








rXiv:1501.00092v3 [cs.CV] 31 Jul 2015
题目:Image Super-Resolution Using DeepConvolutional Networks(SRCNN)
1、可以从http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html.获得该实现。当地面真实图像可用时。
2、标题通过使用不同的度量标准(例如,峰值信噪比(PSNR),结构相似性指数(SSIM)[43],多尺度SSIM [44],信息保真度标准[38])进行数值评估。
3.双三次插值也是一种卷积运算,因此可以表述为卷积层。但是,此层的输出大小大于输入大小,因此存在小步跨度。为了利用诸如cuda-convnet [26]之类的广受欢迎且经过优化的实施方案,我们将这一“层”排除在“layer"之外。
4. ReLU可以等效地视为第二个操作(非线性映射)的一部分,而第一个操作(补丁提取和表示)将变成纯线性
摘要:
- 我们提出了一种用于
单图像超分辨率(SR)的深度学习方法。我们的方法直接学习低/高分辨率图像之间的端到端映射。映射表示为深度卷积神经网络(CNN),该神经网络将低分辨率图像作为输入并输出高分辨率图像【这就是端到端】。我们进一步表明,传统的基于稀疏编码的SR方法也可以视为深度卷积网络。但是与传统方法分别处理每个组件不同,我们的方法共同优化了所有层。我们的深层CNN具有轻巧的结构,同时展现了最先进的恢复质量,并为实际在线使用提供了快速的速度。我们探索了不同的网络结构和参数设置,以实现性能和速度之间的折衷。此外,我们扩展了网络以同时处理三个颜色通道,并展现出更好的整体重建效果。【单图超分辨、端到端】
研究背景:单图超分辨
研究对象:普通图像,单一图像
研究方法:CNN网络,低分辨图像输入,输出高分辨图像。端到端。
研究结论:不同于传统的恢复处理单个部件,我们的方法共同优化所有层,效果很好
1、引言
单一图像超分辨率(SR)[20]旨在从单个低分辨率图像中恢复高分辨率图像,这是计算机视觉中的经典问题。由于对于任何给定的低分辨率像素都存在多种解决方案,因此该问题天生就不适。换句话说,这是一个不确定的逆问题,其解决方案不是唯一的。通常通过强先验信息约束解决方案空间来缓解这种问题。要了解现有技术,最近的最新技术大多采用基于示例的[46]策略。这些方法要么利用同一图像的内部相似性[5],[13],[16],[19],[47],要么从外部低分辨率和高分辨率示例对[2],[4], [6],[15],[23],[25],[37],[41],[42],[47],[48],[50],[51]。根据提供的训练样本,可以将基于示例的外部方法制定为通用图像超分辨率,或设计为适合特定领域的任务,比如人脸超分辨[30],[50]。【】基于稀疏编码的方法[49],[50]是代表性的基于外部示例的SR方法之一。该方法涉及其解决方案流程中的几个步骤:首先,从输入图像中密集裁剪出重叠的补丁并进行预处理(例如,减去均值和归一化)。然后,这些补丁通过低分辨率字典进行编码。将稀疏系数传递到高分辨率字典中,以重建高分辨率色块。- 将重叠的重建面片聚合(例如,通过加权平均)以产生最终输出。此管道由大多数基于实例的外部方法共享,这些方法特别注意学习和优化字典[2]、[49]、[50]或构建有效的映射函数[25]、[41]、[42]、[47]。然而,管道中的其余步骤很少得到优化,或者在统一的优化框架中得到考虑。
- 在本文中,我们证明了
上述管道等效于深度卷积神经网络[27](在3.2节中有更多详细信息)。基于这一事实,我们考虑了一个卷积神经网络,该网络可以直接学习低分辨率和高分辨率图像之间的端到端映射。我们的方法与现有的基于外部示例的方法从根本上不同,因为我们没有显式学习用于建模补丁空间的字典[41],[49],[50]或流形[2],[4]。这些是通过隐藏层隐式实现的。此外,补丁提取和聚集也被公式化为卷积层,因此涉及优化。在我们的方法中,整个SR流水线是通过学习完全获得的,几乎不需要预处理。【将传统的管道方法改进为深度神经网络方法。并且将一些方法直接用隐藏层实现出来】 - 我们将提出的模型命名为超分辨率卷积神经网络(SRCNN)
- 1。提出的SRCNN具有几个吸引人的特性。首先,它的结构在设计时考虑了简单性,但与基于示例的最新方法相比,却提供了更高的准确性。图1显示了一个示例的比较。【结构简单、效果好】
- 2,通过适当的滤波器和层数,我们的方法实现了快速的实际在线使用,甚至在一个CPU上。我们的该方法比许多基于实例的方法更快,因为它是完全前馈的,不需要求解任何优化问题第三种用法, 实验表明,当(i)有更大、更多样化的数据集,和/或(ii)使用更大、更深的模型时,网络的恢复质量可以进一步提高。相反,基于数据集的方法会带来更大的挑战。此外,该网络能同时处理三通道彩色图像,提高了超分辨率性能。【在线应用,使用方便】
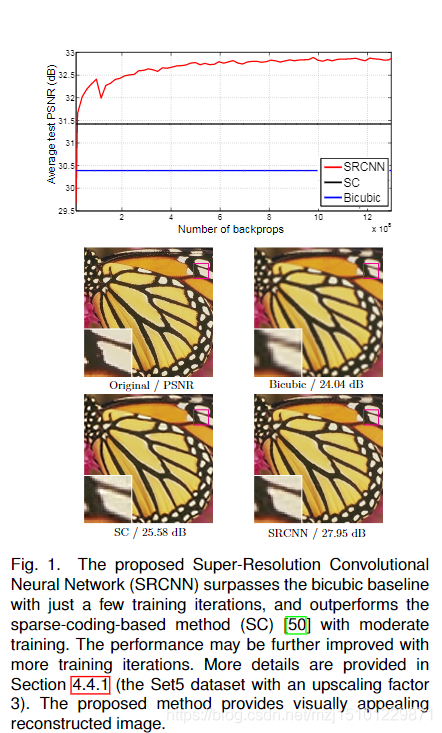
图1.提出的超分辨率卷积神经网络(SRCNN)仅经过几次训练迭代就超过了三次三次基线,并且在中等训练的情况下优于基于稀疏编码的方法(SC)[50]。通过更多的训练迭代可以进一步提高性能。在第4.4.1节(Set5数据集具有放大系数3)中提供了更多详细信息。所提出的方法提供了视觉吸引力的重建图像。
- 总的来说,这项研究的贡献主要在三个方面:
- 1)我们
提出了一种用于图像超分辨率的全卷积神经网络。该网络可直接学习低分辨率和高分辨率图像之间的端到端映射,而无需进行优化即可进行很少的前/后处理。 - 2)我们
建立了基于深度学习的SR方法和传统的基于解析编码的SR方法之间的关系。这种关系为网络结构的设计提供了指导。 - 3)我们证明了
深度学习在经典的超分辨率计算机视觉问题中是有用的,并且可以获得很好的质量和速度。
- 1)我们
- 较早提出了这项工作的初步版本[11]。目前的工作以重要的方式增加了初始版本。
- 首先,我们
通过在非线性映射层中引入更大的滤波器大小来改进SRCNN,并通过添加非线性映射层来探索更深的结构。【非线性映射层中加入更大的滤波器】 - 其次,我们将SRCNN扩展为同时处理三个颜色通道(在YCbCr或RGBcolor空间中)。通过实验,我们证明与单通道网络相比,性能可以提高。【扩展为同时处理3个颜色通道】
- 第三,将大量的新分析和直观的解释添加到初始结果中。我们还将原始实验从Set5 [2]和Set14 [51]测试图像扩展到BSD200 [32](200个测试图像)。
- 此外,我们与大量最新发布的方法进行了比较,并确认我们的模型使用不同的评估指标仍胜过现有方法。
- 首先,我们
2、相关工作
2.1 Image Super-Resolution
- 根据图像先验,单图像超分辨算法可分为四种类型:
预测模型,基于边缘的方法,图像统计方法和基于补丁(或基于示例)的方法。这些方法已在Yanget等人的工作[46]中进行了深入研究和评估。其中,基于示例的方法[16],[25],[41],[47]实现了最先进的性能。 - 基于内部示例的方法利用自相似性属性并从输入图像生成示例补丁。它是在Glasner的工作中首次提出的[16],并提出了几种改进的变体[13],[45]以加速实施。
基于示例的外部方法[2],[4],[6],[15],[37],[41],[48],[49],[50],[51]学习映射在来自外部数据集的低/高分辨率补丁之间。这些研究主要涉及如何学习紧凑的字典或流形空间以关联低/高分辨率的补丁,以及如何在这种空间中执行表示方案。在Freemanet等人[14]的开创性工作中,直接介绍了字典。作为低/高分辨率补丁对,在低分辨率空间中找到输入补丁的最近邻居(NN),并使用其对应的高分辨率补丁进行重构。[4]引入了多种嵌入技术来替代NN策略。在Yangnet等人的著作[49],[50]中,上述NN对应关系发展为更复杂的稀疏编码公式。其他映射函数,例如内核回归[25],简单提出了3函数[47],随机森林[37]和锚定近邻回归[41],[42],以进一步提高地图绘制的准确性和速度。基于稀疏编码的方法及其一些改进[41],[42],[48]是当今最先进的SR方法之一。在这些方法中,补丁是优化的重点。补丁提取和聚集步骤被视为预处理/后处理,并分别进行处理。 - 大多数SR算法[2],[4],[15],[41],[48]&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









