 商业文本分析四大技术解析
商业文本分析四大技术解析







第一部分:概念解释
1. 词频分析
-
解释:这是最基础、最直观的文本分析方法。它通过统计文本中各个词汇出现的次数,来识别文档集合中的核心话题和关键信息。高频词汇通常代表了文本的核心内容。
-
商业应用:快速了解客户评论、社交媒体讨论或行业报告中的焦点。例如,分析产品评论时,“价格”、“质量”、“物流”、“客服”等词高频出现,说明这些是消费者最关心的维度。
-
局限:仅关注频率,无法理解词汇的上下文关系、情感色彩和深层语义。
2. 情感分析
-
解释:情感分析旨在判断一段文本所表达的主观情感倾向(正面、负面、中性),有时还会细分到情绪(如喜悦、愤怒、失望等)。它回答了“人们对此事感受如何?”的问题。
-
商业应用:
-
品牌声誉管理:监测社交媒体上对品牌的情感变化。
-
产品反馈分析:量化用户对新产品特性的好评和差评比例。
-
市场活动评估:衡量一次营销活动在公众中引发的情感反响。
-
-
局限:难以处理反讽、隐喻等复杂语言现象,且对领域特定词汇的敏感性高(例如,“杀毒软件”中的“杀”是中性词)。
3. 社会语义网络分析
-
解释:这种方法将文本中的“概念”视为网络中的“节点”,将概念之间的共现关系(如在同一句子、段落或文档中出现)视为“连接”。通过分析网络的整体结构(如中心性、社群划分),可以揭示概念之间的关联模式和组织结构。
-
商业应用:
-
品牌形象分析:看核心品牌词周围关联的是哪些正面或负面词汇。
-
竞争对手定位:对比自己与竞争对手的语义网络,看其在消费者心智中与哪些概念(如“创新”、“廉价”、“可靠”)强关联。
-
发现潜在需求:发现某些未被满足的需求(如“便携”和“电池”经常共现但评价负面)可能指向产品改进方向。
-
-
局限:构建网络依赖于共现窗口的定义,结果解释需要一定的网络分析知识。
4. LDA主题模型
-
解释:LDA是一种无监督的机器学习方法,用于从大量文档集合中自动发现潜在的“主题”。它将每个文档视为多个主题的混合,而每个主题又是一组词汇的概率分布。它回答了“这批文档主要讨论了哪些隐藏的、抽象的主题?”。
-
商业应用:
-
海量数据探索:从成千上万的用户反馈中自动归纳出几个核心讨论主题(如“价格问题”、“设计缺陷”、“售后服务”等),无需人工预先设定。
-
市场细分:根据消费者讨论内容的不同主题偏好,进行动态的市场细分。
-
趋势追踪:分析不同时间段文档的主题分布变化,追踪公众关注点的演变。
-
-
局限:需要确定主题数量K,结果需要人工解读主题含义,模型训练计算量较大。
第二部分:整合框架体系
这四种方法并非孤立,而是可以形成一个从浅入深、从宏观到微观的递进式分析框架。下图清晰地展示了这一框架的工作流程:
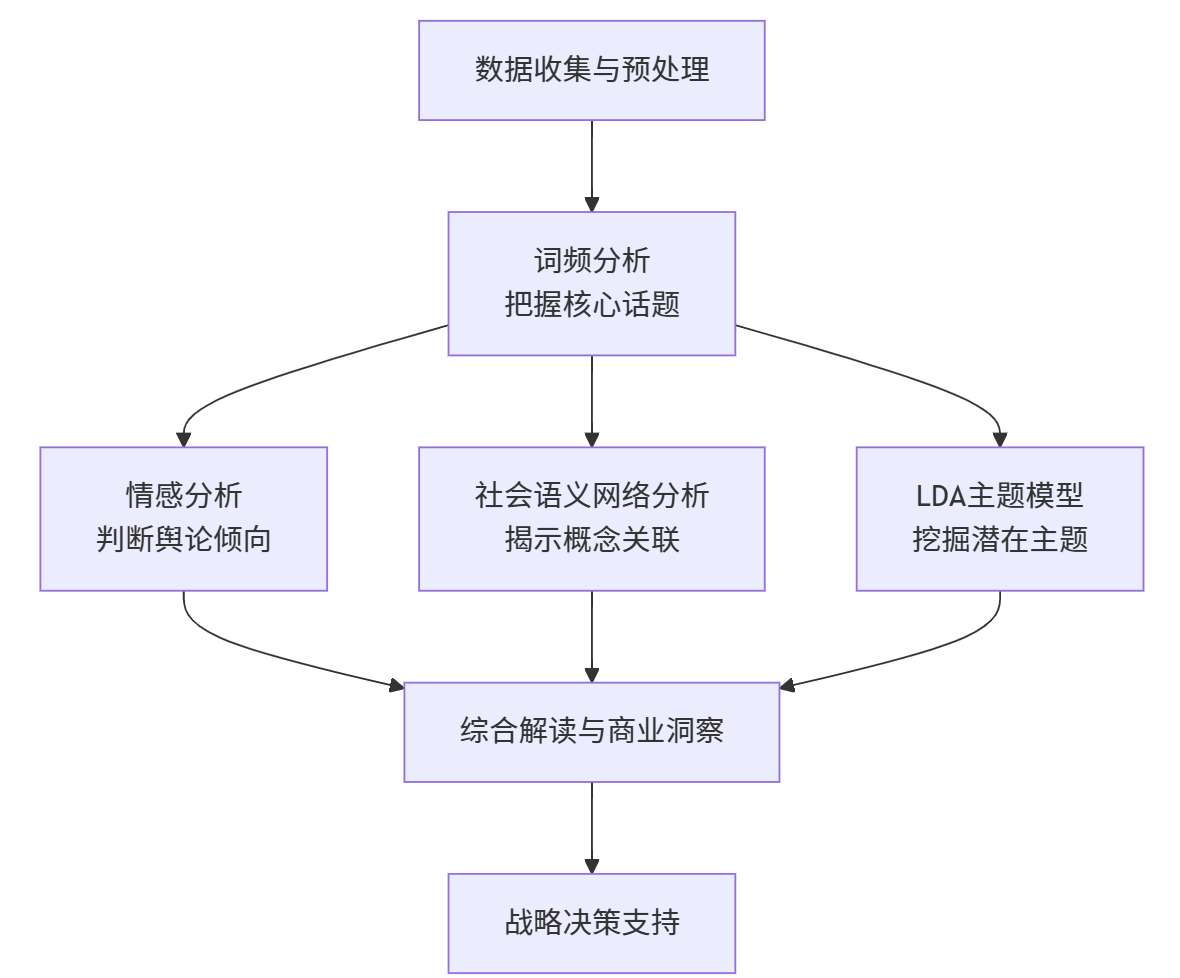
阶段一:数据基础层
-
目标:获取干净、规整的文本数据。
-
活动:
-
数据收集:从社交媒体、电商平台、客服系统、行业报告、新闻等渠道爬取或导出文本数据。
-
数据预处理:
-
清洗:去除广告、特殊符号、无关信息。
-
分词:将句子拆分成独立的词汇单元。
-
去停用词:移除“的”、“是”、“在”等无实义的常见词。
-
标准化:包括词形还原(如将“running”还原为“run”)和 stemming(词干提取)。
-
-
阶段二:描述性分析层
-
核心方法:词频分析
-
目标:快速掌握文本数据的宏观概况。
-
活动:
-
生成词云或条形图,展示高频词汇。
-
初步回答:“大家最常讨论的是什么?”
-
-
输出:一份关于“是什么”的初步报告。
阶段三:情感与关系分析层
-
核心方法:情感分析 与 社会语义网络分析
-
目标:深入理解舆论的情感倾向和概念间的内在结构。
-
活动:
-
情感分析:对每条文本或整体语料进行情感打分,进行趋势分析和归因分析(是什么导致了情感波动?)。
-
社会语义网络分析:构建共现网络,使用Gephi等工具进行可视化,识别核心节点和社群结构。
-
-
输出:回答“感受如何?”和“概念之间如何联系?”
阶段四:深层主题挖掘层
-
核心方法:LDA主题模型
-
目标:超越表面词汇,发现数据背后潜在的、抽象的主题集群。
-
活动:
-
确定主题数量K。
-
训练LDA模型,得到每个主题下的关键词分布和每个文档的主题分布。
-
人工为每个主题命名(如“性价比讨论”、“用户体验反馈”)。
-
-
输出:回答“数据背后隐藏了哪些核心议题?”
阶段五:综合洞察与决策支持层
-
目标:整合前四层的结果,形成完整的商业洞察,为决策提供支持。
-
活动:
-
交叉验证:例如,将LDA发现的主题与情感分析结合,分析“哪个主题的负面情绪最严重?”;将主题与语义网络结合,看某个主题下的核心概念在网络中如何关联。
-
形成故事线:
-
“通过词频分析,我们发现用户最关心‘电池’和‘价格’(是什么)。
-
情感分析显示,‘电池’的讨论负面情绪高达60%,而‘价格’的评价相对中性(感受如何)。
-
LDA模型进一步识别出一个‘续航问题’主题,其核心词包括‘电池’、‘耗电’、‘一天’(深层主题)。
-
语义网络显示,‘电池’与‘失望’、‘无法接受’等词紧密相连,且形成了一个独立的负面情感社群(概念关联。”
-
-
提出建议: “结论:产品续航能力是当前引起用户不满的首要问题。建议:技术部门优先优化电池性能,市场部门在下一代产品宣传中应重点强调续航改进。”
-
总结
这个框架体系的价值在于其系统性和互补性。它引导分析师从简单的数据描述出发,逐步深入到情感、关系和主题层面,最终将所有线索编织成一个有说服力的商业叙事。在实际应用中,可以根据具体的研究目标和资源情况,灵活选用其中的一种或几种方法进行组合。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









