






@总结:关于c,c++ char,wchar_t,char16_t,char32_t与各种编码集的兼容
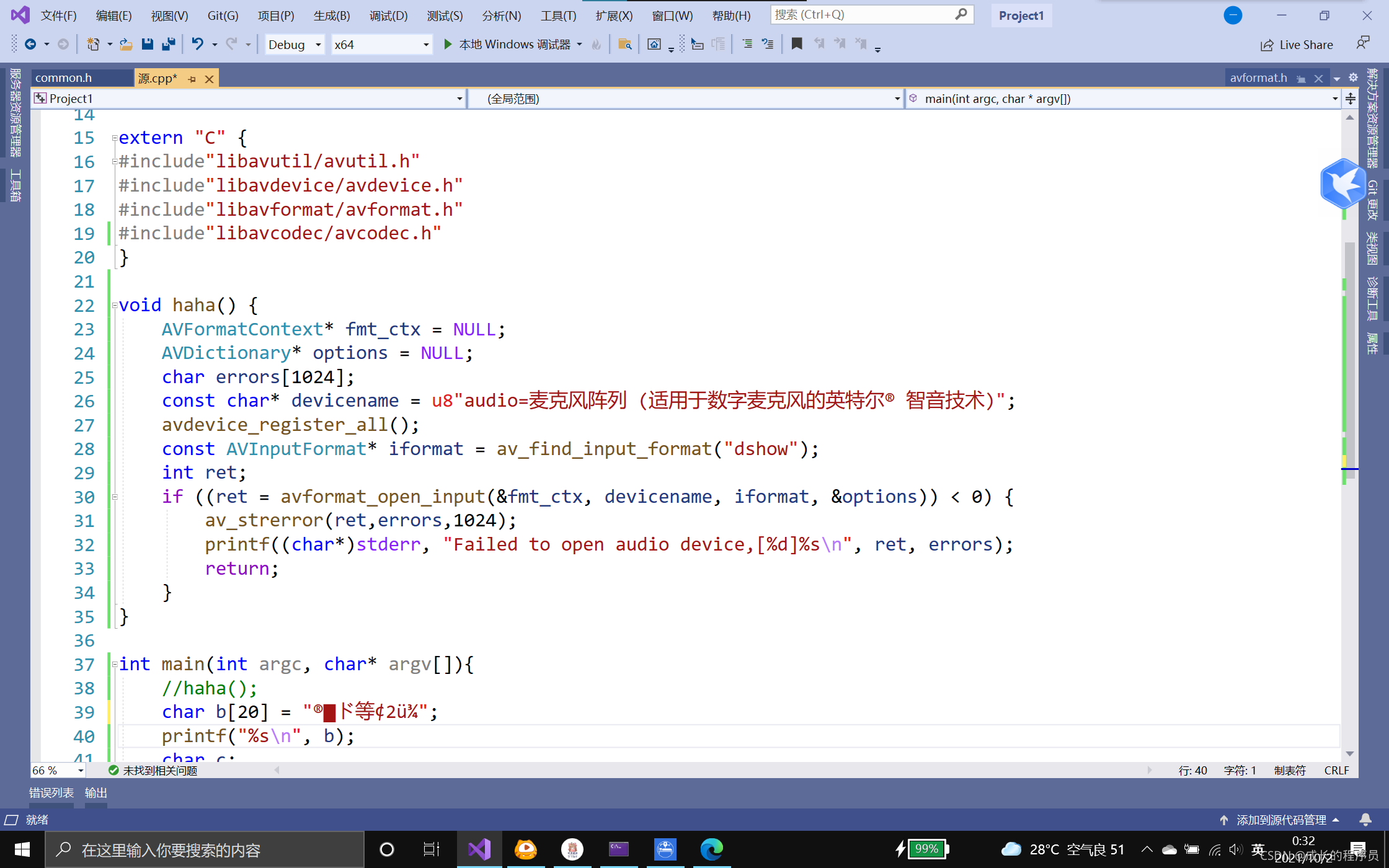
搞了很久,看编码集,总结网上,必须要加个u8才能保证数据不出错
最后,看了下网上讲这个很少,就随手发了个贴
大家好,之前一直遇到多次关于char存数据出现错误的问题,搞了很久,有点头绪,文章可能会有误,如果有错误,欢迎指正。
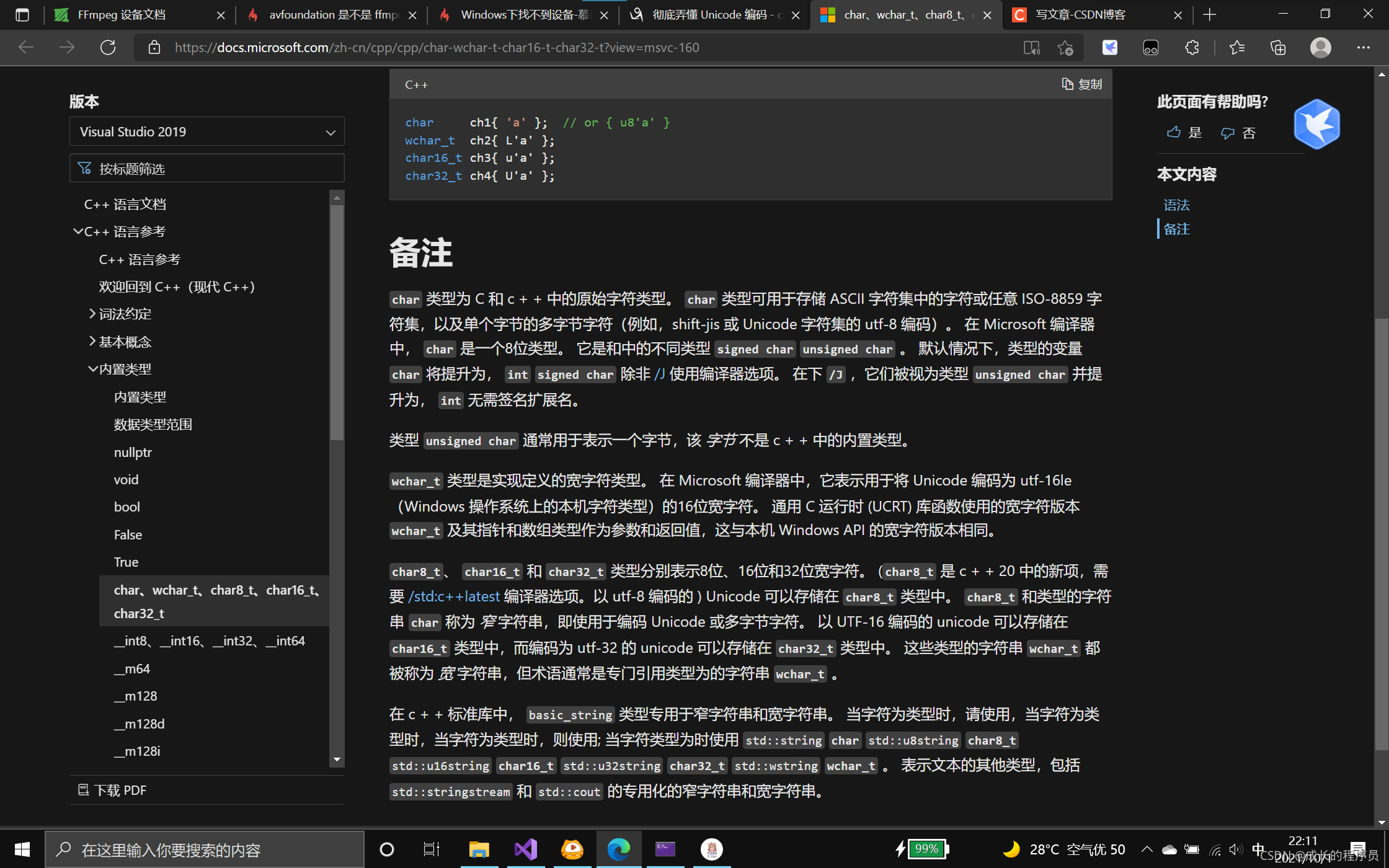
看官方文档:
char如果不能存ASCII,utf-8,iso等等字符编码集用一个字节表示的东西,就会出现?,其实语言里面这些内置字符类型,是里面有一种与字符集有相关性的的方法去表示这些字符,语言的内置类型与这些编码集有一种兼容性,比如前128与ASCII的兼容
我们先了解下"“字符串字面值的种类:

查阅书籍:
我推断出没有前缀的”"默认是一个字节存字符就是官网说的,能存那些编码集里面1个字节的,我在utf-8网页找了个其他国家的字符
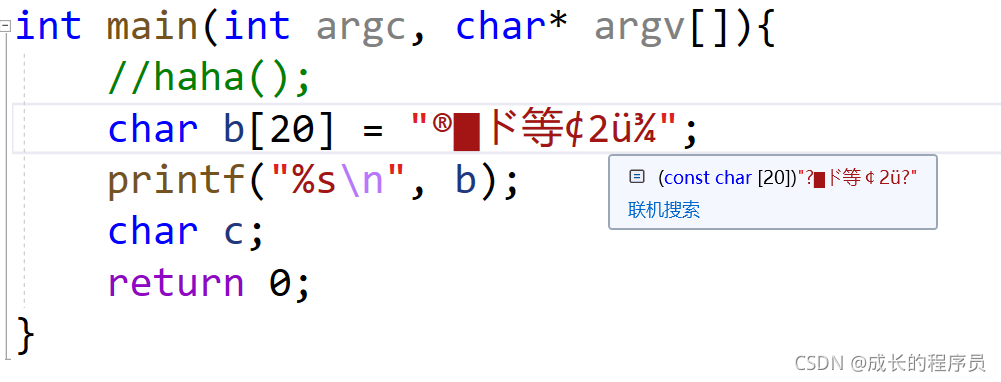
有没有发现,有两个不支持储存的
其他符合官网要求,能保证里面正确,不会截断
前缀u的是char16_t,U的是char32_t,u8的能表示utf-8的。我们使用char a[]=""时候最好要匹配,不能匹配的话只能尽量保证里面数据二进制内容不少
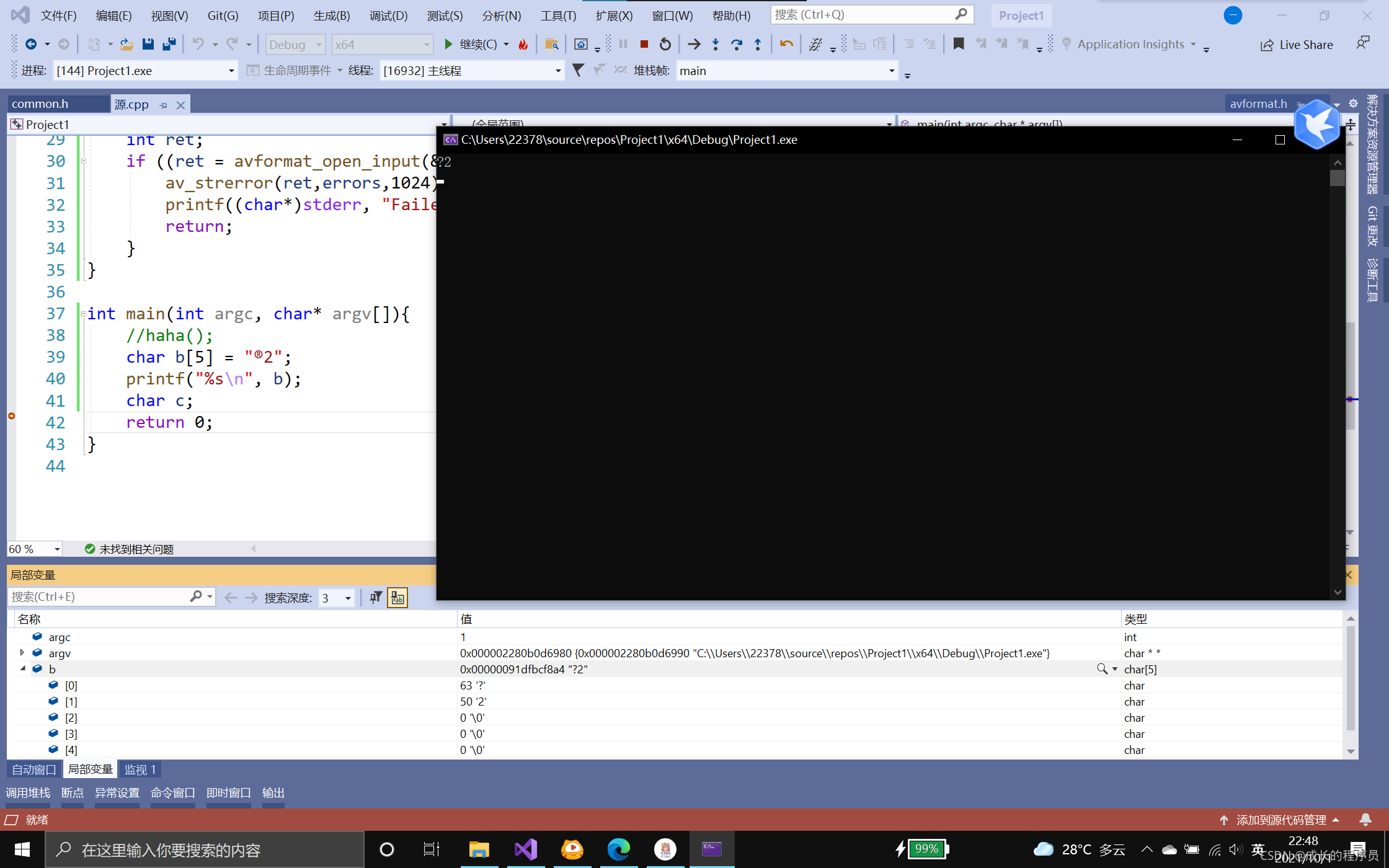
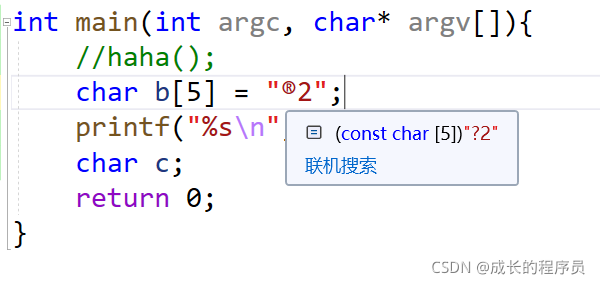
看,如果用这样去赋值,char[]数组每个位置存一个东西
这个错误的原因是因为“”里面是按一个字节存的,®存不了变成?
他只截取了®的前一个字节
导致赋值都不用看,已经错了
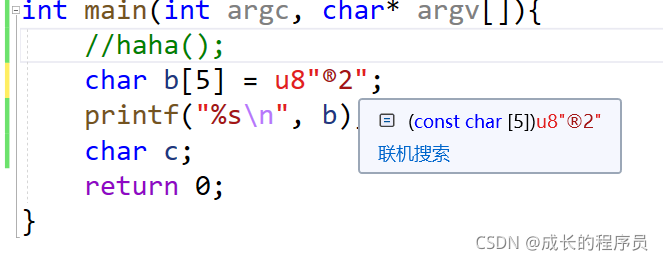
如果这样写前缀u8你看®用两个位置去存了,“”字符串字面值是不会出错了,打印的时候是因为编码问题,printf()按照什么去解析这个char[]。
总之:这样对我们保存数据是不会导致数据错误了
当字符串字面值没错的时候,赋值过去,编译器认识b数组是看每个字节来认识的,所以‘?’
然后为了避免这些问题,我总结了下,避免这些问题办法是,等价赋值,比如
wchar_t a[n]=L"daihi的傲" 这样去写
如果一定要使用char 就不能让""字符串字面值出错,里面字符要能够安装“”的能识别的编码集
对于上网,网页显示的默认编码集是GBK,我复制到记事本,要按照GBK编码集读取才不会错,有些软件很智能,能够识别我们复制的东西是什么编码集的,然后可能会转换为这个软件的默认读取方式(比如我设置VS2019是Unicode),这样就不会出错了。所以大家复制东西需要注意编码集问题
我们比较常用的还有wchar_t,语言规定用两个字节存,原理其实一样的:
下一个,其实我有个问题想不明白
翻阅网上文章
 char16_t的能用表示utf-16,如果一个字符是utf-16表示的,他是用4个字节表示的,怎么存进去char16_t ?
char16_t的能用表示utf-16,如果一个字符是utf-16表示的,他是用4个字节表示的,怎么存进去char16_t ?
这里楼主还是大二的菜鸡啊,语言内部的我们也不懂怎么实现的,但是只用知道char16_t能存utf-16的数据,如果去存4个字节的。
应该数据不会出错的















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











