






streamlit介绍
Streamlit 是一款专为数据科学家和机器学习工程师打造的开源 Python 库,具有上手快、效率高的特点,它提供了丰富的功能,包括但不限于:按钮、滑块、图表等多样化组件助力打造交互界面;能读取多种格式数据并展示、支持实时更新,方便数据处理与可视化;可集成大模型、机器学习库,轻松构建模型推理、大模型交互应用;还支持一键本地部署及云部署分享,凭借热重载等特性提升开发体验,广泛适用于数据应用开发、模型演示、大模型交互等场景。
详情见:st.chat_message - Streamlit Docs
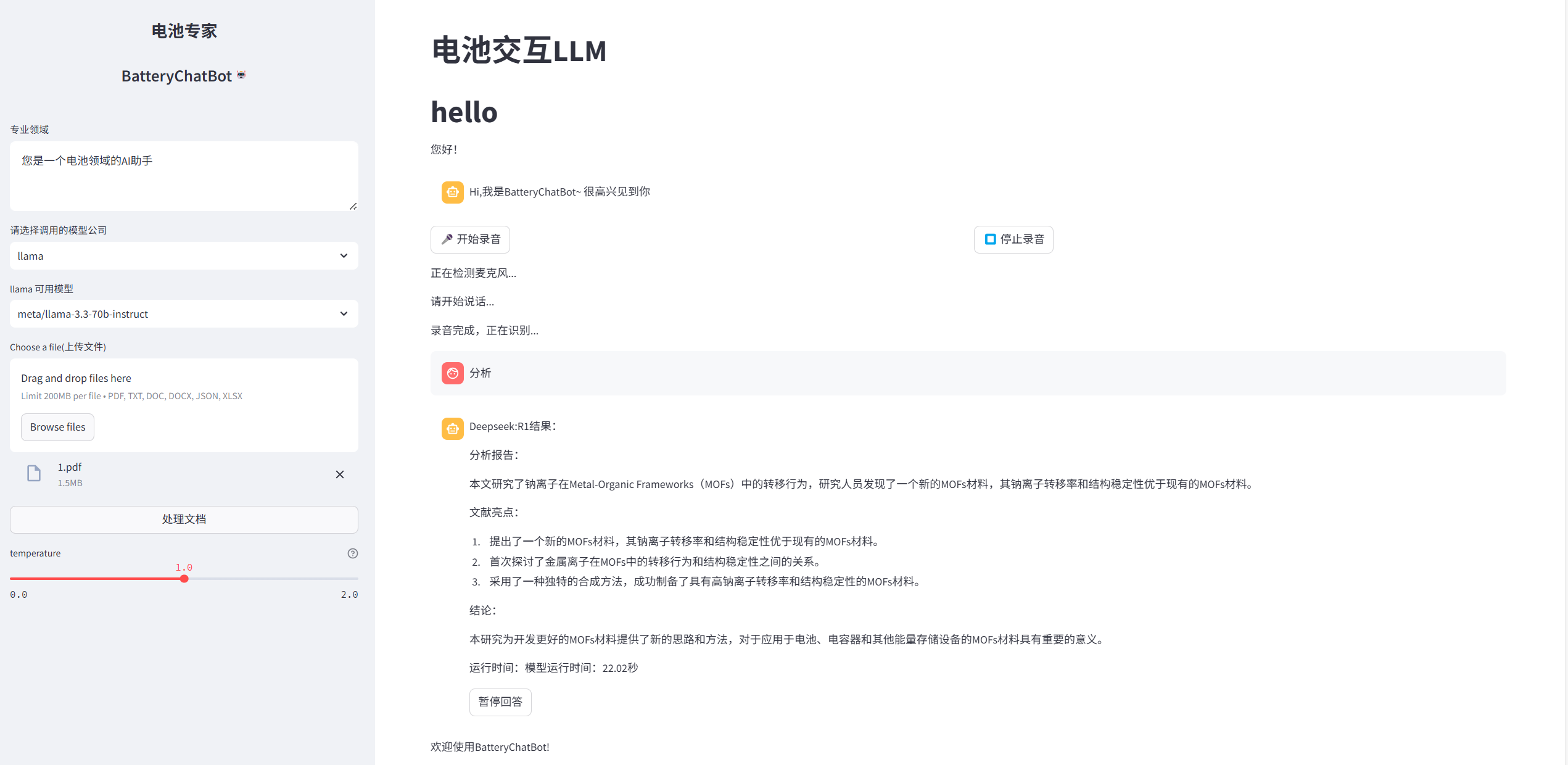
效果展示
本次使用了llama模型,llama模型的API_KEY申请方法见:主流AI大模型的python代码调用和代码示例-CSDN博客
基于文本向量库的构建可见:基于PDF文献的本地向量库构建和大模型检索(LLM-向量数据库)-CSDN博客
代码展示:
1.导包需求:
import docx
import time
import streamlit as st
from openai import OpenAI
from PyPDF2 import PdfReader
from langchain_core.documents import Document
import speech_recognition as sr
import pyttsx32. 初始化语音引擎和语音识别
# 语音引擎初始化
engine = pyttsx3.init()
def speak(text):
"""将文本转换为语音输出"""
try:
engine.say(text)
engine.runAndWait()
except Exception as e:
st.error(f"语音播放失败: {e}")
st.session_state.audio_error = str(e) # 保存错误信息到会话状态
def recognize_speech():
"""从麦克风录制音频并转换为文本"""
recognizer = sr.Recognizer()
from speech_recognition import recognizers
try:
with sr.Microphone() as source:
st.session_state.recording = True
st.write("正在检测麦克风...")
recognizer.adjust_for_ambient_noise(source, duration=1)
audio = None
st.write("请开始说话...")
audio = recognizer.listen(source, timeout=5, phrase_time_limit=10)
st.write("录音完成,正在识别...")
text = recognizer.recognize_sphinx(audio, language='zh-CN')
#text = text.hypothesis()
return text
except sr.WaitTimeoutError:
return "等待超时,请重试"
except sr.UnknownValueError:
return "无法识别语音内容"
except sr.RequestError as e:
return f"服务不可用:{str(e)}"
except Exception as e:
st.error(f"录音错误:{str(e)}")
return f"录音失败:{str(e)}"
finally:
st.session_state.recording = False3. 定义文件处理函数
def get_pdf_text(pdf_docs):
docs = []
for document in pdf_docs:
if document.type == "application/pdf":
pdf_reader = PdfReader(document)
for idx, page in enumerate(pdf_reader.pages):
docs.append(
Document(
page_content=page.extract_text(),
metadata={"source": f"{document.name} on page {idx}"},
)
)
elif (
document.type
== "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
):
doc = docx.Document(document)
for idx, paragraph in enumerate(doc.paragraphs):
docs.append(
Document(
page_content=paragraph.text,
metadata={"source": f"{document.name} in paragraph {idx}"},
)
)
return docs4.定义大模型交互函数
def chat_stream(query, system_message=None, temperature=None, option=None, docs=None):
if system_message:
messagesHistory.append({"role": "system", "content": system_message})
#提示词模板
prompt_template1 = (
f"根据上传的文件内容\n{docs}\n 和问题\n{user_query}\n分析电池的性能,最后生成文献亮点总结的分析报告。"
)
messagesHistory.append({"role": "user", "content": prompt_template1})
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="API_KEY"
)
response = client.chat.completions.create(
model=option,
messages=messagesHistory,
stream=True,
temperature=temperature
)
return response5.streamlit交互系统
#信息容器初始化
if "messagesHistory" not in st.session_state:
messagesHistory = []
if "docs" not in st.session_state:
st.session_state.docs = None
#设置界面标题
st.title("电池交互LLM")
st.title('hello')
st.write(
"""
您好!
"""
)
# 初始化聊天记录
if "messages" not in st.session_state:
st.session_state.messages = [{
"role": "assistant",
"content": "Hi,我是BatteryChatBot~ 很高兴见到你"
}]
# 从app历史回复中显示聊天信息
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
with st.sidebar:
st.markdown(f"""
<center>
<h1>电池专家</h1>
<h1>BatteryChatBot <sup>🤖</sup><h1/>
</center>
""", unsafe_allow_html=True)
# 角色定义输入框 page_message
system_message = st.text_area("专业领域", "您是一个电池领域的AI助手")
# 模型选择
company = {
'llama': ['meta/llama-3.3-70b-instruct'],
'Deepseek': ['DeepSeek-R1-Distill-Llama-70B', 'Deepseek-R1'],
'智谱AI': ['glm-4', 'glm-3', 'glm-4-9b', 'glm-4-Long', 'glm-4-plus', 'glm-4-9b:605664196::3or9hkmu'],
'OpenAI': ['gpt-3.5-turbo', 'gpt-4', 'gpt-4o'],
'百度': ['ERNIE 4.0', 'ERNIE 4.0 Turbo', 'ERNIE 3.5'],
}
company_name = st.selectbox(
label='请选择调用的模型公司',
options=list(company.keys())
)
option = st.selectbox(
label=f'{company_name} 可用模型',
options=company[company_name]
)
# 文件上传控件
pdf_docs = st.file_uploader(
"Choose a file(上传文件)",
# 支持的文件类型
type=["pdf", "txt", "doc", "docx", 'json', 'xlsx'],
# 支持多文件上传
accept_multiple_files=True,
)
if pdf_docs is not None:
if st.button(
"处理文档",
on_click=lambda: setattr(st.session_state, "last_action", "pdf"),
use_container_width=True,
):
if pdf_docs:
with st.spinner("文档处理中..."):
st.session_state.docs = get_pdf_text(pdf_docs)
st.success("文档处理完成,可以使用了")
temperature = st.slider("temperature", min_value=0.0, max_value=2.0, value=1.0, step=0.1, help="值越大越具有创造力",
format="%.1f")
# 初始化语音相关状态
if 'recording' not in st.session_state:
st.session_state.recording = False
if 'audio_error' not in st.session_state:
st.session_state.audio_error = None
# 语音控制按钮列布局
col1, col2 = st.columns(2)
with col1:
if st.button("🎤 开始录音", disabled=st.session_state.recording):
st.session_state.mic_button = True
st.session_state.user_query = None # 清除之前的查询
with col2:
if st.button("⏹️ 停止录音"):
st.session_state.mic_button = False
# 显示语音识别状态
if st.session_state.recording:
st.warning("正在录音中...")
# 显示语音错误信息
if st.session_state.audio_error:
st.error(f"音频错误:{st.session_state.audio_error}")
st.session_state.audio_error = None # 显示后清除错误
# 语音输入处理逻辑
if st.session_state.get("mic_button", False):
user_query1 = recognize_speech()
else:
user_query1 = st.chat_input("请输入您的问题...")
user_query=user_query1
if user_query:
# 显示用户输入的内容到聊天窗口
with st.chat_message("user"):
st.write(user_query)
st.session_state.messages.append({"role": "user", "content": user_query})
# 使用 OpenAI 服务处理用户问题,stream 流式输出 LLM 的答案
with st.chat_message("assistant"):
with st.spinner("🤖思考中..."):
try:
# 记录开始时间
start_time = time.time()
# 用 OpenAI 对话服务
response = chat_stream(user_query, system_message, temperature, option, st.session_state.docs)
# 创建显示消息的容器
message_placeholder = st.empty()
# AI 的答案
ai_response = ""
# 暂停和继续按钮
pause_button = st.button("暂停回答", key="pause_button")
# 增加中断功能
is_interrupted = False
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content:
ai_response += chunk.choices[0].delta.content
message_placeholder.markdown(ai_response + "▌")
# 检查是否暂停
if pause_button:
is_interrupted = True
break
# 短暂延迟以允许 UI 更新
time.sleep(0.1)
else:
elapsed_time = time.time() - start_time
runtime_message = f"模型运行时间:{elapsed_time:.2f}秒"
ai_response = f"Deepseek:R1结果:\n\n{ai_response}\n\n运行时间:{runtime_message}"
message_placeholder.markdown(ai_response)
# 将助手的回复加入会话历史
st.session_state.messages.append({"role": "assistant", "content": ai_response})
# 语音播报回答
if st.session_state.get("display_play_audio_button", False):
speak(ai_response)
except Exception as e:
st.error(f"AI 服务调用失败: {e}")
st.write("欢迎使用BatteryChatBot!")

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









