







一、干啥用的?
一个新的预训练语言模型(UNILM),它可以用于自然语言理解NLU和生成任务NLG。
UNILM由多个语言建模目标共同预训练,共享相同的参数。
二、和别的pre-train模型有啥区别?
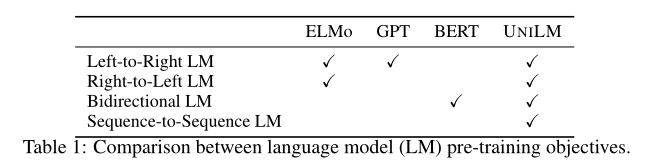
UNILM是一个多层Transformer网络,使用三种类型的语言建模任务进行预训练:单向(包括l-to-r 和r-to-l)、双向和seq2seq预测。该模型在大量文本上联合预训练,针对三种类型的无监督语言建模目标进行优化。
三、怎么做的?
与BERT类似,可以对预先训练的UNILM进行微调(如有必要,还可以添加特定于任务的层),以适应各种下游任务。
但与主要用于NLU任务的BERT不同的是,UNILM可以通过配置的方式来使用不同的自注意力的mask机制,为不同类型的语言模型聚合上下文,从而既可以被用在自然语言理解任务上,又可以被用在自然语言生成任务上.

通过图示很容易明白,对于不同的语言模型,设置不同的mas
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









