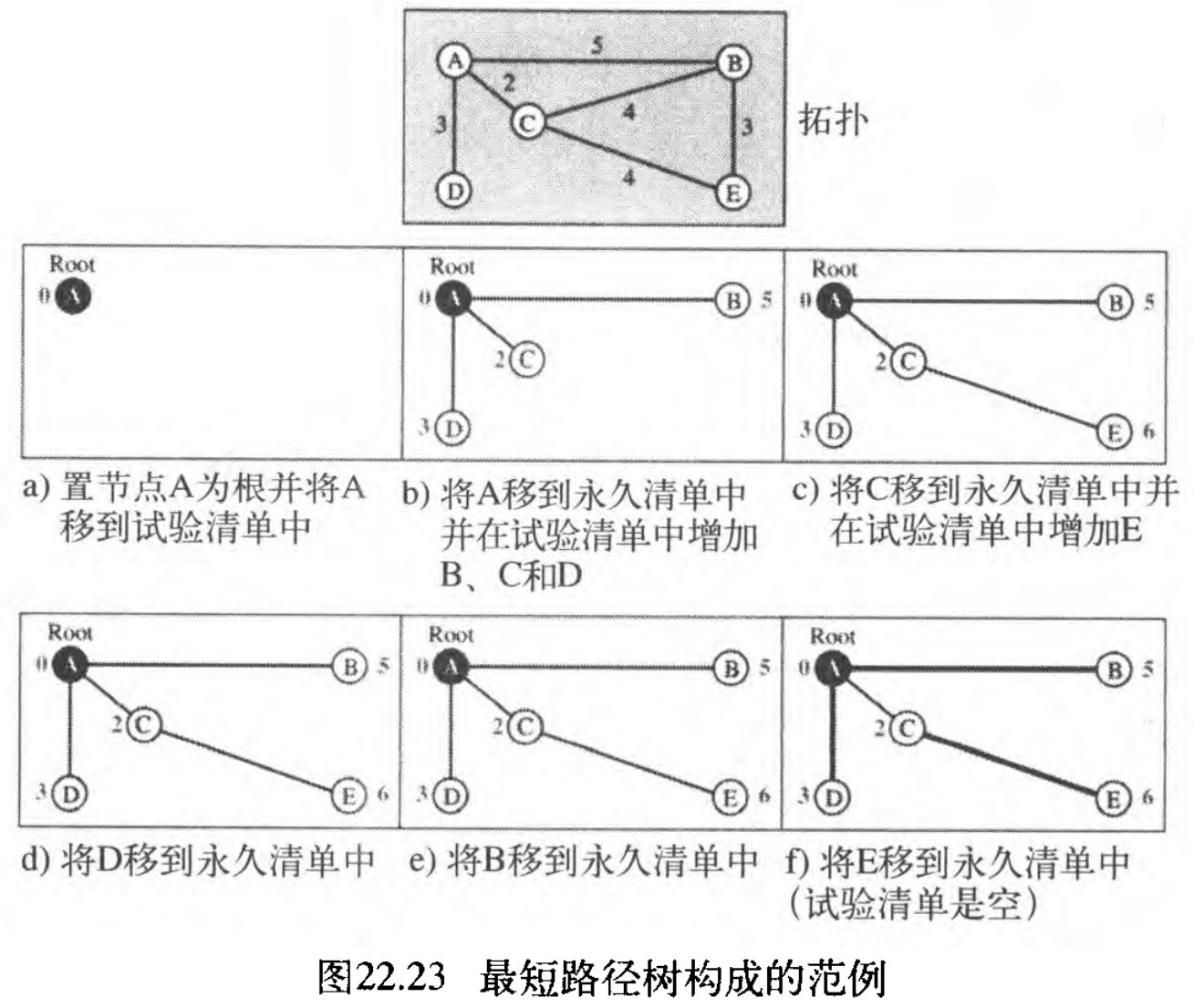
让我们用该算法应用于节点
A
A
A ,如图22.23所示。为了在每一步中找到最短路径,我们需要计算从根到每个节点的累计代价 To find the shortest path in each step, we need the cumulative cost from the root to each node ,它已显示在节点旁边。
下面显示了这些步骤。在每一步结束,我们展示了永久性的(填充的圆圈)和试验性的(开放的圆圈)节点,以及带有累积成本的列表。
-
我们设置节点 A A A 为树的根,并将它移到试验清单中。两个清单是:
永久清单:空 试验清单: A(0) -
与试验清单中的所有节点相比,节点 A A A 有最短的累计代价,我们将 A A A 移到永久清单中,并在试验清单中增加 A A A 的所有邻站。两个新的清单是:
永久清单: A(0) 试验清单: B(5), C(2) , D(3) -
在试验清单中的所有节点中,节点 C C C 有最短累计代价,我们将 C C C 移到永久清单中,节点 C C C 有 3 3 3 个邻站,但节点 A A A 已处理,那些没有处理的是 B B B 和 E E E 。但是 B B B 已在试验清单中、且累计代价为 5 5 5 ,节点 A A A 也可经过 C C C 到达节点 B B B ,其代价为 6 6 6 。因为 5 < 6 5 < 6 5<6 ,我们在试验清单仍保留累计代价为 5 5 5 的节点 B B B 而不替换它。两个新的清单是:
永久清单: A(0), C(2) 试验清单: B(5), D(3), E(6) -
在试验清单中的所有节点中,节点 D D D 有最短累计代价,我们将 D D D 移到永久清单中,节点 D D D 没有要添加到试验清单中的未处理邻站。两个新的清单是:
永久清单: A (0), C(2), D(3) 试验清单: B(5), E(6) -
在试验清单中的所有节点中,节点 B B B 有最短累计代价,我们将 B B B 移到永久清单中。我们需要将 B B B 的所有未处理邻居添加到试验清单中(这个节点正是 E E E )。但是, E ( 6 ) E(6) E(6) 已在该清单中、并具有最小的累计代价。作为 B B B 的邻站 E E E 的累计代价是 8 8 8 ,所以我们仍保留节点 E ( 6 ) E(6) E(6) 在试验清单中。两个新的清单是:
永久清单: A(0), B(5), C(2), D(3) 试验清单: E(6) -
在试验清单中的所有节点中,节点 E E E 有最短累计代价,我们将 E E E 移到永久清单中,节点 E E E 没有邻站。现在试验清单为空,我们停止处理。最短路径树已构成,最后的清单是:
永久清单: A(0), B(5), C(2), D(3), E(6) 试验清单:空
5. 从最短路径树计算路由表
每个节点用最短路径树协议 the shortest path tree protocol 构造它的路由表,路由表显示了从根到每个节点的代价。表22.2表示了节点
A
A
A 的路由表。将表22.2与图22.14中节点
A
A
A 的路由表相比较,对于节点
A
A
A ,距离向量路由选择与链路状态路由选择的最终结果相同。

6. OSPF(经典协议)
开放最短路径优先或OSPF协议 Open Shortest Path Frist protocol 是基于链路状态路由选择的、一个域内路由选择协议。它的域也是一个自治系统 Its domain is also an autonomous system 。
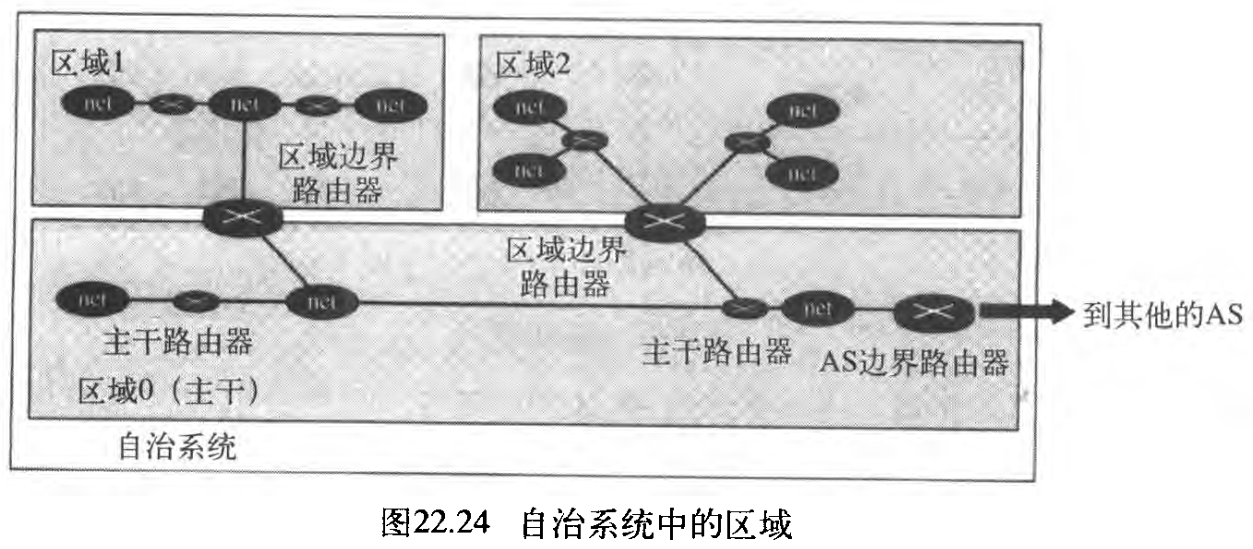
(1) 区域
为了有效地和及时地处理路由选择,OSPF将自治系统划分为一些区域。一个区域 area 是包含在自治系统中的一些网络、主机和路由器的集合 a collection of networks, hosts, and routers all contained within an autonomous system 。自治系统可以划分为多个不同的区域,在一个区域内的所有网络必须是互相连接的。
在一个区域内的路由器,都使用洪泛法传送路由选择信息。而在一个区域的边界,称为区域边界路由器 area border router 的一些特殊的路由器,将有关本区域的信息概括起来发送给其他区域。
在自治系统中,有一个特殊区域称为主干 backbone ,在自治系统中的所有区域必须连接到主干上。换言之,主干相当于主区域,而且其他区域相当于从区域。但是,这并不意味着在各区域内的路由器不能相互连接 the routers within areas cannot be connected to each other 。在主干中的路由器称为主干路由器 backbone router 。注意:一个主干路由器也可以同时是一个区域的边界路由器。
如果由于某些问题,在主干和区域之间的连通性被破坏了,则网络管理员就必须在路由器之间建立一条虚链路 virtual link ,以保持「作为主区域的主干」的各种功能的连续性 allow continuity of the functions of the backbone as the primary area 。每一个区域都有一个区域标识 area identification ,主干的区域标识是
0
0
0 。图22.24显示了一个自治系统及其他的区域。
(2) 度量
OSPF协议允许网络管理员给每一条路由指定一个代价,称为度量 metric 。度量可以基于服务类型(最小延迟、最大吞吐量等)。事实上,一个路由器可以有多个路由表,而每一个路由表基于不同的服务类型 a router can have multiple routing tables, each based on a different type of service 。
(3) 链路类型
在OSPF术语中,一个连接称为链路。己定义了
4
4
4 种类型的链路:点对点链路、过渡链路、残桩链路和虚链路(见图22.25)。
-
点到点链路
point-to-point link连接两个路由器,而中间没有任何其他的主机或路由器。换言之,该链路(网络)的目的就是为了连接两个路由器。这种链路类型的例子就是:两个路由器用一条电话线(或一条T线)连接起来。没有必要给这种类型的链路指定一个网络地址。
用图表示时,路由器用节点表示,而链路用一条连接两个节点的双向边来表示。度量通常是相同的,显示在两端,每个方向一个。即每个路由器在链路的另一端只有一个邻站(见图22.26)。
-
过渡链路
transient link是一种连接多个路由器的网络。数据可以通过任何一个路由器进入网络,并从任何一个路由器离开网络。所有的局域网和某些具有两个或更多的路由器的广域网都属于这种类型。在这种情况下,每一个路由器都有好几个邻站。例如,考虑图22.27a中的以太网。路由器 B B B 的邻站是路由器 A , C , D , E A, C , D, E A,C,D,E 。如果我们要表示这种情况下的邻站关系,就使用图22.27b。
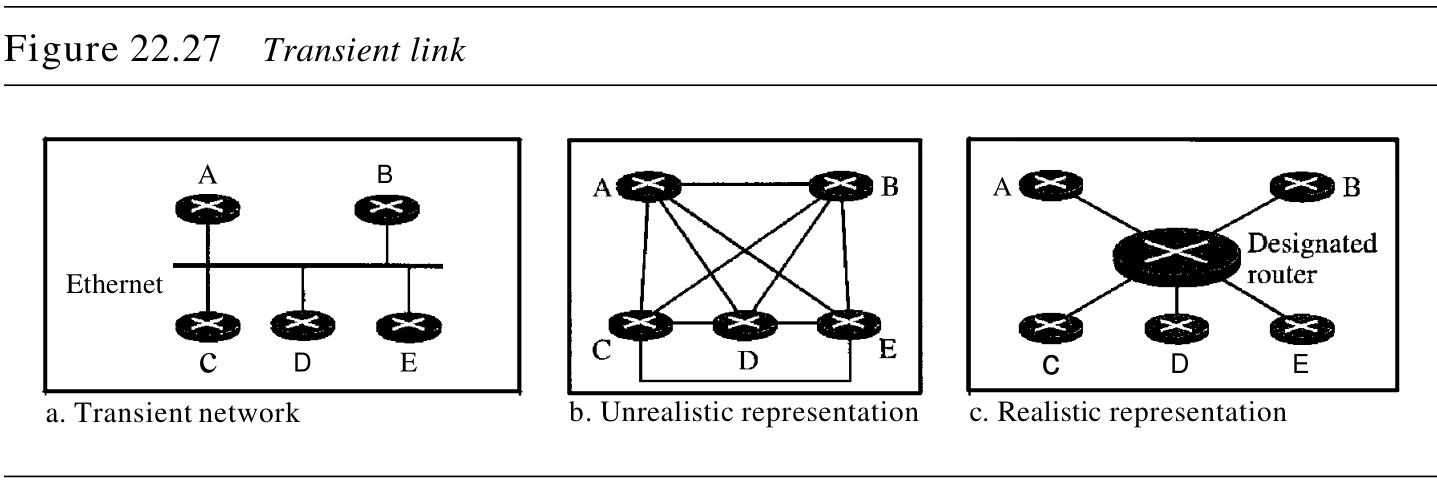 这种链路既低效又不实际,低效是因为:每一个路由器需要通知其他
4
4
4 个邻站的路由器,总共有
20
20
20 个通知;不实际是因为:在每一对路由器之间没有一个单独的网络(链路),只有一个网络用做所有这
5
5
5 个路由器之间的交叉路口。
这种链路既低效又不实际,低效是因为:每一个路由器需要通知其他
4
4
4 个邻站的路由器,总共有
20
20
20 个通知;不实际是因为:在每一对路由器之间没有一个单独的网络(链路),只有一个网络用做所有这
5
5
5 个路由器之间的交叉路口。为了表示出每一个路由器是通过一个单独网络连接到其他的每一个路由器,我们将这个网络用一个节点来表示。但是,网络并不是一个机器,它不能像路由器那样工作。因此,在网络中某一个路由器就要负起这个责任。这个路由器有双重作用,它是一个真的路由器,又是一个指定路由器
a true router and a designated router,用图22 .27c的拓扑结构可以表示过渡网络的连接。
一方面,现在每一个路由器只有一个邻站,即指定路由器(网络),另一方面,这个指定路由器(即网络)有 5 5 5 个邻站。我们可看到,向邻站通知的数目由 20 20 20 减少到 10 10 10 。另外,链路用连接节点的双向边来表示。不过,虽然从每一个节点到指定路由器都有一个度量,但从指定路由器到其他任何节点都没有度量,原因就是指定路由器代表了网络,我们不能为它计算两次——当一个分组进入网络时,我们指定一个代价;当分组离开网络到其他路由器时,就没有代价
When a packet enters a network, we assign a cost; when a packet leaves the network to go to the router, there is no charge.。 -
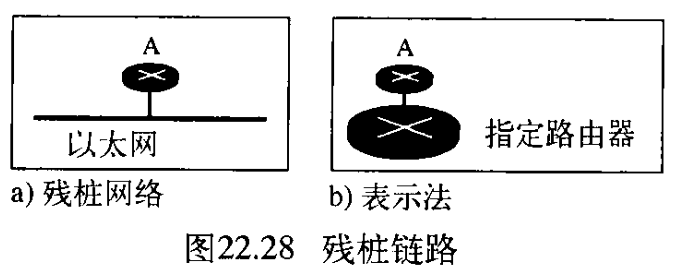
残桩链路
stub link是只连接到一个路由器的网络。数据分组通过这个单一的路由器进入网络,然后通过这个路由器离开网络。这是过渡网络的一个特例。对于这种情况,可以将路由器表示为一个节点,而用指定路由器表示这个网络。但是,链路是单向的,即从路由器到网络the link is only one-directional, from the router to the network(见图22.28)。
-
当两个路由器之间的链路断开肘,网络管理员就在它们之间使用一条更长的路径,它可能经过好几个路由器,创建一条虚链路
virtual link。
(4) 图形表示
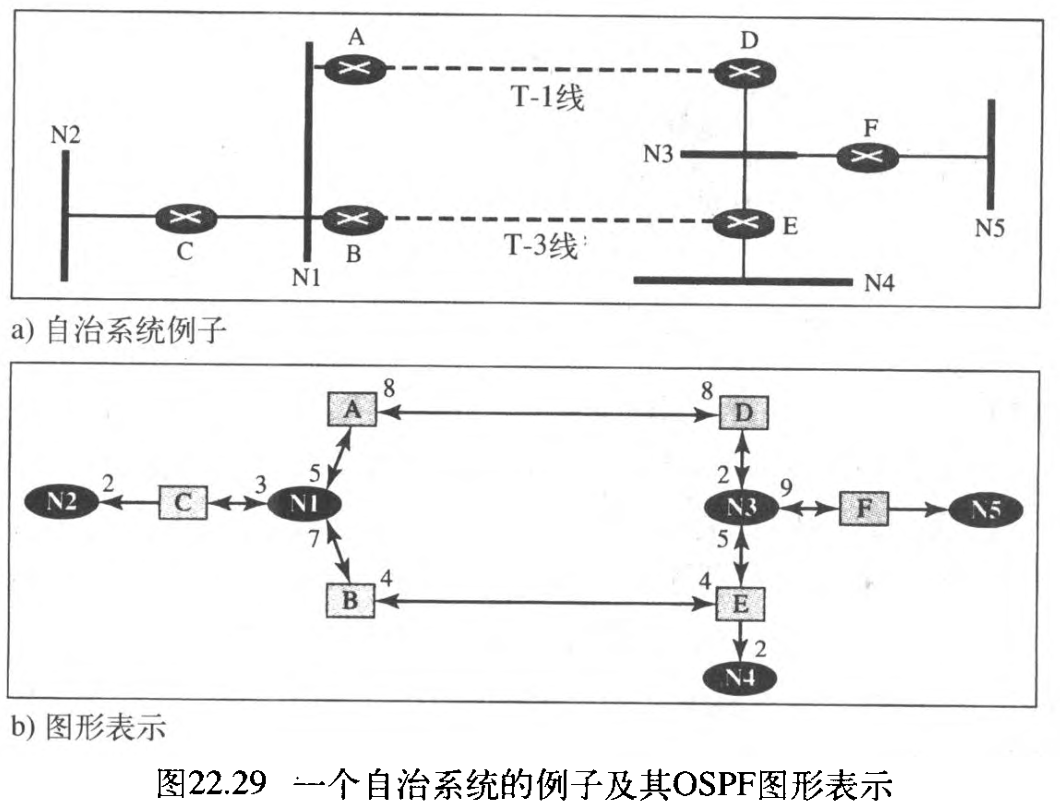
现在让我们考虑一个自治系统如何用图形表示。图22.29表示了具有
7
7
7 个网络和
6
6
6 个路由器的一个小型自治系统。有两个网络是点到点网络,我们使用记号如
N
1
N1
N1 和
N
2
N2
N2 表示过渡网络和残桩网络。没有必要给点到点网络指定一个标识符。该图也表示OSPF所见到的自治系统的图形。我们用正方形节点表示路由器,用椭圆节点表示网络(由指定路由器表示的网络)。但是,OSPF将两者都看做节点。注意:我们共有
3
3
3 个残桩网络。
22.3.5 路径向量路由选择
距离向量路由选择和链路状态路由选择都是域内路由选择协议 intradomain routing protocol 。它们用于一个自治系统内部,而不是自治系统之间。因为可扩展性 scalability ,这两个协议都不适合域间路由选择 interdomain routing ,当操作区域变大时,这两个路由选择协议变得很难处理 intractable ——如果在操作区域中存在较多跳数,距离向量路由选择协议是不稳定的;而链路状态路由选择协议需要有巨大的资源来计算路由表,且因为洪泛也会产生严重的通信拥塞 It also creates heavy traffic because of flooding 。因此,需要第三个路由选择协议,我们称它为路径向量路由选择 path vector routing 。
已经证明,路径向量路由选择对区域之间的路由选择是有用的,它的原理与距离向量路由选择相似 The principle of path vector routing is similar to that of distance vector routing 。在路径向量路由选择中,我们假定:在每个自治系统中,都有一个节点(可以有更多,但对于我们的概念性讨论,一个已足够)代表了整个自治系统,该节点称为发言人节点 speaker node(或为代言结点)。一个自治系统的发言人节点生成一个路由表,并将其通知给相邻自治系统中的发言人节点。
除了「每个自治系统仅有发言人节点可以彼此通信」外,它与距离向量路由选择的思想相同 The idea is the same as for distance vector routing except that only speaker nodes in each AS can communicate with each other 。但通知的内容是不同的,一个发言人节点在它的自治系统或其他自治系统中通告路径 advertises the path(在它的自治系统或其他自始系统中的路径),而不是节点(跳数)的度量 the metric of the nodes 。
1. 初始化
在开始时,每个发言人节点仅能知道它的自治系统内部节点的可达性 the reachability of nodes inside its autonomous system 。图22.30表示了「
4
4
4 个自治系统组成的互联网络」中每个发言人节点的初始路由表。
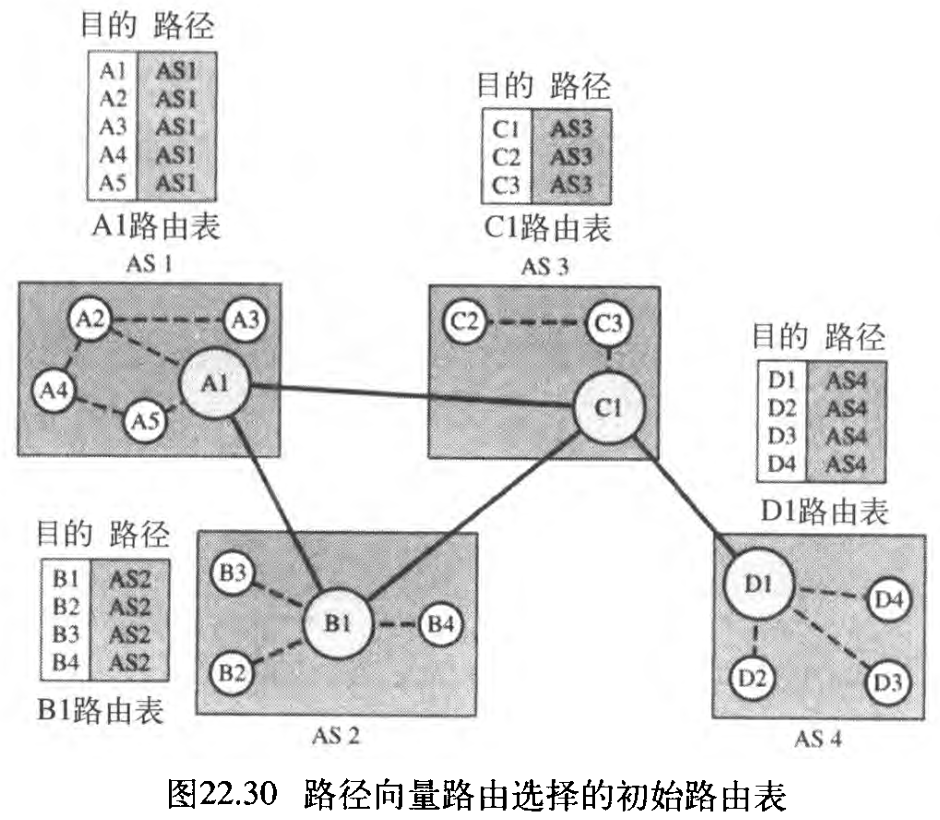
节点 A1 是 AS1 的发言人节点,节点 A2 是 AS2 的发言人节点,节点 C1 是 AS3 的发言人节点,节点 D1 是 AS4 的发言人节点。节点 A1 创建一个初始表,显示 A1 到 A5 位于 AS1 中,并且可以通过它到达 can be reached through it 。节点 B1 生成一个初始路由表,通知 B1 到 B4 位于 AS2 中,并且可以通过 B1 到达 can be reached through B1 等等。
2. 共享
正如距离向量路由选择那样,在路径向量路由选择中,「一个自治系统的一个发言人节点」与「它邻站的发言人节点」共享它的路由表 Just as in distance vector routing, in path vector routing, a speaker in an autonomous system shares its table with immediate neighbors 。在图22.30中,节点 A1 与 B1 及 C1 共享它的路由表,节点 C1 与节点 D1, B1 及 A1 共享它的路由表,节点 B1 与节点 C1 及节点 A1 共享它的路由表,以及节点 D1 与 C1 共享它的路由表。
3. 更新
当一个发言人节点从一个邻站接收到一个两列的路由表时,它更新它自己的路由表,更新内容包括「增加不在表中的节点 adding the nodes that are not in its routing table 」以及「其自治系统与发送方的自治系统之间的路径」it updates its own table by adding the nodes that are not in its routing table and adding its own autonomous system and the autonomous system that sent the table 。此后,每一个发言人节点都有一张路由表,并且知道如何到达其他自治系统中的各个节点。图22.31表示系统稳定后,每一个发言人节点的路由表。
按照图22.31,如果路由器 A1 接收一个到节点 A3 的分组,它知道这条路径是在 AS1 中(分组在本自治系统内)。但如果它接收一个到 D1 的分组,它知道这分组应该从 AS1 到 AS2 、然后再到 AS3AS3 、然后再到 AS4 ,图画错了),路由表完全表示了该路径。另外,如果 AS4 中的节点 D1 接收一个到节点 A2 的分组,它知道应该经过 AS4, AS3, AS1 。

- 预防回路
loop prevention。在路径向量路由选择中可以避免「距离向量路由选择的不隐定性和回路的产生」。当路由器接收到报文时,它要检查「它所在的自治系统」是否在「到达目的网络的路径列表」中When a router receives a message, it checks to see if its autonomous system is in the path list to the destination。如果是的话,就会产生回路,这个报文就被忽略。 - 策略路由选择
policy routing。通过路径向量路由选择,可以很易地实现策略路由选择。当路由器接收到报文时,它就检查其路径:如果在路径中所列出的某个自治系统不符合其策略,它就忽略这条路径和其目的端,它不用这条路径更新其路由表,也不将这个报文发送给它的邻站节点It does not update its routing table with this path, and it does not send this message to its neighbors。 - 优化路径
optimum path。什么是在路径向量选择中最佳的路径?我们在自治系统中寻找一条通往目的端的路径,这条路径对运行自治系统的组织来说是最好的We are looking for a path to a destination that is the best for the organization that runs the autonomous system。我们绝对不能在这条路径中包含度量,因为路径中包含的每个自治系统中,可能使用不同度量准则——某个自治系统可能在内部使用RIP,它将跳数定义为度量defines hop count as the metric。而另一个自治系统可以使用OSPF,它将最小延迟定义为度量minimum delay defined as the metric……所以在这个路由中不可能明确地含有这些度量。
最佳路径是符合组织机构标准的路径The optimum path is the path that fits the organization。在图22.30中,每个自治系统可能有多条到达目的端的路径。例如,AS4到AS1可以是AS4-AS3-AS2-AS1,或者AS4-AS3-AS1。对于这些路径,我们选取经过自治系统数目最小的一条For the tables, we chose the one that had the smaller number of autonomous systems。但也不总是这种情况,还有其他准则可被应用,如保密、安全和可靠性。
4. BGP(经典协议)
边界网关协议 Border Gateway Protocol, BGP 是使用路径向量路由选择的域间路由选择协议。它于1989年问世,现已有
4
4
4 个版本。
(1) 自治系统类型
正如以前我们说过,因特网被划分成多层次的域 hierarchical domains ,称为自治系统。例如,管理自己的网络、并完整控制它的一个大型企业是一个自治系统,为本地客户提供服务的本地ISP也是一个自治系统。自治系统可分三大类:残桩的、多接口的和转送的 stub, multihomed, and transit 。
- 残桩自治系统
Stub AS。它与其他自治系统只有一个连接,在一个残桩自治系统中,域间数据流量要么起始、要么终止于该自治系统。该自治系统中的主机可以向其他自治系统发送数据流量,该自治系统中的主机可以接收来自其他自治系统中的主机的数据,即 「其源IP地址或目的IP地址所指定的主机」位于该自治系统中。但是,数据流量不能通过残桩自治系统Data traffic, cannot pass through a stub AS。残桩自治系统或者是一个源端或者是一个接收器either a source or a sink。好的例子是小型企业或小的本地ISP 。 - 多接口自治系统
Multihomed AS。它与其他自治系统有多个连接,但它仍然只是数据流量的源端或接收器it is still only a source or sink for data traffic。它能接收来自多个自治系统的数据流量,也能发送数据流量到多个自治系统,但没有过渡的数据流量。它不允许来自一个自治系统的数据经它转发到另一个自治系统。一个多接口自治系统的例子是,一个连接到多个区域或国家自治系统的大型企业,它不允许转送数据。 - 转送自治系统
Transit AS。它是一个多接口自治系统,但它允许过渡数据流量also allows transient traffic。过渡自治系统的例子是国家或国际ISP(因特网主干网)。
(2) 路径属性
在前面的例子中,我们讨论到目的网络的路径 a path for a destination network 。这个路径可以用一个自治系统的列表 a list of autonomous systems 来表示,但实际上是用属性的列表 a list of attributes 来表示的。每一个属性给出关于路径的一些信息。属性列表在应用其策略时,有助于接收信息的路由器做出更明智的决定。
属性可分为两大类:熟知的和可选的。熟知属性 well-known attribute 是每一个BGP路由器必须知道的,而可选属性 optional attribute 则不需要被每一个路由器都知道。
熟知属性本身又可划分为两类:强制的 mandatory 和自选的 discretionary 。熟知强制属性 well-known mandatory attribute 是在一条路由的描述中必须出现的属性,熟知自选属性 well-known discretionary attribute 是每一个路由器必须知道的,但不一定需要包括在每一个更新报文中。
- 一个熟知强制属性是
ORIGIN,它定义路由选择信息(RIP、OSPF等等)的来源; - 另一个熟知强制属性是
AS_PATH,它定义了「通过其可以到达目的地的自治系统」的列表; - 还有一个熟知强制属性是
NEXT-HOP,它定义分组应该发送到的下一个路由器。
可选属性也可以划分为两类:传递的 transitive 和非传递的 nontransitive 。可选传递属性 optional transitive attribute 是「没有实现这个属性的路由器」必须传递给下一个路由器的属性,可选非传递属性 optional nontransitive attribute 是如果接收路由器还没有实现这个属性、就必须丢弃的属性。
(3) BGP会话
使用 BGP 的两个路由器之间的路由信息的交换产生一次会话。会话是两个BGP系统仅为交换路由选择信息而建立的一次连接 A session is a connection that is established between two BGP routers only for the sake of exchanging routing information 。为了可靠性,BGP使用TCP作为其传输层协议。换言之,BGP级别的会话,作为一个应用程序,是TCP级别的连接。
但是,为BGP和其他应用程序建立的 TCP连接之间存在细微差别——当为BGP创建TCP连接时,它可能会持续很长时间,直到发生某些不寻常的事件。因此,BGP会话有时称为半永久连接 semipennanent connections 。
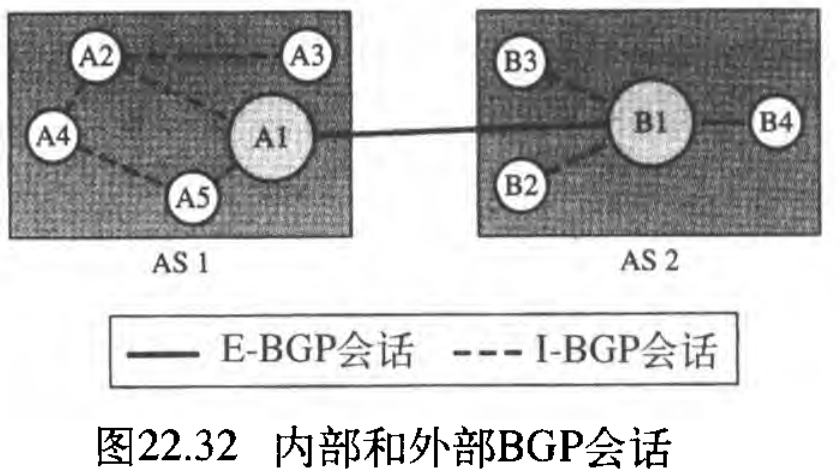
(4) 外部与内部BGP会话
再明确些,有两种类型的BGP会话:外部BGP external BGP, E-BGP 会话和内部BGP internal BGP, I-BGP 会话。
- E-BGP会话用于「属于两个不同自治系统的两个发言人节点」之间交换信息;
- I-BGP会话用于「一个自治系统内部的两个路由器」之间交换路由信息。
图22.32表示了这一思想。AS1 与 AS2 之间建立的会话是E-BGP会话,两个发言人路由器交换它们所知道的、有关因特网中网络的信息。但是,这两个路由器需要从自治系统中的其他路由器收集信息,这是由I-BGP会话完成。


















 152
152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











