







Deep learning-based compressed image artifacts reduction based onmulti-scale image fusion
(基于多尺度图像融合的基于深度学习的压缩图像伪影减少)
在基于块的图像/视频压缩平台中,视觉上明显的压缩伪像之一称为blocking artifact(阻塞伪像)。本文提出了一种基于多尺度图像融合的深层网络来消除图像压缩伪影 (通常用image deblocking表示)。最近基于深度学习的相关方法通常基于显式图像先验以每像素方式使用损失函数来学习深度模型,以便直接产生干净的图像。在提出的深度框架中,首先对输入图像进行下采样,同时自然减少了blocking artifact。然后,我们的多尺度图像融合模型用于将不同的down-scaled版本 (较少的伪像) 与输入图像 (具有较严重的伪像) 融合,以估计阻塞伪像。通过从输入图像中扣除估计的伪像,可以显着消除阻塞伪像,并同时保留大多数原始图像细节。
介绍
基于软件/硬件实现的简单性和规律性的好处,基于块的图像编码已在图像压缩中流行,用于表示或存储图像和视频数据。为了实现图像浓缩—> 图像通常被分解成许多 (非重叠的) 平方块,然后通过应用变换 (例如,离散余弦变换形式或DCT) 和量化操作来处理每个单独的块。依靠该方法,在不同的多媒体通信应用中提出了一些图像或视频压缩范例,例如JPEG、mpeg-x和H.26X。图像压缩的主要目的是通过有效地表示大量的视觉数据并保留一定质量的恢复媒体数据来适应存储限制或信道带宽限制。对于低比特率压缩,依赖于基于块的DCT的技术通常会在恢复的图像或视频数据中引起视觉上令人不快的伪像,通常由阻塞伪像表示。伪像可以通过相邻块边界附近的像素值的可见变化来解释 。我们的主要目的是开发一个深层框架,用于消除块伪影,并为基于块的压缩图像实现可接受的视觉质量,特别是对于低比特率的应用。
已经提出学到方法用以消除伪影,一种最实用的方法是后处理,它适合通过进一步恢复解码的图像而嵌入到任何现有的压缩平台中。用于减少图像块伪影的后处理方法分为两类:增强方法和恢复方法。
Enhancement-based approaches for image deblocking
基于图像增强的方法主要是根据人类感知的特定伪影结构和视觉敏感性来提高感知图像的视觉质量。传统上,沿块边界进行后过滤是为了消除块伪像。图像增强方法通常旨在平滑可见的伪影,以代替致力于恢复像素的原始值。基于以下事实,它可能是稍微启发式的: 在客观标准下不执行任何优化。这种方法的主要好处是计算复杂度较低。
具体来说,有一种经典的解块方法 (由SA-DCT表示),该方法依赖于形状自适应变换滤波。此外,提出了沿块边界执行阻塞伪影的检测。设计了四种模式的滤波器,以通过分析频率区域的活动来消除不同频率范围内的阻塞伪影。此外,在H.264 (或AVC) 中使用的环内滤波器应用了简单的操作来检查沿块边界的伪像,并消除它们执行拾取的滤波操作。此外,HEVC中使用的两个环内滤波器是SAO (采样自适应偏移) 滤波器和去块滤波器。用于解块的过滤器减轻了转换后的块边界处的不连续性。此外,提出了一种基于FPGA设计的双边滤波器,用于实时图像去噪。最近,提出了一种基于小波变换的跟踪边缘角的方法,用于消除解压缩图像的阻塞伪影。
Restoration-based approaches for image deblocking
对于图像恢复方法 ,基于感知的图像数据和图像的先验知识,将消除压缩伪影视为信号恢复问题。一个经典的例子是POCS (projection onto convex sets) 技术 。POCS定义了一个封闭的凸集 (包括几个约束),其中项目与从原始图像得出的图像先验知识一致。此外,为了消除解压缩图像中的图像阻塞伪影,提出了一组依赖于POCS的图像量化约束。
另一方面,一些图像恢复方法倾向于优化最优性标准,这些标准受从图像先验获得的一些约束 (例如,稀疏先验) 的限制。例如,提出了基于JPEG图像的稀疏表示的解块框架。它训练了一个字典,用于依靠训练集稀疏地表示图像。然后,将训练好的字典应用于稀疏表示图像,以消除具有错误阈值约束的图像的阻塞伪像。在 先前的论文中,我们已将图像解块表述为基于自学习的稀疏信号分解问题,而无需有关所采用的压缩算法的任何先验知识。
随着深度学习的发展,认为基于深度学习的方法 在图像去块方面通常显著优于大多数传统方法,基于以下描述的可能原因。首先,使用深度网络体系结构,深度学习将有效地扩展灵活性和有效利用图像特征的能力。其次,受益于几个先进的规范和学习算法,训练过程将加快,性能也将得到提高。第三,深度学习非常适合在最近功能强大的GPU (图形处理单元) 计算系统上进行并行处理 ,以提高运行时性能。
贡献和新颖性
1)提出一个新颖的多尺度深度模型,通过缩小感知图像自然消除了阻塞伪影,然后应用提出的多尺度图像融合模型融合不同的缩小版本和原始输入来估计阻塞事实。
2)在统一的深度融合框架中共同学习多任务 (图像超分辨率和区块伪影估计)。
3)在我们的深度网络中集成残差学习和多个损失函数,其中损失函数被施加到网络的多个层 (不仅在输出层) 中,以实现更好,更快的收敛和优化性能。
4)在我们的深度融合网络中,利用多个损失函数类型,包括 (或MSE,即均方误差) 和SSIM (结构相似性)损失,以实现更好的解块性能。
值得注意的是,我们对具有可见阻挡伪影的感知图像的下采样和超分辨版本进行评估的主要动机是两个。首先,对具有可见阻塞伪影的图像进行下采样自然会在一定程度上减少阻塞伪影。应用超分辨率 (SR) CNN模块无法恢复通过下采样消除的大多数阻塞伪影。这将有利于图像去块的目的。具有阻塞伪影的图像自降尺度的想法是受我们先前基于稀疏学习的研究工作的启发,该研究工作用于图像SR和去块中的联合学习。已证明对于图像SR和去块是可行的。其次,融合输入图像 (具有阻塞伪影) 及其超解析版本 (从具有阻塞伪影减少的下采样版本) 将有利于两者中残差网络的学习。
相关工作
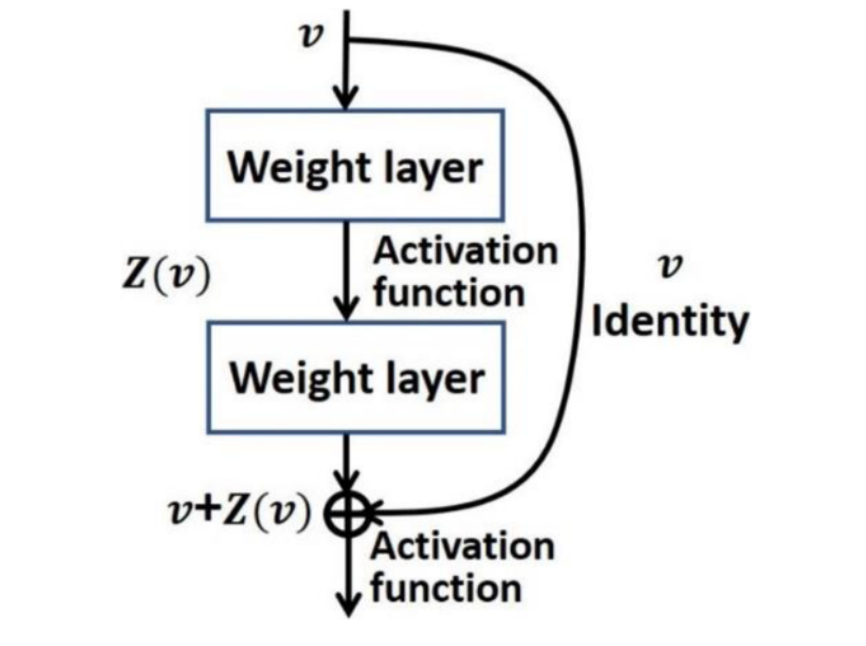
残差网络图
Loss functions for optimization of deep models
在深度网络中,损耗层计算网络输出和地面真相之间的差 (例如,在多个视觉应用中生成的和参考图像块/补丁之间的比较)。因此,损失函数将有效地驱动网络学习以产生所需的输出。损失函数的最流行的选择是MSE (均方误差) 或2范数函数,因为它在几个优化应用中的简单性和平滑性。处理后的图像补丁 α 和地面真相 β (大小相同) 的L2损失函数表示为:
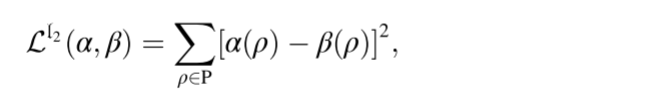
(其中Pand ρ 分别表示补丁的像素集和第 ρ 个像素的索引)
ℓ 2损失函数可能会受到一些限制。例如,ℓ 2与人类观察者感知的图像质量弱相关。主要原因包括,由于噪声的影响独立于图像的局部特性。然而,人类视觉系统对噪声的敏感性通常依赖于图像局部特性 (例如,对比度、结构和亮度)。因此,应考虑更多类型的损失函数来满足本文的目的,以恢复JPEG压缩伪影所遭受的图像质量。为了产生视觉上令人愉悦的输出图像,广泛使用的损失函数是SSIM (结构相似性,一种众所周知的基于感知的模型,用于估计感知的图像质量) [37]。SSIM指数可以在两个大小相同的图像补丁 α 和 β 之间计算:

L1也被考虑其中,由于平方差的原因,对于训练集中可能包含的异常值,则将产生L2损失函数的影响,从而导致更大的误差。
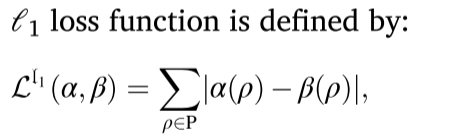
Proposed deep image fusion model for blocking artifacts reduction
提出的模型图如下:

该模型由两个超分辨率 (SR) CNN和一个伪像估计 (用AE表示) CNN模块组成,以实现基于块变换 (例如JPEG) 压缩图像的块伪像的去除。
图像的阻塞伪影主要是由基于块的图像压缩系统 (例如JPEG) 引起的。当将变换编码 (例如,DCT) 应用于有损压缩的图像块时,每个块的变形系数被量化。虽然每个块被单独量化,并且相邻块被不同地量化,但显著的视觉不连续性将出现在块边界处,尤其是在低比特率压缩 (使用较粗的量化) 时。
为了消除解码图像的阻塞伪影 (使用JPEG压缩) 以获得良好的视觉体验,本文将其表述为学习感知图像的阻塞伪影 (或输入图像与其未压缩的干净版本之间的残差) 的残差学习问题,并提出了一种新颖的深层模型来解决该问题。通过考虑具有可见块伪影 ε 的解码压缩图像I,使得I = IO+ε,其中IO表示I的原始未压缩版本。我们的目标是学习伪像 ε,并通过从I中删除 ε 来大致恢复原始图像IO (由Ideblocked表示)。
Proposed multi-scale image fusion model based on deep learning
我们的多尺度图像融合模型的主要目的是估计输入图像I中的阻塞伪影 (具有可见的阻塞伪影)。
Proposed super-resolution CNN module in proposed multi-scale deep image fusion model
为了融合输入图像I的两个不同的缩小版本 (Id_1和Id_2),我们建议首先提高较低分辨率图像 (Id_2) 的分辨率。为了有效地增强尺寸 (W/4) × (H/4) × c的缩小图像Id_2,我们通过CNN提出了一种新颖的单图像SR (超分辨率) 技术。传统的基于深度学习的SR架构 通常首先将输入LR (低分辨率) 图像放大到所需的大小,然后再将其输入到学习的CNN中 (以增强分辨率),这使得SR运算可以在HR (高分辨率) 空间中形成,计算成本更高。取而代之的是,我们借用的想法来设计一种轻巧的CNN,该CNN直接选择LR图像作为输入并生成其HR版本。此外,为了获得更好的SR性能,我们集成了residual学习,快捷连接和子像素CNN技术,以形成我们的SR CNN架构。
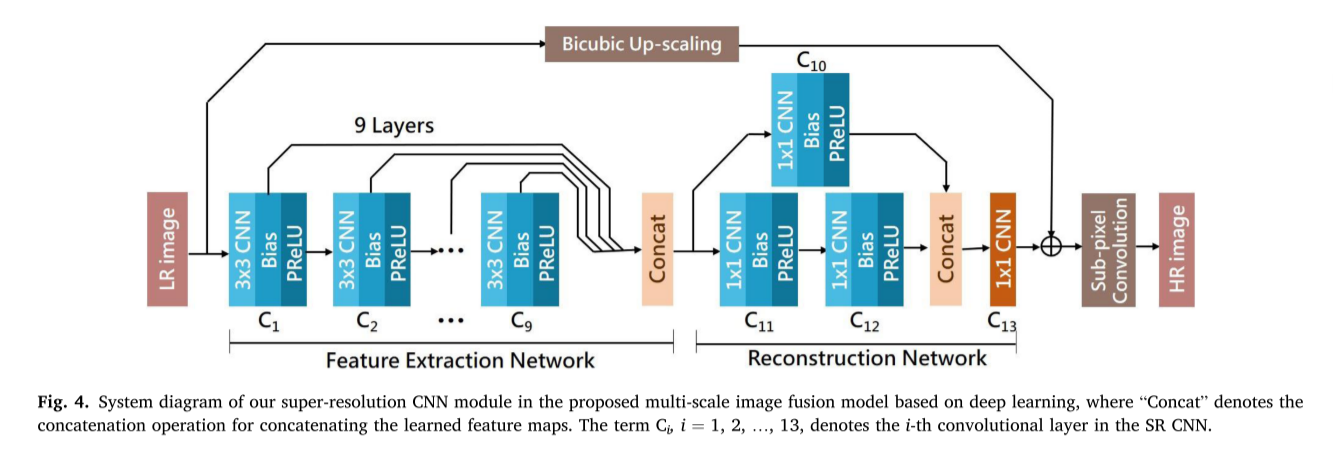
们的SR CNN模块中的特征提取网络由9层的级联组成,其中每个层由具有3 × 3的滤波器大小和偏置的CNN形成,以及一个PReLU (参数ReLU) 单元 (用于非线性)。PReLU是ReLU的推广,它可调节地训练整流器的参数,并在不显著的额外计算负载下提高精度 。每个层输出都传递到下一层,以减少由以下层操作产生的特征,因为对于SR应用程序而言,本地特征比全局特征更为关键。此外,为了很好地导出本地和全局特征,所有层输出都通过快捷连接技术 (用于保存特征图) 连接,以形成重建网络的输入。
在重建网络中,我们利用1 × 1 cnn来减小由特征提取网络的特征图级联引起的输入尺寸 (通道数),重建网络由两条具有1 × 1卷积运算的平行路径组成。两条路径的输出被串接,然后由另一个1 × 1卷积层来实现网络的输出。通常,使用1 × 1 cnn的主要优点包括减少前一层的尺寸/通道,以及增加网络表示的非线性。更具体地说,重建网络由两条平行路径组成,其中一条由2层1 × 1 CNN,bias和PReLU单元级联形成,另一条仅由一层形成,也由1 × 1 CNN,bias和PReLU组成。然后将两条并行路径的输出连接起来,将其馈送到1 × 1 CNN层中,以获得重建网络输出。
我们的SR方法会不断将集成反馈到下一层 (子像素卷积层) 中,以进一步产生SR结果。为了使尺寸为w × h × c (c表示颜色通道的数量) 的输入图像在区域和垂直方向上增加空间分辨率,以获得尺寸的放大版本 (rw × rh × c),我们的重建网络将为每个输出大小为w × h × c的r2通道。输出通道被馈送到子像素卷积层中,以重建最终的SR图像。
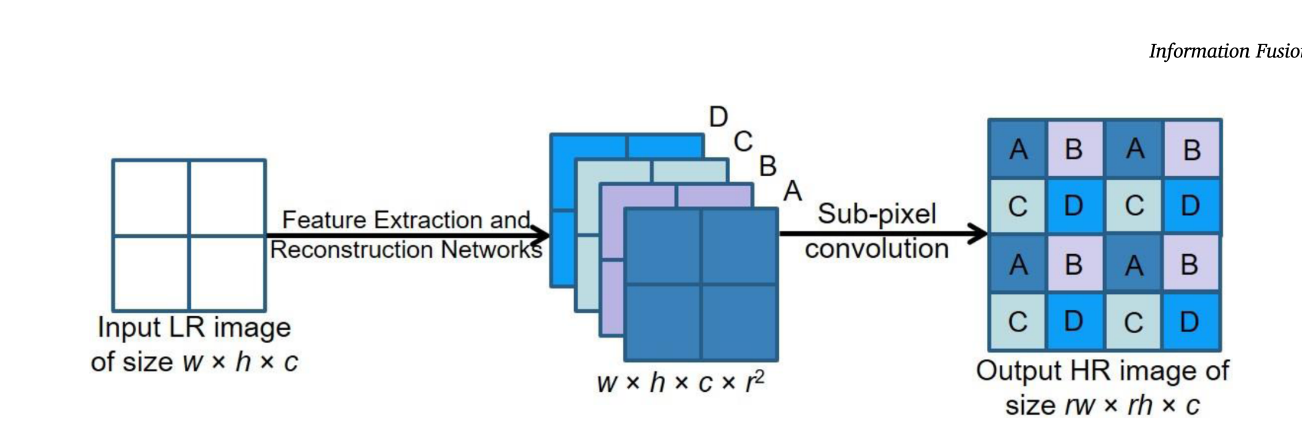
通过学习一个放大滤波器阵列来实现子像素卷积层,以将来自重建网络的输出特征图放大到最终的HR输出。关键思想是实现一个周期洗牌算子,用于将尺寸为r2 × w × h × c的张量的元素向后扩展到尺寸为rw × rh × c的形状的张量,如下图所示 (在这个例子中r = 2):

Artifacts estimation convolutional neural network module in proposed multi-scale image fusion model
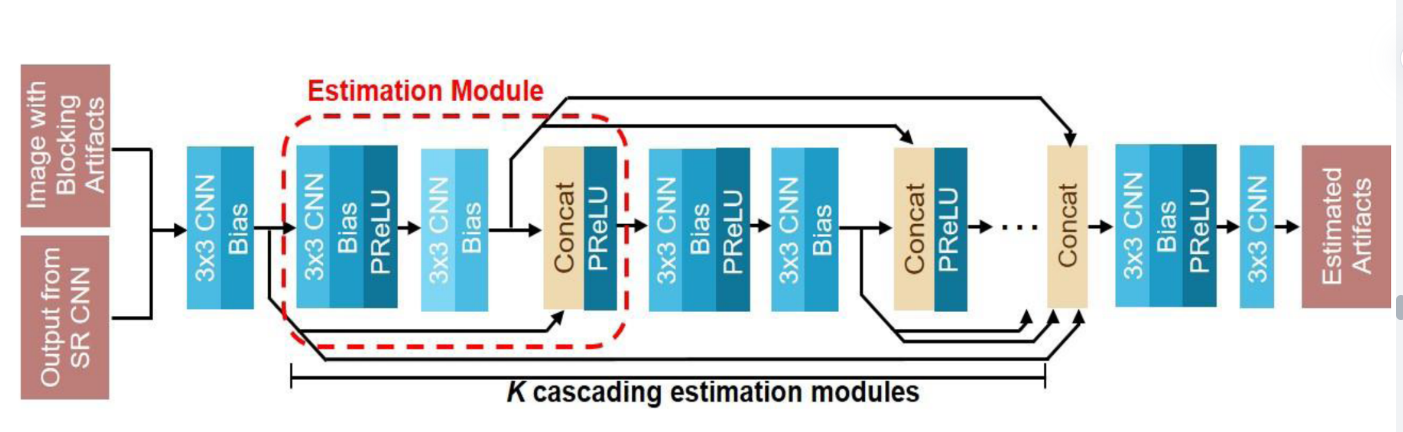
我们的AE CNN的主要目标是基于两个输入来估计解码压缩图像的阻塞伪影: 1) 具有阻塞伪影的原始图像 (I);2)它的 “roughly” deblocked version通过第一次按比例缩小I获得(用于自然减少阻塞伪影),并放大它 (由我们的SR CNN与图像融合)。我们在我们的AE CNN中设计了一个用于特征提取的估计模块。估计模块 (由图6中的红色虚线圈出的范围表示) 是根据快捷方式连接结设计的,由几个3 × 3的CNN、bias、PReLU单元和一个串联单元 (用Concat表示) 组成。在串联了K个级联估计模块的中间输出图之后,接着是下面的两个CNN层,可以获得输入的估计的阻塞伪影 (输入和输出图像之间的残差),参数K根据经验设置为7,以在去块性能和计算复杂度之间进行折衷。















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









