








概述
机器学习迁移学习方法使用为一项工作开发的模型作为另一项工作的基础。 由于它们比从头开始构建神经网络模型更快、更便宜,因此预训练模型被广泛用作计算机视觉和自然语言处理中深度学习任务的基础。它们在类似任务上的表现也明显更好。
什么是迁移学习
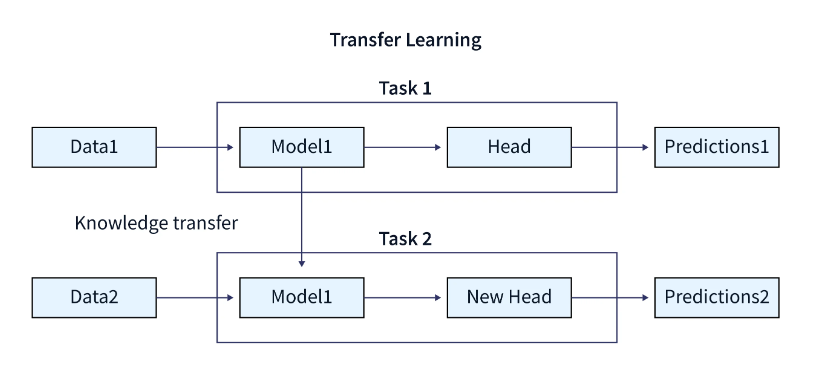
新任务中的预训练深度学习模型称为迁移学习。利用预训练模型的知识(特征、权重等)来训练新模型,可以克服为新任务使用较少数据等问题。
使用这种方法,模型可以实现较高的模型性能率,并且有很大的机会利用最少的计算。迁移学习机器学习的概念在自然语言处理 (NLP) 和图像处理任务中被大量使用,这些任务在从头开始构建时会利用更多的计算量。
迁移学习机器学习背后的主要思想是利用在一项任务中学到的知识来增强另一项任务的泛化。以迁移学习为例,如果你最初训练了一个模型来对猫的图像进行分类,你将使用模型中的知识来识别其他图像,如狗。对于新的“任务 B”,我们应用网络在“任务 A”中学习到的权重。
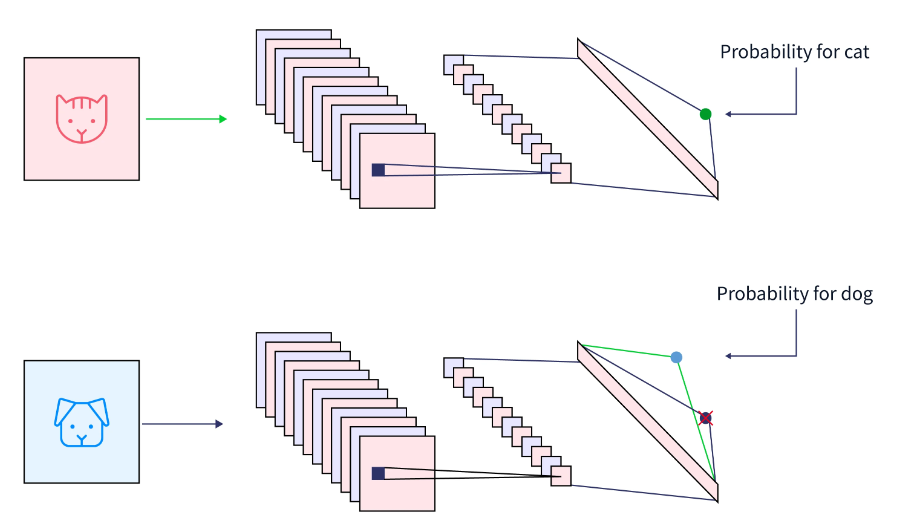
为什么要迁移学习?
获取用于培训的数据是一个大问题。相比之下,当我们使用迁移学习机器学习方法训练新任务时,重新训练所需的数据比从头开始训练模型要少,因为模型已经在与新任务类似的任务上进行了预训练。
深度学习算法需要很长时间才能从头开始训练复杂的任务,从而导致效率低下。例如,在考虑 NLP 任务时,模型的训练可能需要数天和数周的时间。但是,我们只能使用迁移学习来有效避免模型训练时间。
该模型具有更高的学习率,因为您之前在类似的任务上对其进行了训练。因此,当模型具有更好的基数和更高的学习率时,该模型会以更高的性能运行,并产生更准确的输出。
何时使用迁移学习
当为预训练模型的实际任务和新任务学习的权重不同时,应避免使用迁移学习技术。从预训练模型转移到新任务的权重将无法为您提供最佳结果,例如,如果您的新网络正在尝试识别鞋子和袜子,并且您训练了先前的网络对猫和狗进行分类。因此,最好使用与实际输出相当的预期输出相对应的预训练权重来启动网络,而不是使用不相关的权重。
如果从预训练模型中删除层,则会出现架构问题。通过减少可训练的参数数量和删除层,可能会发生过拟合。使用适当数量的层数对于防止过拟合至关重要。
有一些广受欢迎的预训练机器学习模型可用。Inception-v3 模型就是其中之一;它是为ImageNet“大型视觉识别挑战赛”开发的。这项挑战的参与者必须将照片分为 1,000 个类别,例如“斑马”、“斑点狗”和“洗碗机”。ResNet 和 AlexNet 模型也非常受欢迎。
特征提取
幸运的是,深度学习可以自动进行特征提取。但是,您仍必须决定要在网络中包含哪些功能。因此,这并不能消除特征工程和领域知识的价值。
您可以使用从预训练模型获取的表示形式来解决不同的问题。要确定正确的要素表示,请使用前几个图层;请谨慎使用网络的输出,因为它过于特定于任务。相反,通过其中一个中间级别输出数据并将其传输到您的网络中。
这种技术经常用于计算机视觉,因为它可以减小数据集的大小,加快计算速度,并使其更适合传统方法。
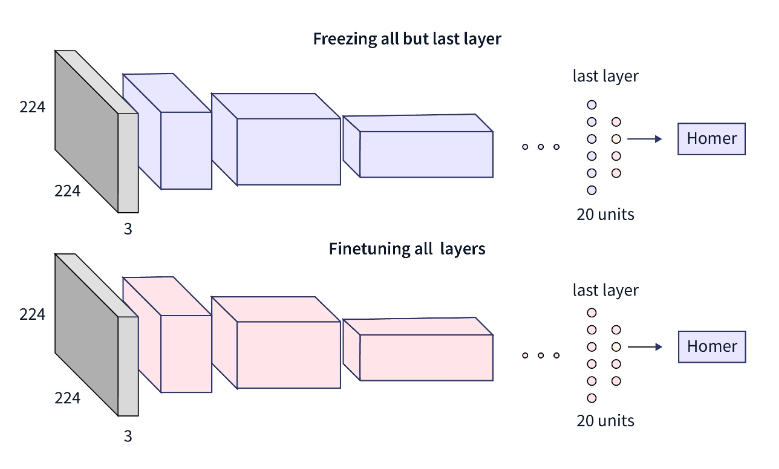
冻结还是微调?
冻结:在此步骤中,我们冻结仍然存在的每个层的权重,添加新的、完全连接的层,并使用更少的照片训练系统。当数据相似度高且数据大小最小时,我们采用此策略。
另一方面,微调意味着进行一些轻微的修改以进一步提高模型的性能。例如,您可以在迁移学习期间解冻预训练的模型,以便更好地适应特定任务。
例如,如果我们已经有一个预先训练的模型函数 f() 并想要学习它,我们可以用 g(f(x)) 来简化一个新函数 g()。 以这种方式,g() 通过 f() 查看所有数据。这可能需要调整以前学习的模型。我们还可以在学习阶段调整 f()。
由于更新过程在梯度的相反方向上以增量方式移动,因此可以认为学习过程只是微调。然而,微调通常是在最后保存的,并且需要降低学习率以准确修改权重。通常,学习过程以非常糟糕的开始条件和较大的学习率开始,随后可能包括微调阶段和较低的学习率。学习阶段可以分为几个微调阶段,每个阶段的学习率都低于前一个阶段。
深度迁移学习的类型
迁移学习通常被视为一种基本思想或原则,在这种思想或原则中,我们试图利用源任务领域的知识来完成目标任务。不幸的是,与迁移学习相关的术语被不分青红皂白地频繁使用。因此,区分迁移学习、领域适应和多任务学习有时可能很困难。但是,您可以确保所有问题都已连接,并旨在解决类似问题。
域采用
当源域和目标域之间的边际概率不同时,通常使用域适应。真实域和目标域的数据分布自然会发生变化或漂移,因此需要进行调整以传输学习结果。例如,来自产品评论的态度语料库与正面或负面电影评论的语料库不同。如果用于对产品评论进行分类,则根据电影评论情绪训练的分类器可能会观察到不同的分布。因此,在这些情况下,领域适应策略被用于迁移学习。
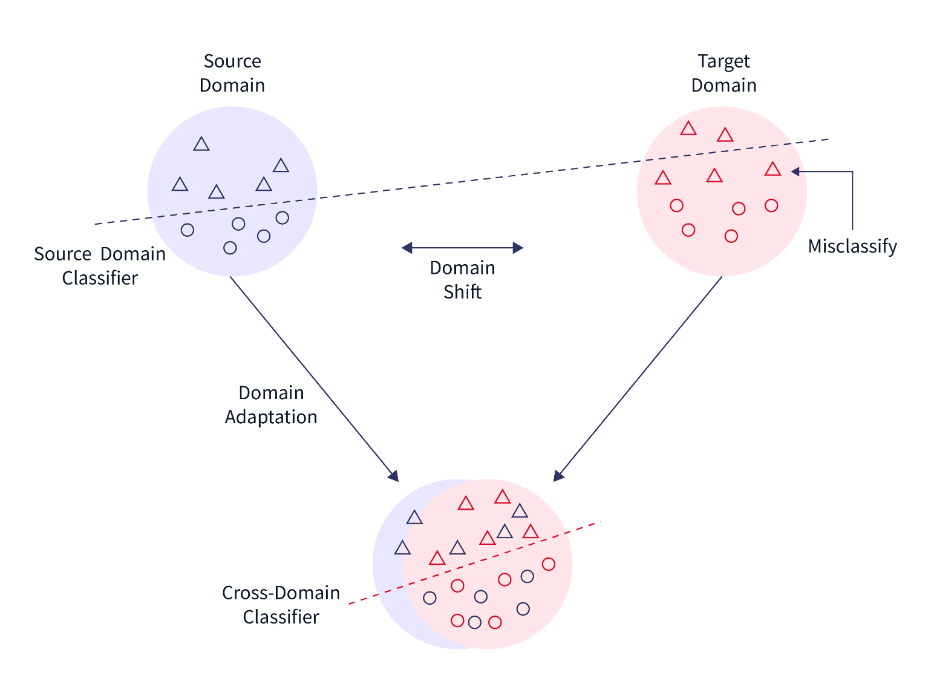
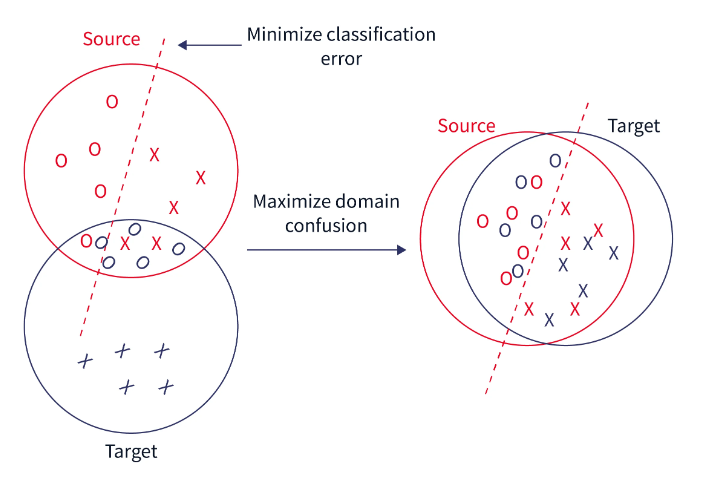
域混淆
我们推动两个领域的表示尽可能具有可比性,而不是让模型学习任何表示。这一事实使我们能够获得域不变特性并增强其域可移植性。我们可以通过直接对表示应用特定的预处理程序来做到这一点。
该技术的核心概念是在原始模型中添加一个新目的,通过混淆域本身来促进相似性,从而导致域混淆。
多任务学习
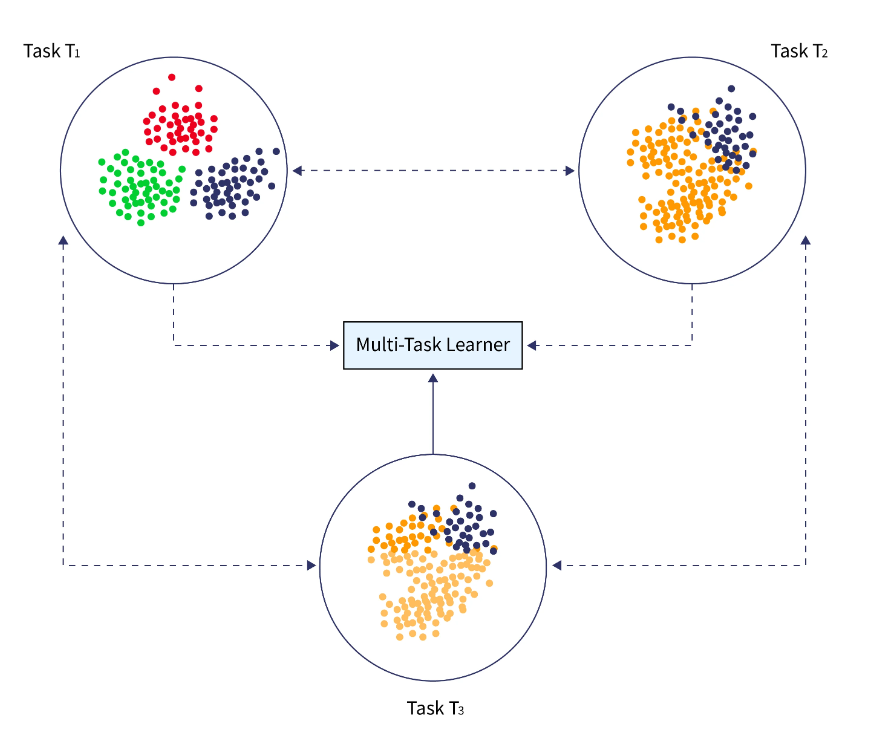
多任务学习是同时学习许多任务,而不区分源和目标。与迁移学习不同,学习者最初不知道目标任务,学习者同时学习有关众多任务的信息。
一次性学习
深度学习系统需要大量的训练样本来学习权重 b。这是深度神经网络的局限性之一,但人类的学习不受影响。例如,一旦一个年轻人学会了橙子的样子,他们就可以很快认出几个橙子品种;对于机器学习和深度学习方法来说,情况并非如此。一次性学习是迁移学习的一个子集,在这种学习中,我们尝试仅使用一个或少量的训练样本来预测所需的结果。当不可能为每个潜在类添加标记数据时,以及在经常添加新类的情况下,它有效地提供帮助。

零样本学习
迁移学习的另一种极端形式是“零样本学习”,它不需要标记样本来学习任务。这可能看起来很愚蠢,特别是因为大多数监督学习算法都专注于从实例中学习。然而,零数据学习技术,也称为零短学习技术,在训练过程中进行了巧妙的改变,以利用额外的知识来理解尚未看到的数据。零样本学习是指学习三个参数的情况,例如输入变量 (x)、输出变量 (y) 和指定作业的附加变量 (T)。因此,P(y | x, T) 的条件概率分布被教导给模型。

如何使用迁移学习?
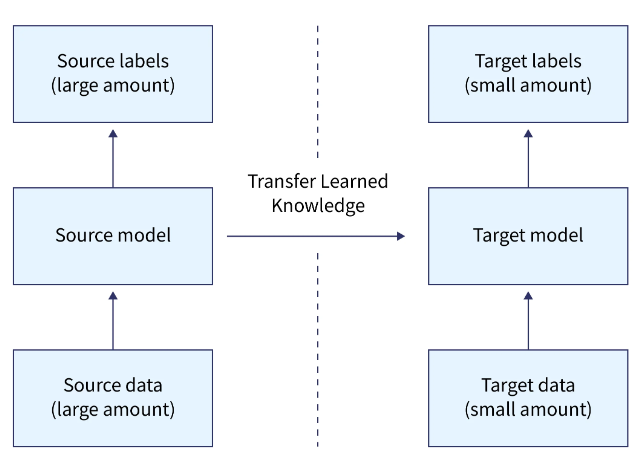
开发模型方法
想想一个问题,你想完成任务 A,但缺乏训练神经网络的数据。解决此问题的一种方法是找到任务 B,该任务是相关的,并且具有大量数据。
利用任务 B 作为神经网络的训练数据,然后使用模型解决任务 A。是需要使用完整的模型还是仅使用几个级别,将取决于您要解决的问题。
如果两个作业的输入相同,则可以重新应用模型并为新输入生成预测。另一方面,一种可以考虑的方法是更改和重新训练各种特定于任务的层和输出层。
预训练模型方法
利用现有的训练模型是第二种选择。提前研究这些模型,因为它们有很多可用。该任务确定要重用和重新训练的层数。
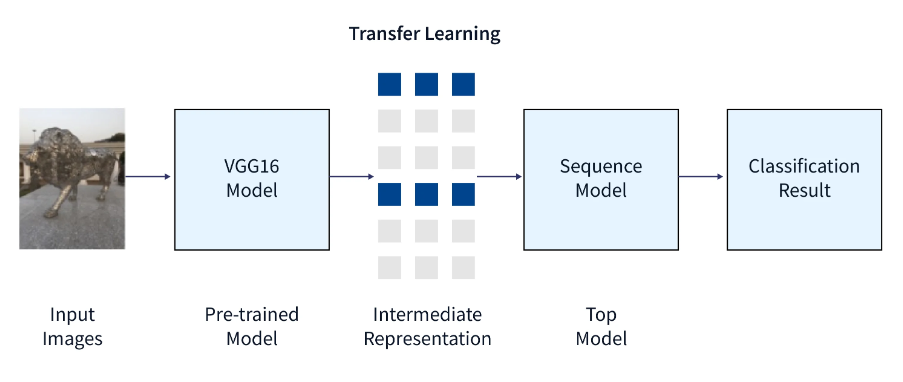
九个预训练模型组成了用于迁移学习、预测和微调的 Keras。您可以在此处找到这些模型,以及有关如何使用它们的一些基本教程。研究机构也广泛提供经过训练的模型。
使用图像进行迁移学习
让我们学习如何使用图像数据实现迁移学习示例,并在 colab 环境中对其进行微调。
下面是一个图像分类代码,用于对猫和狗的图像进行分类。
导入数据集
import matplotlib.pyplot as plt
import numpy as np
import os
import zipfile
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing import image_dataset_from_directory
# Download image data of Cat and Dog with labels
!wget 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
# Unzip the file downloaded
with zipfile.ZipFile('/content/cats_and_dogs_filtered.zip', 'r') as zip_ref:
zip_ref.extractall('/content')
# Get the file directories
base_dir = '/content/cats_and_dogs_filtered'
train_dir = "/content/cats_and_dogs_filtered/train"
validation_dir = "/content/cats_and_dogs_filtered/validation"
# Load training and validation set
training_set = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=32,
image_size=(150, 150))
val_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=32,
image_size=(150, 150))
数据增强
数据增强是从当前数据中创建额外的数据点,以人为地增加数据量。放大数据集可能涉及对数据进行小幅调整或利用机器学习模型在原始数据的潜在空间中生成新的数据点。
data_augmentation = keras.Sequential([keras.layers.experimental.preprocessing.RandomFlip("horizontal"),
keras.layers.experimental.preprocessing.RandomRotation(0.2),])
input_tensor = keras.Input(shape=(150, 150, 3))
x = data_augmentation(input_tensor)
# Visualize augmented data
for img, labels in training_set.take(1):
plt.figure(figsize=(12, 12))
load_image = img[0]
for i in range(12):
ax = plt.subplot(3, 4, i + 1)
augmented_image = data_augmentation(
tf.expand_dims(load_image, 0)
)
plt.imshow(augmented_image[0].numpy().astype("int32"))
plt.axis("off")
输出

导入预训练模型
# Preprocess data
x = tf.keras.applications.xception.preprocess_input(x)
Xception_model = keras.applications.Xception(
weights='imagenet',
input_shape=(150, 150, 3),
input_tensor = x,
include_top=False)
# we should freeze base model layers to prevent updates while training.
Xception_model.trainable = False
构建模型
model = Sequential()
model.add(Xception_model)
model.add(keras.layers.GlobalAveragePooling2D())
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(1))
model.compile(optimizer='adam', loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),metrics=keras.metrics.BinaryAccuracy())
model.fit(training_set, epochs=10, validation_data=val_dataset)
输出
Found 2000 files belonging to 2 classes.
Found 1000 files belonging to 2 classes.
Epoch 1/10
63/63 [==============================] - 21s 143ms/step - loss: 0.3208 - binary_accuracy: 0.8510 - val_loss: 0.1115 - val_binary_accuracy: 0.9610
Epoch 2/10
63/63 [==============================] - 8s 116ms/step - loss: 0.2046 - binary_accuracy: 0.9115 - val_loss: 0.0912 - val_binary_accuracy: 0.9690
Epoch 3/10
63/63 [==============================] - 8s 119ms/step - loss: 0.1729 - binary_accuracy: 0.9280 - val_loss: 0.0868 - val_binary_accuracy: 0.9650
Epoch 4/10
63/63 [==============================] - 8s 119ms/step - loss: 0.1781 - binary_accuracy: 0.9240 - val_loss: 0.0838 - val_binary_accuracy: 0.9670
Epoch 5/10
63/63 [==============================] - 8s 119ms/step - loss: 0.1605 - binary_accuracy: 0.9305 - val_loss: 0.0820 - val_binary_accuracy: 0.9720
Epoch 6/10
63/63 [==============================] - 8s 127ms/step - loss: 0.1516 - binary_accuracy: 0.9385 - val_loss: 0.0880 - val_binary_accuracy: 0.9690
Epoch 7/10
63/63 [==============================] - 8s 118ms/step - loss: 0.1570 - binary_accuracy: 0.9390 - val_loss: 0.0810 - val_binary_accuracy: 0.9690
Epoch 8/10
63/63 [==============================] - 8s 118ms/step - loss: 0.1452 - binary_accuracy: 0.9370 - val_loss: 0.0860 - val_binary_accuracy: 0.9670
Epoch 9/10
63/63 [==============================] - 8s 119ms/step - loss: 0.1429 - binary_accuracy: 0.9370 - val_loss: 0.0781 - val_binary_accuracy: 0.9680
Epoch 10/10
63/63 [==============================] - 8s 119ms/step - loss: 0.1465 - binary_accuracy: 0.9400 - val_loss: 0.0775 - val_binary_accuracy: 0.9670
微调模型
# Fine Tune to improve the accuracy of the model a bit more
print("After FineTuning the model")
Xception_model.trainable = True
model.compile(optimizer=keras.optimizers.Adam(1e-5),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=keras.metrics.BinaryAccuracy())
model.fit(training_set, epochs=10, validation_data=val_dataset))
输出
After FineTuning the model
Epoch 1/10
63/63 [==============================] - 30s 364ms/step - loss: 0.3934 - binary_accuracy: 0.8405 - val_loss: 0.1054 - val_binary_accuracy: 0.9570
Epoch 2/10
63/63 [==============================] - 22s 342ms/step - loss: 0.3215 - binary_accuracy: 0.8605 - val_loss: 0.1216 - val_binary_accuracy: 0.9570
Epoch 3/10
63/63 [==============================] - 21s 338ms/step - loss: 0.2782 - binary_accuracy: 0.8785 - val_loss: 0.1239 - val_binary_accuracy: 0.9570
Epoch 4/10
63/63 [==============================] - 21s 338ms/step - loss: 0.2449 - binary_accuracy: 0.8985 - val_loss: 0.1166 - val_binary_accuracy: 0.9630
Epoch 5/10
63/63 [==============================] - 21s 335ms/step - loss: 0.2130 - binary_accuracy: 0.9115 - val_loss: 0.1115 - val_binary_accuracy: 0.9630
Epoch 6/10
63/63 [==============================] - 22s 340ms/step - loss: 0.1905 - binary_accuracy: 0.9230 - val_loss: 0.1091 - val_binary_accuracy: 0.9640
Epoch 7/10
63/63 [==============================] - 21s 336ms/step - loss: 0.1713 - binary_accuracy: 0.9355 - val_loss: 0.1013 - val_binary_accuracy: 0.9670
Epoch 8/10
63/63 [==============================] - 21s 333ms/step - loss: 0.1487 - binary_accuracy: 0.9445 - val_loss: 0.0979 - val_binary_accuracy: 0.9660
Epoch 9/10
63/63 [==============================] - 21s 336ms/step - loss: 0.1345 - binary_accuracy: 0.9515 - val_loss: 0.0898 - val_binary_accuracy: 0.9710
Epoch 10/10
63/63 [==============================] - 21s 336ms/step - loss: 0.1370 - binary_accuracy: 0.9485 - val_loss: 0.0866 - val_binary_accuracy: 0.9710
使用语言数据进行迁移学习
我们将在情感分析数据集上使用预训练的 Glove 嵌入实现迁移学习示例。
导入数据
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.models import Sequential
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import zipfile
# Download the required data
!wget --no-check-certificate https://drive.google.com/uc?id=13ySLC_ue6Umt9RJYSeM2t-V0kCv-4C-P -O /content/sentiment.csv -O /content/sentiment.csv
df = pd.read_csv('/content/sentiment.csv')
print(df.head())
输出
Unnamed: 0 text sentiment
0 0 So there is no way for me to plug it in here i... 0
1 1 Good case Excellent value. 1
2 2 Great for the jawbone. 1
3 3 Tied to the charger for conversations lasting more... 0
4 4 The mic is great. 1
数据预处理
X = df['text']
y = df['sentiment']
# Split training set and testing set
X_train, X_test , y_train, y_test = train_test_split(X, y , test_size = 0.20)
#Data preprocessing
vocabulary_size = 10000
non_vocab_token = "<OOV>"
# Tokenizer strips out punctuation and other special characters and lowercase the sentence.
tokenizer = Tokenizer(num_words = vocabulary_size, oov_token=non_vocab_token)
tokenizer.fit_on_texts(X_train)
word_index = tokenizer.word_index
# Convert words into sentences
X_train_sequences = tokenizer.texts_to_sequences(X_train)
X_test_sequences = tokenizer.texts_to_sequences(X_test)
# The length of the sequences will vary depending on the length of the sentences using padding
maxlen = 100
X_train_pad = pad_sequences(X_train_sequences, maxlen= maxlen, padding= "post", truncating = "post")
X_test_pad = pad_sequences(X_test_sequences, maxlen= maxlen, padding= "post", truncating = "post")
加载嵌入
# Download pretrained word embeddings **Glove**
!wget --no-check-certificate http://nlp.stanford.edu/data/glove.6B.zip -O /content/glove.6B.zip
embedded_index = {}
file = open('/content/glove/glove.6B.100d.txt')
for line in the file:
values = line.split()
word = values[0]
coefficients = np.asarray(values[1:], dtype='float32')
embedded_index[word] = coefficients
file.close()
print(' %s word vectors found' % len(embedded_index))
输出
400000 word vectors found
构建模型
# Emedding matrix with training set
embedded_matrix = np.zeros((len(word_index) + 1, maxlen))
for word, i in word_index.items():
embedding_vector = embedded_index.get(word)
if embedding_vector is not None:
# words not found in the embedding index will be all-zeros.
embedded_matrix[i] = embedding_vector
# Create an embedding layer
embedding_layer = Embedding(len(word_index) + 1,
maxlen,
weights=[embedded_matrix],
input_length=maxlen,
trainable=False)
#Creating a Sequential model with the embedding layer
model = Sequential()
model.add(embedding_layer)
model.add(Bidirectional(LSTM(150,return_sequences=True)))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(6,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit(X_train_pad, y_train, epochs=10, validation_data=(X_test_pad, y_test))
输出
Epoch 1/10
50/50 [==============================] - 13s 56ms/step - loss: 0.6145 - accuracy: 0.6522 - val_loss: 0.5632 - val_accuracy: 0.6842
Epoch 2/10
50/50 [==============================] - 1s 28ms/step - loss: 0.4793 - accuracy: 0.7772 - val_loss: 0.5334 - val_accuracy: 0.7293
Epoch 3/10
50/50 [==============================] - 1s 27ms/step - loss: 0.4268 - accuracy: 0.8029 - val_loss: 0.4683 - val_accuracy: 0.7694
Epoch 4/10
50/50 [==============================] - 1s 29ms/step - loss: 0.3782 - accuracy: 0.8336 - val_loss: 0.4875 - val_accuracy: 0.7544
Epoch 5/10
50/50 [==============================] - 1s 28ms/step - loss: 0.3383 - accuracy: 0.8650 - val_loss: 0.4649 - val_accuracy: 0.7719
Epoch 6/10
50/50 [==============================] - 1s 28ms/step - loss: 0.3703 - accuracy: 0.8362 - val_loss: 0.4787 - val_accuracy: 0.7619
Epoch 7/10
50/50 [==============================] - 1s 28ms/step - loss: 0.3309 - accuracy: 0.8632 - val_loss: 0.5398 - val_accuracy: 0.7544
Epoch 8/10
50/50 [==============================] - 1s 28ms/step - loss: 0.2775 - accuracy: 0.8901 - val_loss: 0.4805 - val_accuracy: 0.7719
Epoch 9/10
50/50 [==============================] - 1s 28ms/step - loss: 0.2418 - accuracy: 0.9058 - val_loss: 0.5583 - val_accuracy: 0.7870
Epoch 10/10
50/50 [==============================] - 1s 30ms/step - loss: 0.2433 - accuracy: 0.9027 - val_loss: 0.5381 - val_accuracy: 0.7744
结论
- 深度学习网络的动态特性使得更改已经针对各种应用程序和数据集预训练的模型成为可能。因此,该领域有价值的研究数量正在迅速增长。
- 在本文中,我们使用预训练的 Xception 模型进行图像处理,并使用了 Glove;一种称为 GloVe 的无监督学习方法用于在 NLP 任务中构建向量表示。
- 迁移学习促进了模型的开发和实施。我们预计会看到迁移学习的更多功能,因为深度学习对于解决自然语言处理(NLP)和视频处理等领域的各种问题至关重要。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











