






钢铁行业是以从事黑色金属矿物采选和黑色金属冶炼加工等工业生产活动为主的工业行业,包括金属铁、铬、锰等的矿物采选业、炼铁业、炼钢业、钢加工业、铁合金冶炼业、钢丝及其制品业等细分行业,是国家重要的原材料工业之一。钢铁冶炼一般以工业煤气作为燃料,因涉及一氧化碳含量很高的高炉煤气、转炉煤气、焦炉煤气。主要产生气体:一氧化碳,天然气,氢气,甲烷,氧气等。这些可燃有毒有害的气体,一旦泄漏并与周围空气混合,会形成具有爆炸危险的混合物,存在严重的安全隐患。基于以上原因,钢铁企业规范设置安装在线式气体检测报警仪,对空气中的气体浓度数据进行监测并预警,在这些气体达到危害值之前做好相关措施来避免事故的发生,促进企业安全生产。气体检测报警仪按照检测气体种类分为可燃性气体检测报警仪和有毒气体检测报警仪。

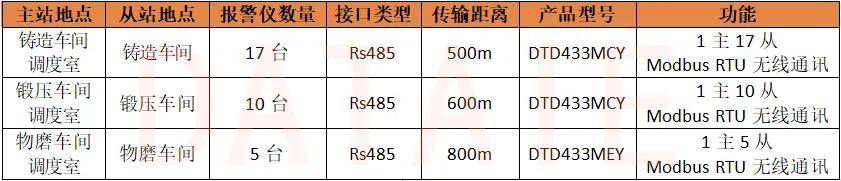
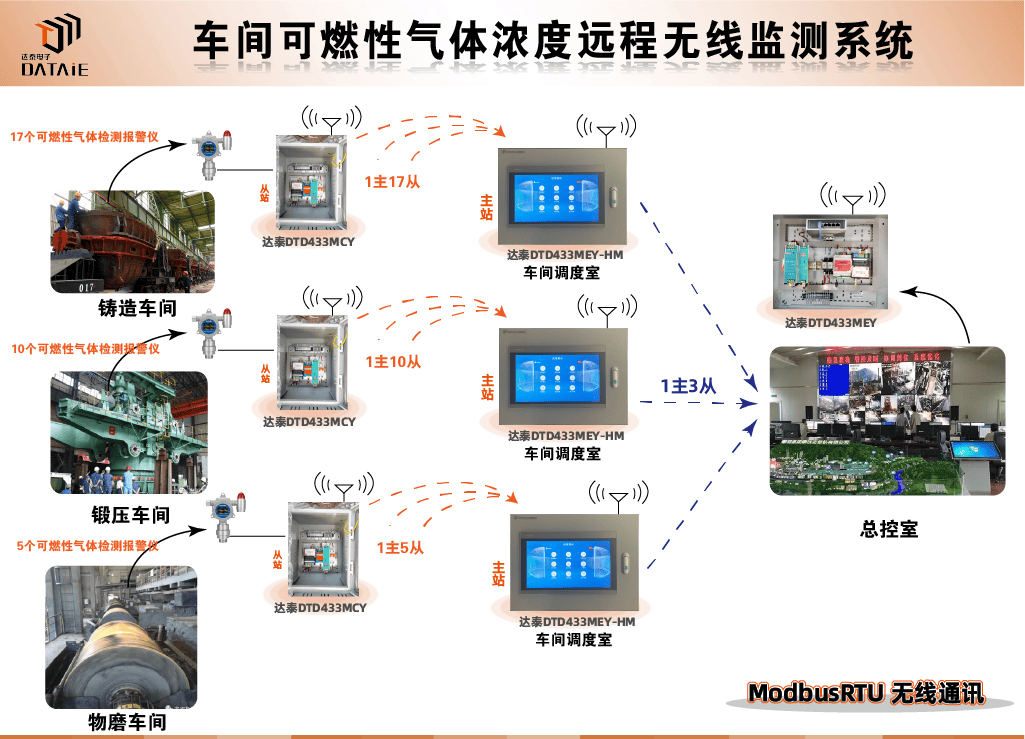
本次客户需要对生产厂区内铸造、锻压、物磨三大车间的32处可燃性气体浓度数据在总控室触摸屏端进行实时监测,并在检测到既定浓度时,监测点,车间调度室及总控室都发出声光报警信号。
由于现场工作环境复杂,钢架结构隔挡较多,可燃气体报警器安装地点分散,距离不等,现场通讯设备的选择需要格外注意稳定性与抗干扰性。考虑上述因素,达泰PLC无线通讯专家决定采用达泰工业级无线通信装置-DTD433MY来实现客户提出的技改需求。
本次技改分两个阶段完成,第一阶段是实现各车间的触摸屏与可燃气体报警器之间的Rs485无线Modbus通讯功能;第二阶段是实现3个车间触摸屏与车间调度室触摸屏之间的Modbus无线通讯功能。
第一阶段改造:
第二阶段改造:
分别在总控室触摸屏与车间调度室触摸屏端安装一台达泰DTD434MEY工业级无线通信装置,实现总控室触摸屏与各车间调度室触摸屏之间1主3从的无线MODBUS数据传输交互功能。
无线通讯方案示意图 ▼















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









