







Abstract
当应用有损视频压缩算法时,压缩伪影经常出现在视频中,使解码视频对人类视觉系统不愉快。在本文中,我们将视频伪影减少任务建模为卡尔曼滤波过程,并通过深度卡尔曼滤波网络恢复解码帧。与现有的使用噪声先前解码帧作为恢复问题中的时间信息的工作不同,我们利用噪声较小的先前恢复帧,建立了基于卡尔曼模型的递归滤波方案。该策略可以提供更准确和一致的时间信息,从而产生更高质量的恢复结果。此外,还利用预测残差的强先验信息,通过设计良好的神经网络进行恢复。这两个分量在卡尔曼框架下组合,并通过深度卡尔曼滤波网络进行优化。通过集成卡尔曼模型的递归性质和深度神经网络的高度非线性转换能力,我们的方法可以很好地弥合基于模型的方法和基于学习的方法之间的差距。在基准数据集上的实验结果证明了该方法的有效性。
1 Introduction
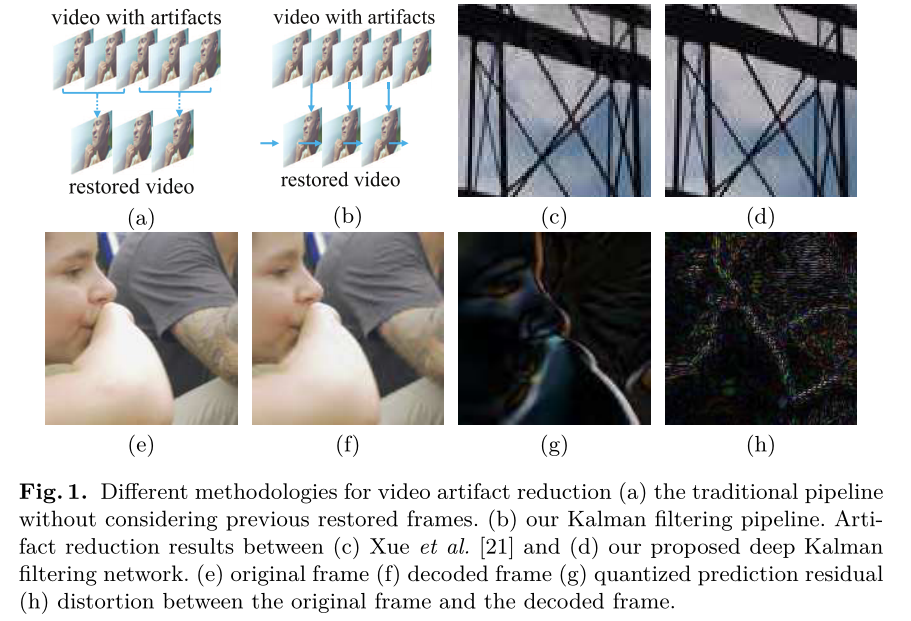
压缩伪影减少方法旨在从有损解码图像中生成无伪影图像。为了在互联网上存储和传输大量图像和视频,广泛使用图像和视频压缩算法(例如JPEG、H.264)[1-3]。然而,这些算法通常会引入不需要的压缩伪影,例如阻塞、模糊和振铃伪影。因此,减少压缩伪影引起了越来越多的关注,在过去几十年中,人们开发了许多方法。
早期工作使用手动设计的滤波器[4,5]和稀疏编码方法[6-9]来消除压缩伪影。最近,基于卷积神经网络(CNN)的方法已成功应用于许多计算机视觉任务[10-20],例如超分辨率[15,16]、去噪[17]和伪影减少[18-20]。特别是,Dong等人[18]首先提出了一种四层神经网络来消除JPEG压缩伪影。
对于视频伪影减少任务,我们的动机是双重的。首先,当前帧的恢复过程可以受益于先前恢复的帧。一个原因是,与解码帧相比,先前恢复的帧可以提供更准确的信息。因此,来自相邻帧的时间信息(例如运动线索)更精确和鲁棒,并且可以提供进一步提高性能的潜力。此外,先前恢复帧的依赖性自然会导致用于减少视频伪影的递归管道。因此,它通过潜在地利用所有过去恢复的帧递归地恢复当前帧,这意味着我们可以利用从先前估计传播的有效信息。目前,大多数用于减少压缩伪影的最先进深度学习方法仅限于去除单个图像中的伪影[16-19]。尽管视频伪影减少方法[21]或视频超分辨率方法[22-24]尝试结合恢复任务的时间信息,但其方法忽略先前恢复的帧,并分别恢复每个帧,如图1(a)所示。因此,可以通过使用适当的动态滤波方案来进一步提高视频伪影减少性能。
其次,现代视频压缩算法可能包含强大的先验信息,可用于恢复解码帧。由于根据信息理论[9],实际视频压缩标准不是最优的,因此产生的压缩码流仍然存在冗余。至少在理论上,可以通过利用隐藏在代码流中的知识来改善恢复结果。对于视频压缩算法,帧间预测是用于减少时间冗余的基本技术。因此,解码帧由两部分组成:预测帧和量化预测残差。如图1(g)-(h)所示,原始帧和解码帧之间的失真与量化预测残差具有很强的关系,即,具有高失真的区域通常对应于高量化预测残差值。因此,可以通过使用该任务特定的先验信息来增强恢复。
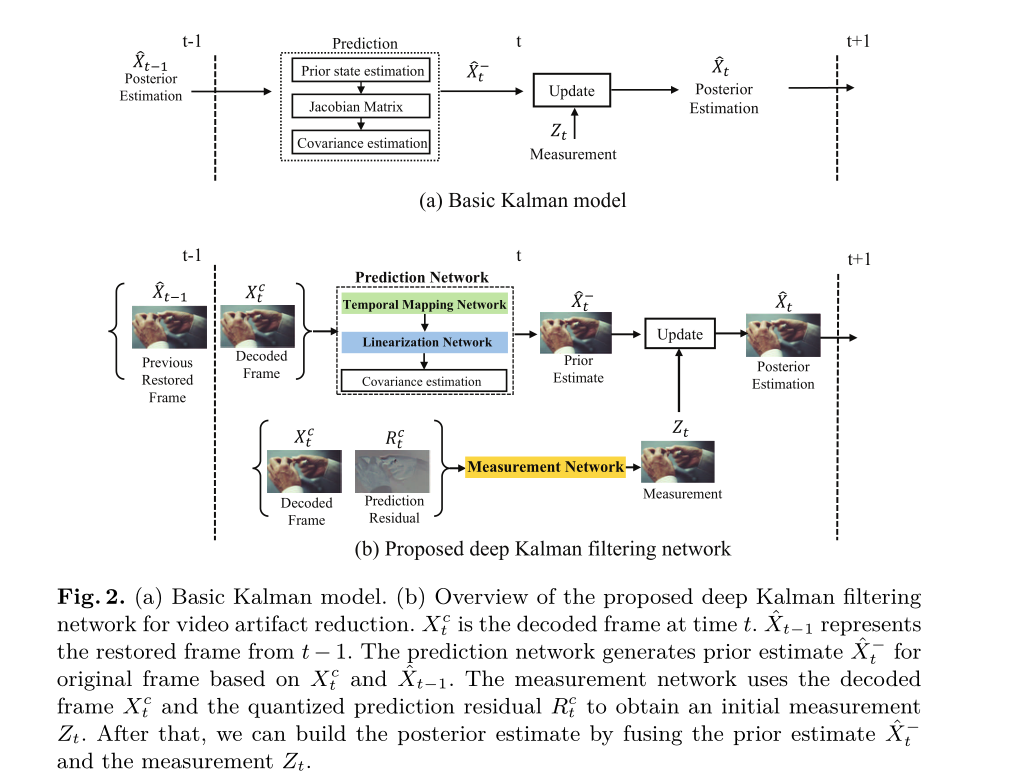
在本文中,我们提出了一种用于减少视频伪影的深度卡尔曼滤波网络(DKFN)。该方法可以作为后处理技术,因此可以应用于不同的压缩算法。具体来说,我们将视频伪影减少问题建模为卡尔曼滤波过程,该过程可以递归恢复解码帧并捕获从先前恢复帧传播的信息。为了对解码帧执行卡尔曼滤波,我们构建了两个深度卷积神经网络:预测网络和测量网络。预测网络旨在基于先前恢复的帧获得先验估计。同时,我们研究了编码算法中的量化预测残差,并提出了一种结合这种强先验信息的新测量网络,用于鲁棒测量。然后,在卡尔曼框架下融合先验估计和测量,得到恢复后的帧。我们提出的方法通过集成卡尔曼模型的递归性质和神经网络的高度非线性转换能力,弥合了基于模型的方法和基于学习的方法之间的差距。因此,我们的方法可以从一系列解码的视频帧中恢复高质量的帧。据我们所知,我们是第一个在卡尔曼滤波框架下开发新的深度卷积神经网络来减少视频伪影的人。
总之,这项工作的主要贡献有两个方面。首先,我们将视频伪影减少问题表述为卡尔曼滤波过程,该过程可以递归地恢复解码帧。在此过程中,我们利用CNN预测和更新卡尔曼滤波的状态。其次,我们利用量化预测残差作为强先验信息,通过深度神经网络减少视频伪影。实验结果表明,我们提出的方法在减少视频压缩伪影方面优于最先进的方法。
2 Related Work
......
3 Methodology
我们首先简要介绍了基本卡尔曼滤波器,然后描述了我们的视频伪影减少公式和相应的网络设计
Introduction of Denotations
设V={X | X1,X2,…,Xt−1,Xt,…}表示未压缩的视频序列,其中Xt∈ 是时间步长t处的视频帧,mn表示空间分辨率。为了简化描述,我们只分析具有单个通道的视频帧,尽管我们在实现中考虑了RGB/YUV通道。压缩后,
是
的解码帧。
表示先验估计,
表示从解码帧
恢复
的后验估计。
是视频编码标准(如H.264)中的量化预测残差。
是相应的未量化预测残差.
3.1 Brief Introduction of Kalman Filter

Kalman Filtering
如图2(a)所示,卡尔曼滤波包括预测和更新两个步骤。
......
没有找到这篇论文的源码,不耐心看有点不太好理解,实验效果不错,想了解的可以深入去看看。
















 1835
1835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









