







背景
在深度神经网络学习和优化中,超参数调整一项必备技能,通过观察在训练过程中的监测指标如损失loss和准确率来判断当前模型处于什么样的训练状态,及时调整超参数以更科学地训练模型能够提高资源利用率。在本研究中使用了以下超参数,下面将分别介绍并总结了不同超参数的调整规则。

神经网络常用参数
神经网络中常用的参数有以下几种:
1.权重(Weights):用于调整输入特征与神经元之间的连接强度,影响神经元对不同输入的响应程度。
2.偏置(Biases):用于调整神经元的激活阈值,影响神经元的激活状态。
3.学习率(Learning Rate):用于控制权重和偏置在每次迭代中的更新幅度,影响神经网络的训练速度和收敛性。
4.批量大小(Batch Size):指每次迭代更新时参与计算的样本数量,影响训练的速度和稳定性。
5.激活函数(Activation Function):用于引入非线性变换,增加神经网络的表达能力,常用的激活函数包括ReLU、Sigmoid、Tanh等。
6.优化器(Optimizer):用于更新神经网络的参数,常用的优化器包括SGD、Adam、RMSprop等。
7.正则化参数(Regularization Parameters):用于控制神经网络的复杂度,防止过拟合,包括L1正则化、L2正则化等。
这些参数在神经网络的训练和优化过程中起着重要作用,通过调整这些参数可以影响神经网络的性能和泛化能力。
介绍
(1)学习率
学习率是一个比较重要的参数,控制我们要多大程度调整网络的权重,以符合梯度损失。 值越低,沿着梯度下降越慢。 虽然使用较小学习率可能是一个 好主意,以确保我们不会错过任何局部最低点,但也可能意味着我们将花费很长的时间来收敛——特别是当我们卡在平稳区域(plateau region)的时候。
以下公式显示了这种关系。
new_weight = existing_weight — learning_rate * gradient

通常,学习率是由用户随意配置的。 用户最多也只能通过之前的经验来配置最佳的学习率。
因此,很难得到好的学习率。 下图演示了配置学习速率时可能遇到的不同情况。
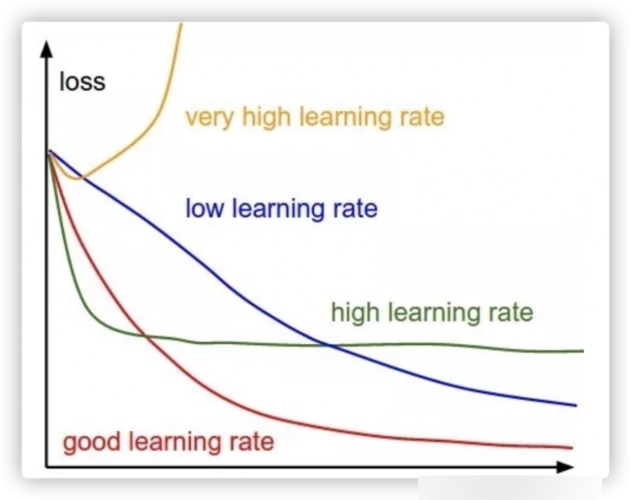
与此同时,学习率会影响我们的模型能够以多快的速度收敛到局部最小值(也就是达到最好的精度)。 因此,从正确的方向做出正确的选择意味着我们能用更少的时间来训练模型。 较少的训练时间,花在GPU计算上的花费较少。在“Cyclical Learning Rates for Training Neural Networks.”的第3.3节[4]中,Leslie N. Smith认为,可以在模型初始化的时候设置一个非常小的学习率,通过每次迭代地增加它(线性或指数级地 )。
如果我们记录每次迭代的学习,并绘制学习率(对数)与损失; 我们会看到,随着学习率的提高,会有一个损失停止下降并开始增加的点。 在实践中,我们的学习率理想情况下应该是从图的左边到某处最低点(如下图所示)。 在下图中,0.001到0.01。
使用
目前,它是fast.ai包的一个API,它是由Jeremy Howard开发的一种基于Pytorch的包(很像Keras和Tensorflow的关系)。在训练神经网络之前,只需输入以下命令即可开始找到最佳学习率。
▌更近一步
我们已经介绍了什么是学习速度,接下来有一点是很重要的,即当我们开始训练我们的模型时,我们怎样才能系统地达到最佳的使用价值。
接下来,我们将介绍如何利用学习率来改善模型的性能。
▌传统方法
通常,当设定他们的学习率并训练模型时,只有等待学习速率随着时间的推移而下降,并且模型才能最终收敛。
然而,随着梯度达到稳定水平(plateau),训练损失变得更难以改善。 在[3]中,Dauphin等人认为,减少损失的难度来自鞍点(saddle points),而不是局部最低点。
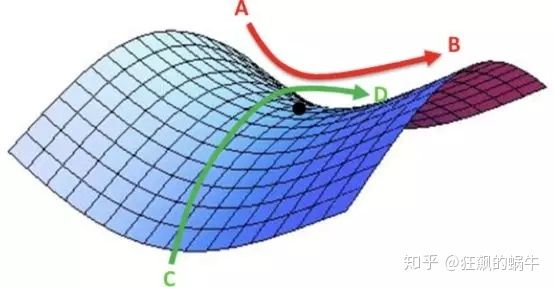
▌那么我们怎么避免呢?
有几个选项我们可以考虑。 一般来说,从文章[1]引用一句:
...而不是使用一个固定值的学习速度,并随着时间的推移而降低,如果训练不会改善我们的损失,我们将根据一些循环函数f来改变每次迭代的学习速率。 每个周期的迭代次数都是固定的。 这种方法让学习率在合理的边界值之间循环变化。 这是有帮助的,因为如果我们卡在鞍点上,提高学习速度可以更快速地穿越鞍点高原。
学习率(learning rate或作lr)是指在优化算法中更新网络权重的幅度大小。学习率可以是恒定的、逐渐降低的,基于动量的或者是自适应的。不同的优化算法决定不同的学习率。当学习率过大则可能导致模型不收敛,损失loss不断上下震荡;学习率过小则导致模型收敛速度偏慢,需要更长的时间训练。通常lr取值为[0.01,0.001,0.0001]
(2)批次大小batch_size
批次大小是每一次训练神经网络送入模型的样本数,在卷积神经网络中,大批次通常可使网络更快收敛,但由于内存资源的限制,批次过大可能会导致内存不够用或程序内核崩溃。bath_size通常取值为[16,32,64,128]
(3)优化器optimizer
目前Adam是快速收敛且常被使用的优化器。随机梯度下降(SGD)虽然收敛偏慢,但是加入动量Momentum可加快收敛,同时带动量的随机梯度下降算法有更好的最优解,即模型收敛后会有更高的准确性。通常若追求速度则用Adam更多。
(4)迭代次数
迭代次数是指整个训练集输入到神经网络进行训练的次数,当测试错误率和训练错误率相差较小时,可认为当前迭代次数合适;当测试错误率先变小后变大时则说明迭代次数过大了,需要减小迭代次数,否则容易出现过拟合。
(5)激活函数
在神经网络中,激活函数不是真的去激活什么,而是用激活函数给神经网络加入一些非线性因素,使得网络可以更好地解决较为复杂的问题。比如有些问题是线性可分的,而现实场景中更多问题不是线性可分的,若不使用激活函数则难以拟合非线性问题,测试时会有低准确率。所以激活函数主要是非线性的,如sigmoid、tanh、relu。sigmoid函数通常用于二分类,但要防止梯度消失,故适合浅层神经网络且需要配备较小的初始化权重,tanh函数具有中心对称性,适合于有对称性的二分类。在深度学习中,relu是使用最多的激活函数,简单又避免了梯度消失。
















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











