






第一章 环境
Ubuntu 14.10
Linux Kernel 3.18.6
第二章 调试
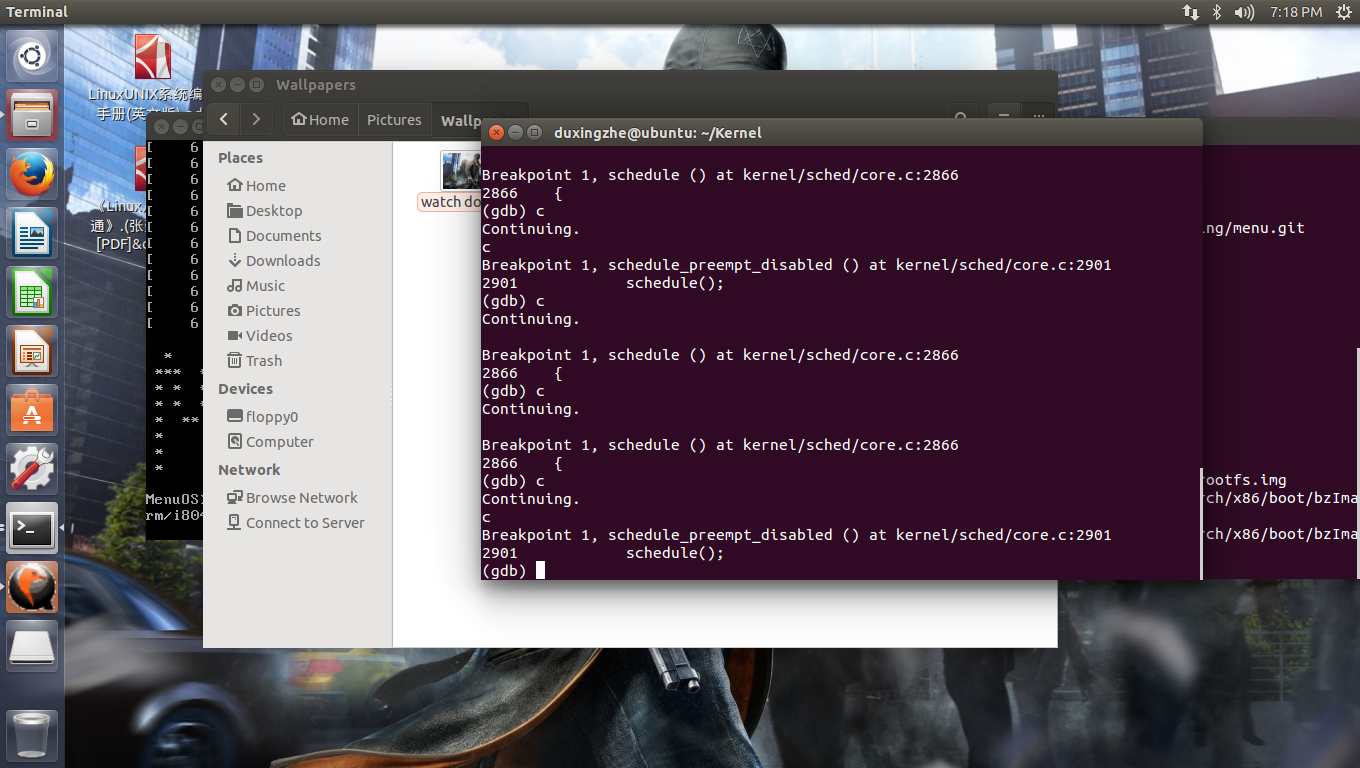
这一次不用任何的调用,因为我们看到当我们设置schedule的断点后,会有以三次中断为一次循环的现象,并且由此发现一个新的函数:schedule_preempt_disabled。这说明,即使我们对系统什么也动,其内部也在不停地进行调度。很有可能是0号进程和init进程进行调度,而schedule_prreempt_disabled则没有资料可以分析。
第三章 分析
core.c中的schedule函数:
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable();
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch(cpu);
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev) || rq->skip_clock_update < 0)
update_rq_clock(rq);
next = pick_next_task(rq, prev);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->skip_clock_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
context_switch(rq, prev, next); /* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
raw_spin_unlock_irq(&rq->lock);
post_schedule(rq);
sched_preempt_enable_no_resched();
if (need_resched())
goto need_resched;
}linux调度的核心函数为schedule,schedule函数封装了内核调度的框架。细节实现上调用具体的调度类中的函数实现。schedule函数主要流程为:
1,将当前进程从相应的运行队列中删除;
2,计算和更新调度实体和进程的相关调度信息;
3,将当前进重新插入到调度运行队列中,对于CFS调度,根据具体的运行时间进行插入而对于实时调度插入到对应优先级队列的队尾;
4,从运行队列中选择运行的下一个进程;
5,进程调度信息和上下文切换;
当进程上下文切换后,调度就基本上完成了,当前运行的进程就是切换过来的进程了。
参考资料:http://blog.csdn.net/bullbat/article/details/7163910
switch_to.h
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)这里的输出部分有三个参数,表示这段程序执行后有三项数据会有改变。其中[prev_sp]、[prev_ip] 都在内存中分别为prev->thread.sp、prev->thread.ip,而最后一个参数则与寄存器EAX结合,对应于参数中的last。而输入部则有4个参数,其中[next_sp]、[next_ip]在内存中,分别为next->thread.sp 与next->thread.ip,剩余的两个参数则与寄存器EAX,EDX结合,分别对应prev,next。
先看开头有两条push指令和结尾处有两条pop指令,再看14行将当前的esp,也就是当前进程的prev的内核态的堆栈指针存入prev->thread.sp,第15行又将新收到调度要进入运行的进程next的内核态的堆栈竞争next->thread.sp置入esp。这样一来,CPU在第15行与第16行这两条指令之间就已经切换了堆栈。假定我们有A,B两个进程,在本次切换中prev指向A,而next指向B。也就是说,在本次切换中A为要“调离”的进程,而B为要“切入”的进程。那么,在这里的第12到15行是在使用A的堆栈,而从第16行开始就是在用B的堆栈了。换言之,从第16行开始,“当前进程”,已经是B而不是A了。在内核代码中当需要访问当前进程的task_struct结构时使用的指针current时实际上是宏定义,它根据当前的堆栈指针的ESP计算出所需的地址。如果第16行处引用current的话,那就是已经指向B的task_struct结构了。所以进程切换其实在第15行指令执行完就已经完成了。但是,构成一个进程的另一个要素是程序的执行,所以还要进行其他步骤。由于12,13行事push进A的堆栈,而在 21行至22行从B的堆栈中POP出来,本质就是恢复新切入的进程在上一次被调离时的push进堆栈的内容。理论上了,进程的切换过程中,多个进程都已经在执行了只是暂时的撤离cpu,所以切换过程就是在堆栈之间进程切换。
那么如何完成程序执行的切换,看一下之后的16行至20行。第16行的[prev_ip]所在位置,实际上就是将第21行的pop指令所在的地址保持在prev->thread.ip中,作为进程A下一次被调度运行而切入时的“返回”地址。然后,又将next->thread.ip压入堆栈。所以,这里的next->thread.ip正是进程B上一次被调离时在第16行中保存的。它也指向这里的[prev_ip],即21行的pop指令。接着,在19行通过jmp命令,而不是call命令,转入了一个函数__switch_to()。暂时不讨论__switch_to(),当CPU执行到哪里的iret指令时,由于是通过jmp指令转过去的,最后进入对战的next->thread.ip就变成了返回地址,而这就是[prev_ip]所在的地址,也就是21行的pop指令所在的地址。由于每个进程在被调离时都要执行这里的第16行,这就决定了每个进程在收到调度恢复运行时都是从这里的第21行开始。
上面都是已有进程的切换。但新创建的进程会是怎么样切换的。新创建的进程并没有在“上一次调离时”执行过这里的第12至16行,所以要将其task_struct结构中的thread.ip事先设置好,并且设置“返回地址”时不一定是[prev_ip]所在的地址,这里取决于内核态堆栈的设置。
参考资料:http://www.cnblogs.com/akira90/p/3157896.html
结合上面的分析:
首先schedule要选择适当的进程调度算法,或为完全公平算法还是实时调度算法。这个是由switch_to.h所规定的宏来决定。并且,我们要注意的是:为了能有效地进行进程切换,switch_to使用了堆栈的方式来处理,这个让我想起了Android管理Activity的方法,他也是通过堆栈的方式来调度系统应用活动的。
参考资料:http://blog.csdn.net/bullbat/article/details/7160246
第四章 总结
这样我们就分析完了Linux内核的调度。在这里,我们看到Linux使用了堆栈进行了进程调度。而在我阅读的文献中(http://blog.csdn.net/bullbat/article/details/7160246),Linux使用了CFS,也就是完全公平算法和实时调度算法。他们运用的数据结构为:红黑树(也就是一种树的数据结构)和队列。在以前的操作系统中,是没有很多的任务,所以没有系统调度一说。而到了多用户多系统的时代,进程调度算法便决定着操作系统性能的好坏。在最后一期视频中,举了一个例子,由于键盘的输入,产生了一个系统中断,然后陷入了内核态。接着由于有键盘输入,于是把内核态进行激活,然后进行进程管理,将某一个进程的优先级提高,从而让进程运行。接着返回用户态堆栈。
在分析的最后,在此回想myKernel中系统进程的切换,那就是一个简单的进程调度。通过一个链表,对四个进程进行了循环调度。当时实在无法理解,也写得不是很好,在现在看来,才有所理解。
就如switch_to中的方法,通过压栈出栈交换prev_ip和next_ip。然后返回,从而完成进程调度。而用哪个作为下来的进程,则通过优先级的算法和进程调度算法来决定。
附录
卢晅 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









