






python分布式训练DDP
基本结构
- 导入分布式框架
import torch.distributed as dist
import torch.utils.data.distributed
- 初始化
dist.init_process_group(backend=‘nccl’, init_method=‘env://’)
- 分布式训练包装数据侧
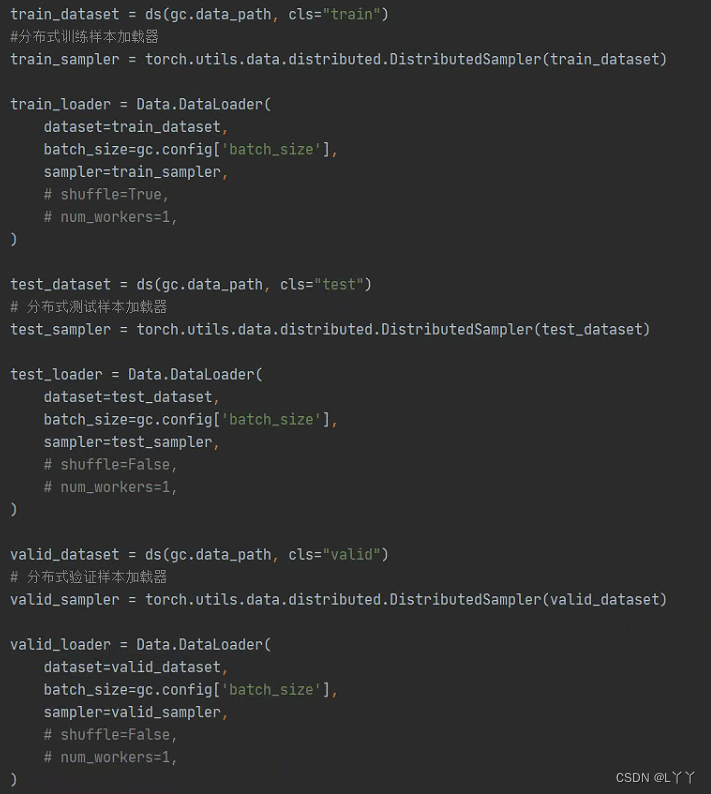
- 分布式训练 根据local_rank配置当前进程使用的GPU
device = torch.device(‘cuda’, gc.config[‘local_rank’])
其中,local_rank为当前训练节点,该参数需在argparse()中进行定义,但具体的值由pytorch自动设置,具体如下:
parser.add_argument(“–local_rank”, type=int, default=0, required=True, help=‘local rank for DistributedDataParallel’)
- 分布式训练包装模型侧
net = net.to(device)
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[gc.config[‘local_rank’]])
if isinstance(net, torch.nn.parallel.DistributedDataParallel):
net = net.module
需要注意的是此处device_ids必须是list类型,加一个[],否则要报错“Error : int object is not iterable”
此外,在使用DDP后,模型的参数形式变为model.module
- 运行代码
CUDA_VISIBLE_DEVICES=0,1 python3 -m torch.distributed.launch --nproc_per_node=2 --master_port 29501 main.py
产生的错误
Error: “int object is not iterable”
解决方法:将device_ids设为list
Error: “unrecognized arguments: --local_rank=1 - distributed”
解决方法:parser.add_argument(“–local_rank”, type=int, default=0, required=True, help=‘local rank for DistributedDataParallel’)
官方表示,该参数必须设置,但具体的值由pytorch在运行过程中进行赋值。
Error: "subprocess.CalledProcessError: Command ‘[’/usr/bin/python3’, ‘-u’, ‘main.py’, ‘–local_rank=1’]’ "
问题原因:在这个错误是由于训练参数分布存在错误,某些参数没有参与训练导致。
解决方法:把之前的问题解决即可。
参考文章
http://zhuanlan.zhihu.com/p/76638962
http://zhuanlan.zhihu.com/p/113694038















 3168
3168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









