







目录
前言
文章性质:学习笔记 📖
视频教程:FCN源码解析(Pytorch)- 1 代码的使用
主要内容:根据 视频教程 中提供的 FCN 源代码(PyTorch),对 train.py、transforms.py 和 train_and_eval.py 文件进行具体讲解。
Preparations

一、train.py
1、parse_args 相关参数
data-path 用于指定解压后 VOCdevkit 的路径,需将 default 改为 PASCAL VOC 的存放路径。
parser.add_argument("--data-path", default="/data/", help="VOCdevkit root")num_classes 指不包含背景的类别个数,例如 PASCAL VOC 包含 20 个类别。
parser.add_argument("--num-classes", default=20, type=int)aux 用于确定是否使用辅助分类器,即从 Layer3 引出的 FCN Head 结构,在 PyTorch 官方实现的 FCN 网络结构 中有讲。
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")device 用于选择训练使用的设备处理器,默认值为 cuda ,会自动去寻找电脑中的第 1 块 GPU 设备,若没有 GPU 设备则使用 CPU 。
parser.add_argument("--device", default="cuda", help="training device")batch-size 用于指定训练批量的大小,默认值为 4 ,根据 GPU 显存进行设置,若 GPU 显存很大则可以设置为 8 和 16 等。
parser.add_argument("-b", "--batch-size", default=4, type=int)epochs 用于指定训练数据的迭代轮数,默认设置为 30 。
parser.add_argument("--epochs", default=30, type=int, metavar="N", help="number of total epochs to train")lr 指初始学习率。
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')momentum 是优化器的超参数。
parser.add_argument('--momentum', default=0.9, type=float, metavar='M', help='momentum')weight-decay 是优化器的超参数。
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float, metavar='W',
help='weight decay (default: 1e-4)', dest='weight_decay')print-freq 用于控制打印的频率。
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')resume 用于确定是否进行断点续训,即在训练任务中断时,使用上次保存的权重文件继续训练,直至训练完成,无需从头训练。
parser.add_argument('--resume', default='', help='resume from checkpoint')start-epoch 从第几轮开始训练,默认从 0 开始。
parser.add_argument('--start-epoch', default=0, type=int, metavar='N', help='start epoch')amp 用于确定是否使用 PyTorch 的 torch.cuda.amp 模块来实现混合精度训练
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")2、SegmentationPresetTrain 类
SegmentationPresetTrain 类包含了 训练过程中采用的图像预处理方法 ,会传入 base_size、crop_size、水平翻转的概率 hflip_prob、做标准化处理的均值 mean、做标准化处理的标准差 std 等参数。
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
min_size = int(0.5 * base_size)
max_size = int(2.0 * base_size)
trans = [T.RandomResize(min_size, max_size)]
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
trans.extend([
T.RandomCrop(crop_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
self.transforms = T.Compose(trans)
def __call__(self, img, target):
return self.transforms(img, target)【代码解析】对 SegmentationPresetTrain 类代码的具体解析如下:
- 将 base_size 乘上 0.5 后取整得到 min_size 值,将 base_size 乘上 2.0 后取整得到 max_size 值
- 在 min_size 和 max_size 范围内随机取值,对图像进行等比例缩放,使最小边值为刚刚的随机值 [ 随机缩放 ]
- 若设置的 hflip_prob 大于 0 ,则会按照指定的 hflip_prob 对 image 与 target 进行随机的水平翻转 [ 水平翻转 ]
- 使用 RandomCrop 进行随机裁剪 [ 随机裁剪 ]
- 使用 ToTensor 将图片像素的数值从 0-255 缩放到 0-1 之间 [ 转化成 tensor 格式 ]
- 使用 Normalize 进行标准化处理:减去均值,除以标准差 [ 标准化处理 ]
- 使用 Compose 对 trans 中的预处理方法进行打包,赋给 transforms
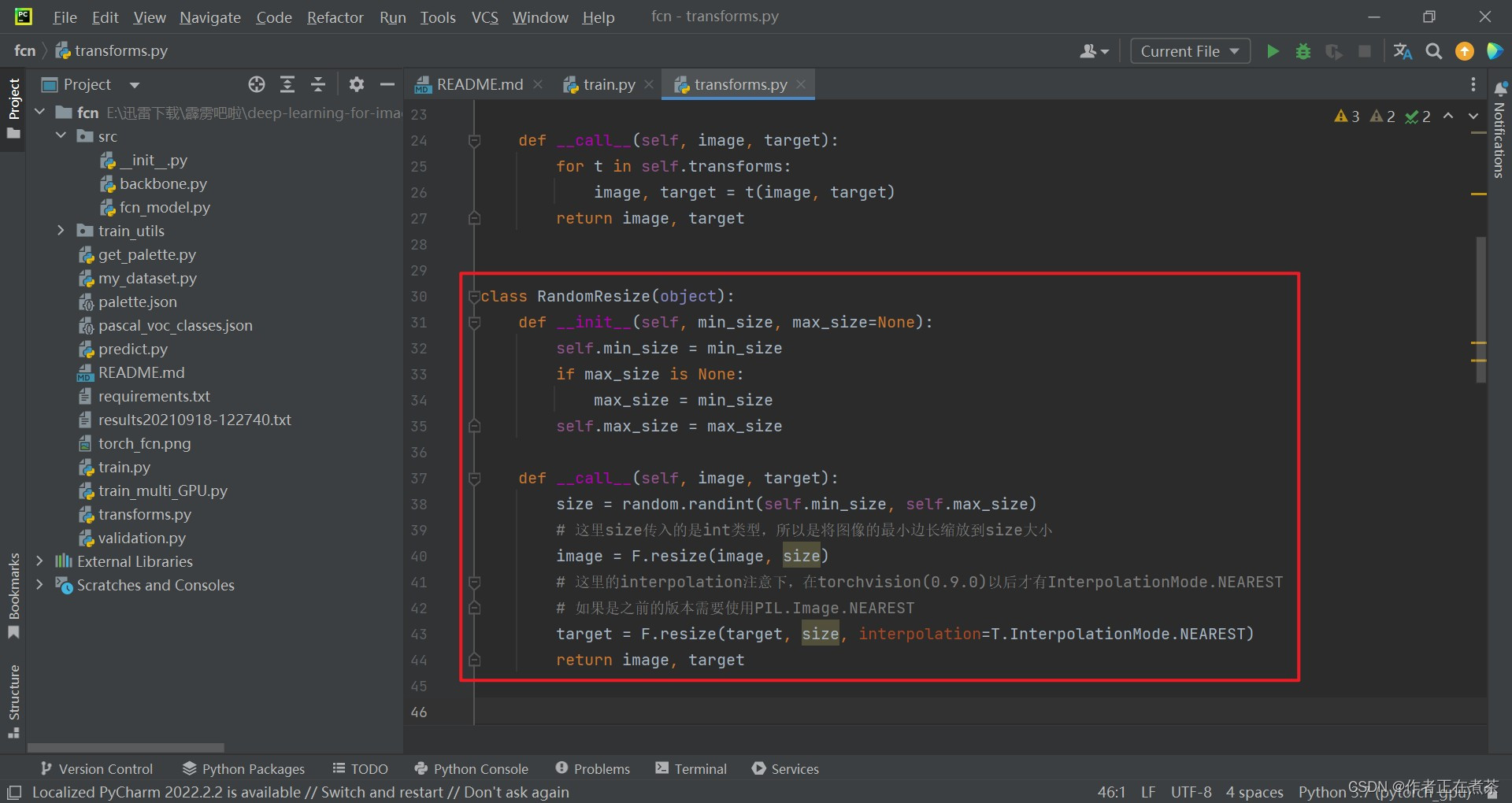
(1)随机缩放 RandomResize
随机缩放 RandomResize 类的相关代码截图:
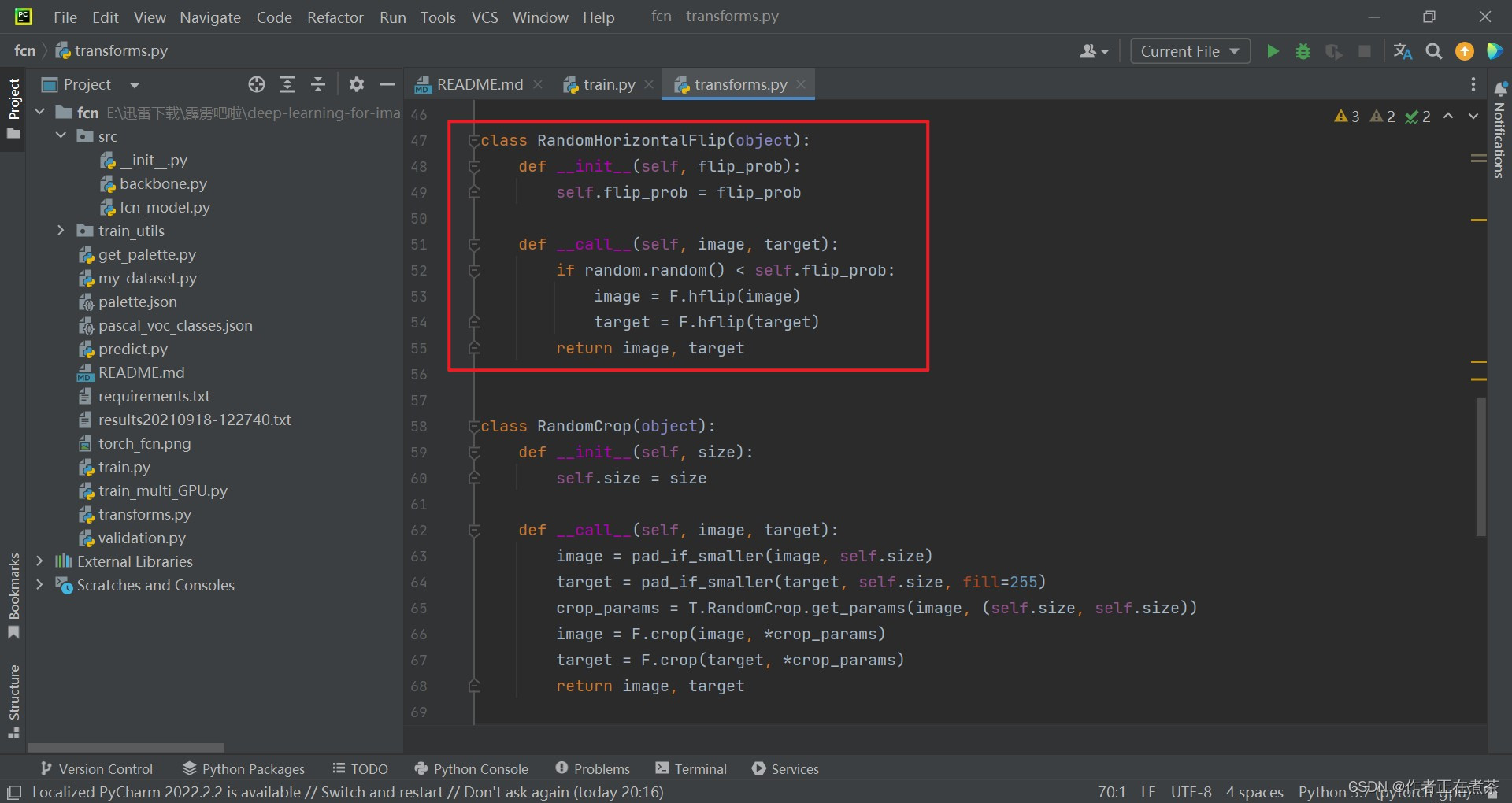
(2)水平翻转 RandomHorizontalFlip
水平翻转 RandomHorizontalFlip 类的相关代码截图:
(3)随机裁剪 RandomCrop
随机裁剪 RandomCrop 类的相关代码截图:
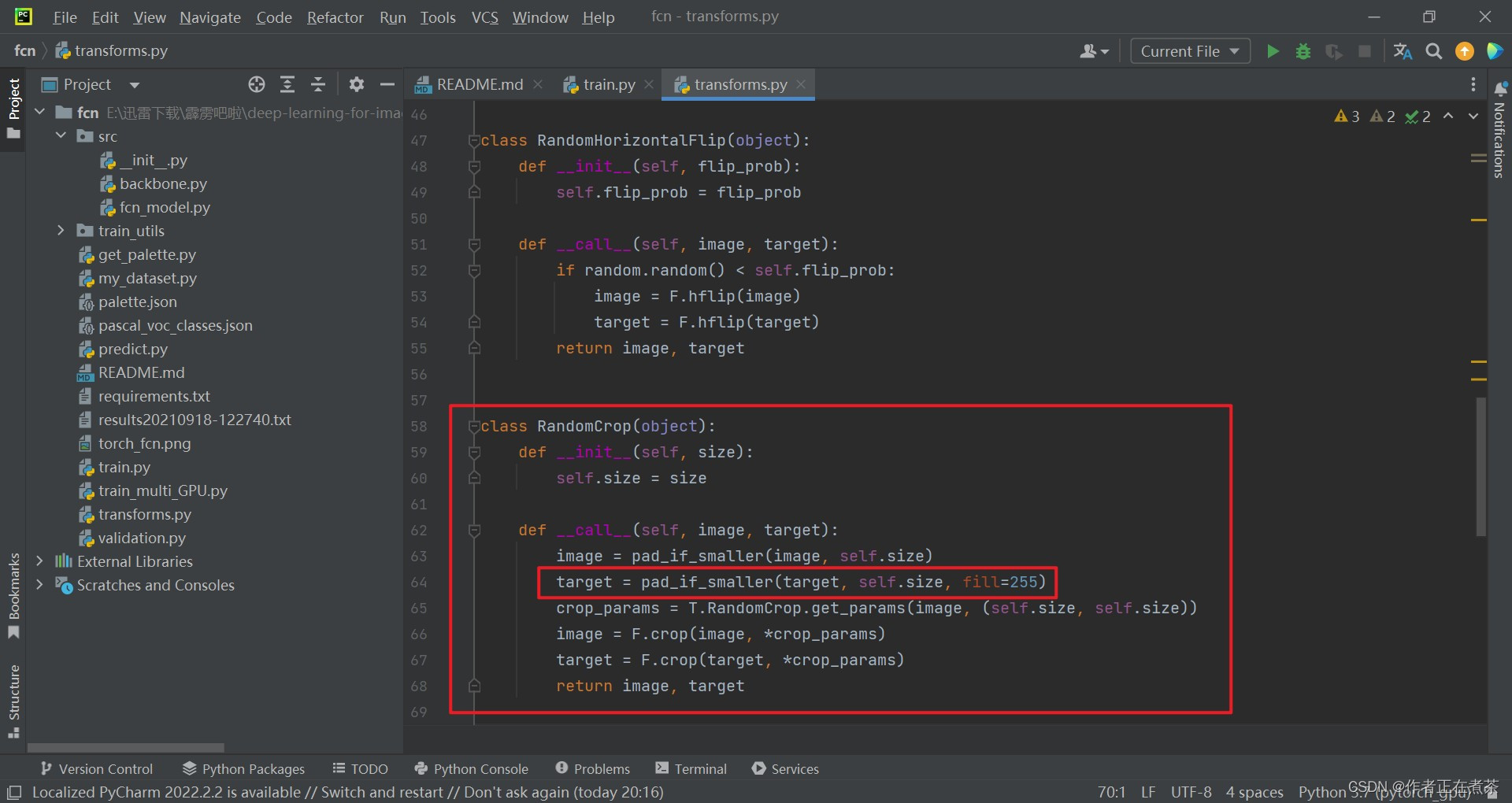
【说明】 填充的像素都是没有意义的,所以标签设置为 255 ,我们之前在讲语义分割前沿的时候说过,对于比较难分类的区域,会用 255 进行填充,后面计算损失时会忽略这些区域的损失。除此之外, pad_if_smaller 填充函数的代码截图如下:
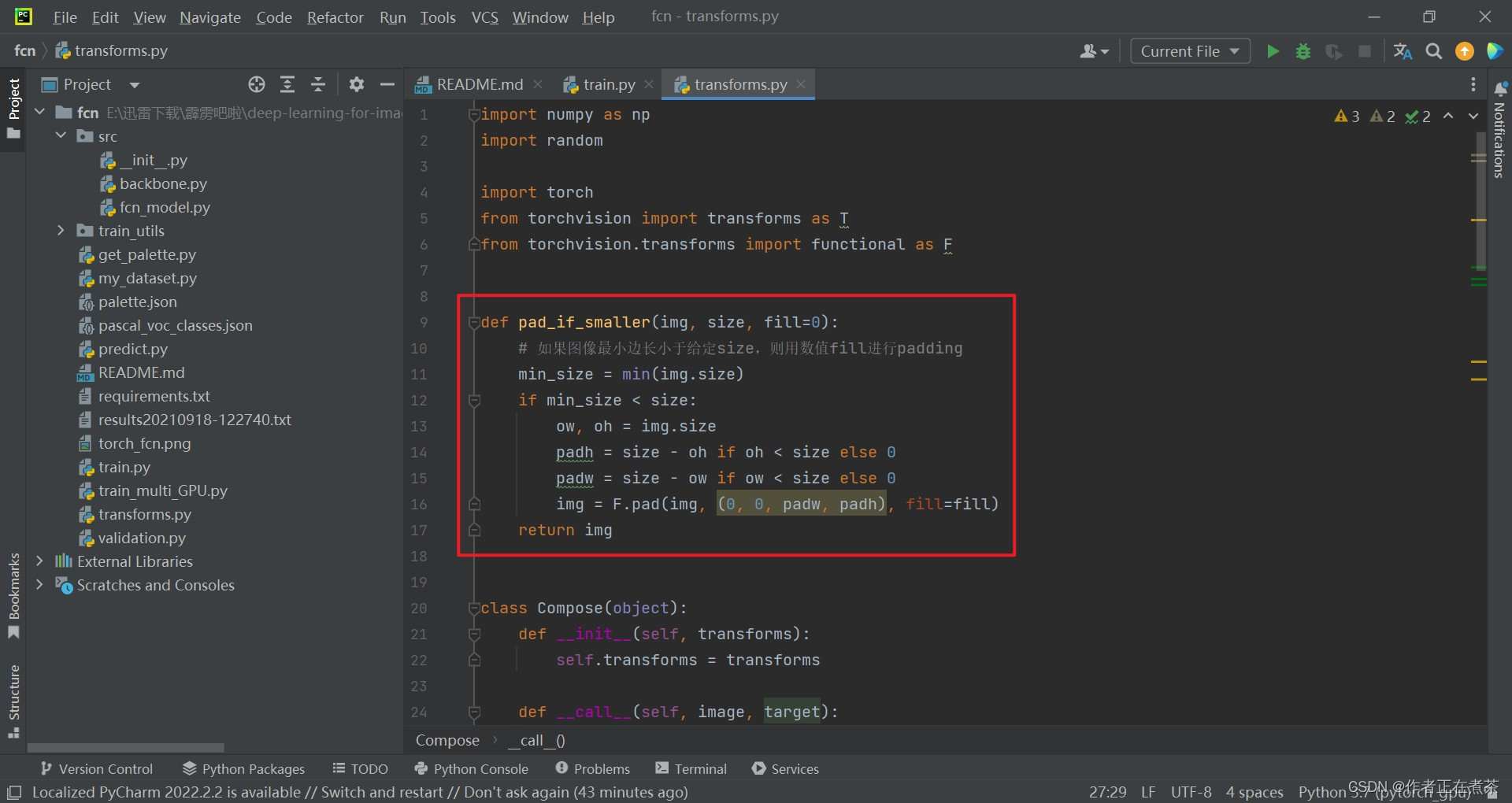
(4)类型转化 ToTensor
类型转化 ToTensor 类的相关代码截图:

【说明】使用官方的 to_tensor 方法将图片转化为 tensor 格式,
(5)标准化处理 Normalize
标准化处理 Normalize 类的相关代码截图:
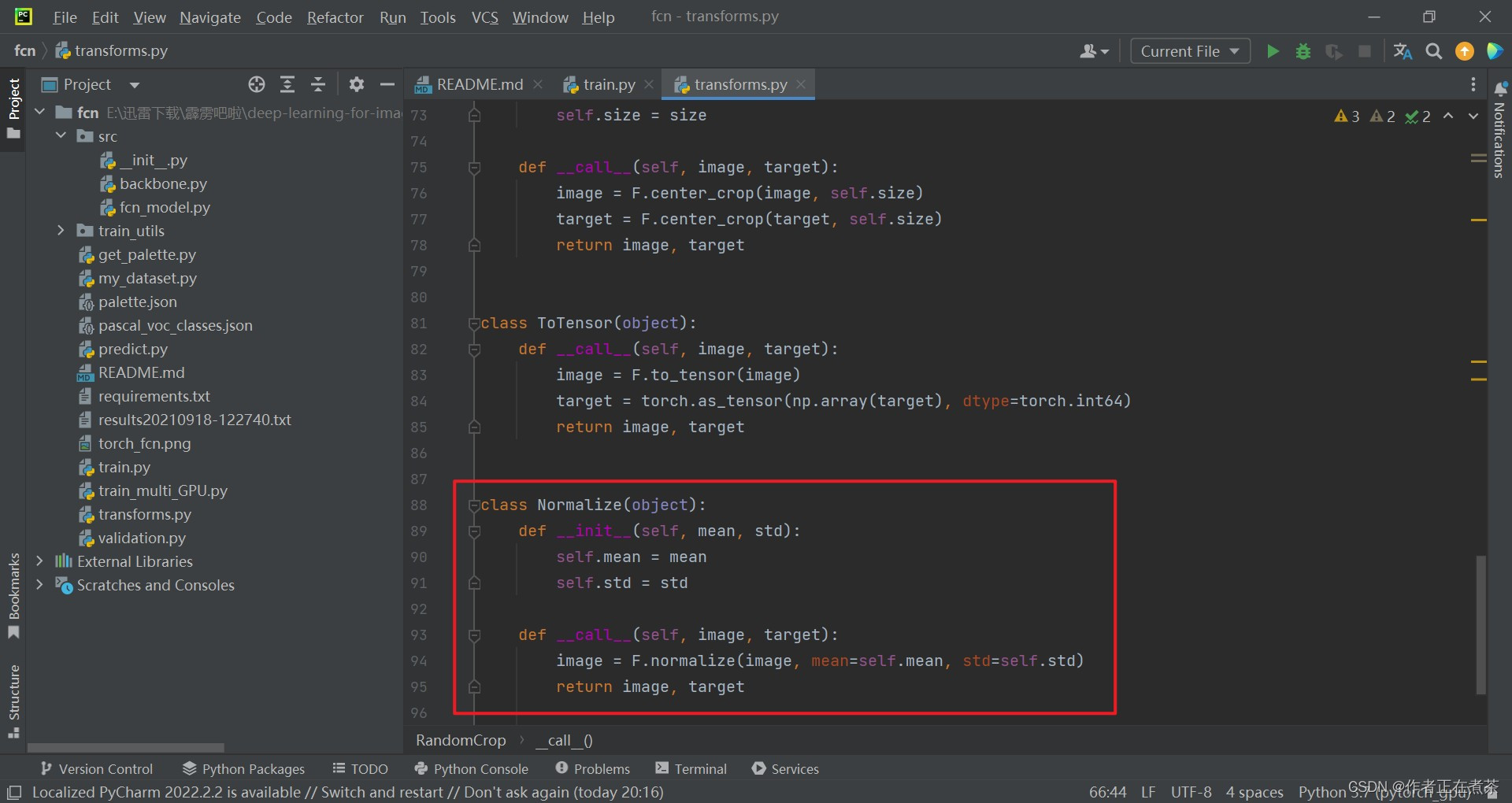
(6)transforms.py
【源码】上面用到的类与函数均取自 transforms.py 文件,我将代码贴在下方:
import numpy as np
import random
import torch
from torchvision import transforms as T
from torchvision.transforms import functional as F
def pad_if_smaller(img, size, fill=0):
# 如果图像最小边长小于给定size,则用数值fill进行padding
min_size = min(img.size)
if min_size < size:
ow, oh = img.size
padh = size - oh if oh < size else 0
padw = size - ow if ow < size else 0
img = F.pad(img, (0, 0, padw, padh), fill=fill)
return img
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class RandomResize(object):
def __init__(self, min_size, max_size=None):
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
size = random.randint(self.min_size, self.max_size)
# 这里size传入的是int类型,所以是将图像的最小边长缩放到size大小
image = F.resize(image, size)
# 这里的interpolation注意下,在torchvision(0.9.0)以后才有InterpolationMode.NEAREST
# 如果是之前的版本需要使用PIL.Image.NEAREST
target = F.resize(target, size, interpolation=T.InterpolationMode.NEAREST)
return image, target
class RandomHorizontalFlip(object):
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.hflip(image)
target = F.hflip(target)
return image, target
class RandomCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = pad_if_smaller(image, self.size)
target = pad_if_smaller(target, self.size, fill=255)
crop_params = T.RandomCrop.get_params(image, (self.size, self.size))
image = F.crop(image, *crop_params)
target = F.crop(target, *crop_params)
return image, target
class CenterCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = F.center_crop(image, self.size)
target = F.center_crop(target, self.size)
return image, target
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target3、SegmentationPresetEval 类
SegmentationPresetEval 类包含了 验证过程中采用的图像预处理方法 ,会传入 base_size、做标准化处理的均值 mean 和标准差 std 等参数。
【说明】使用到的类与函数都与 SegmentationPresetTrain 类中使用到的类与函数相似,需要注意的是,在做随机剪裁 RandomResize 时,采用的 min_size 和 max_size 都取值为 base_size 。
class SegmentationPresetEval:
def __init__(self, base_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.RandomResize(base_size, base_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)4、get_transform 函数
关于 get_transform 函数,传入参数 train ,将 base_size 设置为 520 ,将 crop_size 设置为 480 :
- 当传入的 train 参数为 True 时,调用 SegmentationPresetTrain 类,返回针对 训练集 的图像预处理方法
- 当传入的 train 参数为 False 时,调用 SegmentationPresetEval 类,返回针对 验证集 的图像预处理方法
def get_transform(train):
base_size = 520
crop_size = 480
return SegmentationPresetTrain(base_size, crop_size) if train else SegmentationPresetEval(base_size)5、create_model 函数
关于 create_model 函数,传入是否使用辅助分类器 aux、类别个数 num_classes 、pretrain 等参数。
def create_model(aux, num_classes, pretrain=True):
model = fcn_resnet50(aux=aux, num_classes=num_classes)
if pretrain:
weights_dict = torch.load("./fcn_resnet50_coco.pth", map_location='cpu')
if num_classes != 21:
# 官方提供的预训练权重是21类(包括背景)
# 如果训练自己的数据集,将和类别相关的权重删除,防止权重shape不一致报错
for k in list(weights_dict.keys()):
if "classifier.4" in k:
del weights_dict[k]
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
return model【代码解析】对 create_model 函数代码的具体解析如下:
- 采用 src / fcn_model.py 文件中的 fcn_resnet50 方法来搭建模型,传入 aux、num_classes 参数
- 采用 torch.load 方法将 fcn_resnet50_coco.pth 权重文件载入到 cpu 中,载入进来的权重是 字典 的形式
- 如果 num_classes 类别个数不是 21 的话,将把和类别相关的权重删除,即删除 classifier.4 中的权重
- 采用 model.load_state_dict 方法将权重载入到模型中,同时输出模型中未载入的权重和未使用的权重
微臣顺便将 rc / fcn_model.py 文件中的 fcn_resnet50 方法贴在下面啦:
def fcn_resnet50(aux, num_classes=21, pretrain_backbone=False):
# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'
# 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth'
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet50 backbone预训练权重
backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = FCNHead(out_inplanes, num_classes)
model = FCN(backbone, classifier, aux_classifier)
return model6、main 主函数
(1)main 整体讲解
main 主函数的代码截图与相关解析如下:
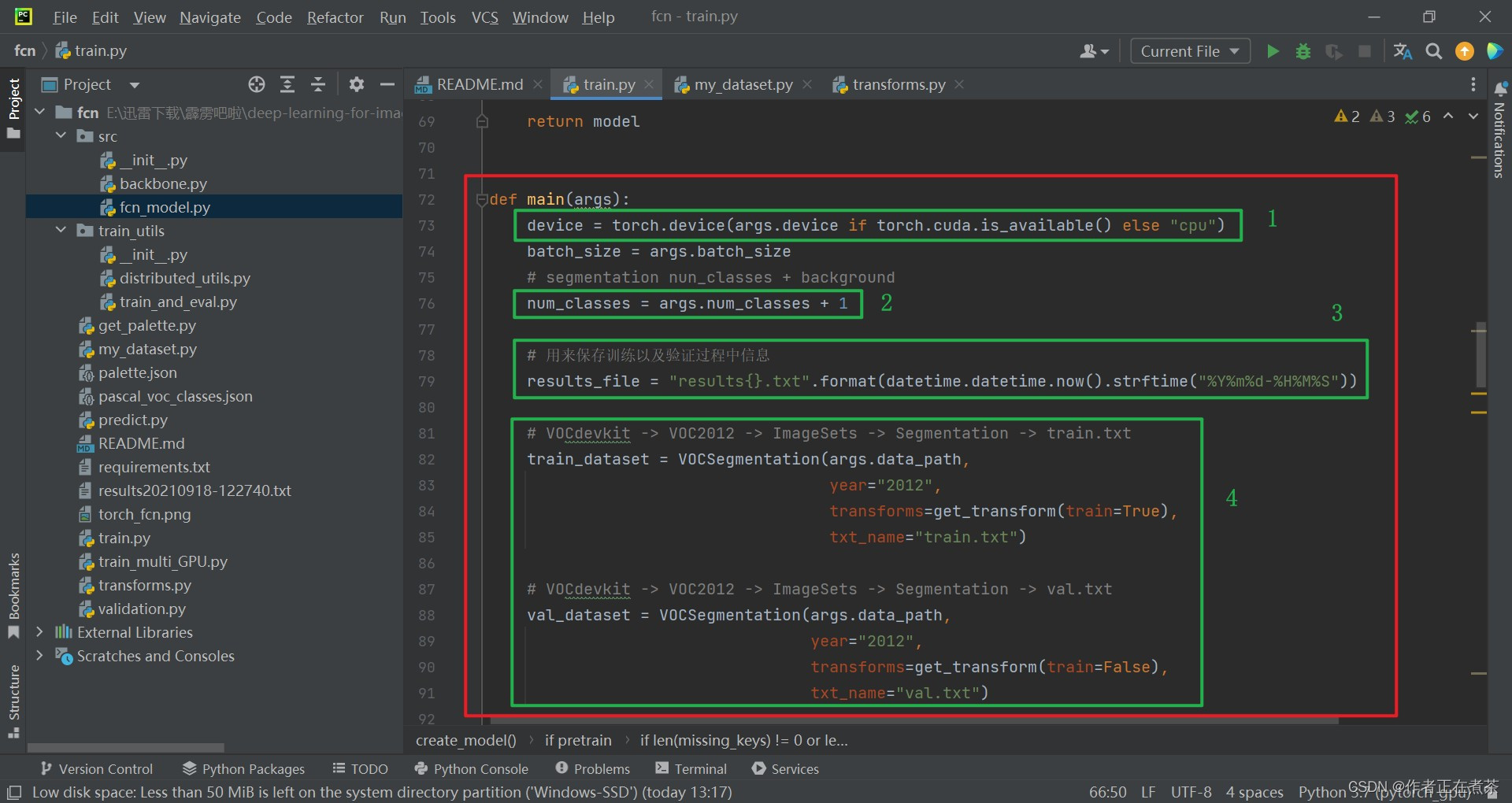
【代码解析1】对 main 函数代码的具体解析如下(结合上图):
- 使用 torch.cuda.is_available() 判断我们当前的 GPU 设备是否可用,若可用则默认使用第一块 GPU 设备,否则使用 CPU 设备
- 默认 num_classes 会加上 1 ,也就是加上背景类别
- 创建 results.txt 文件,用来保存训练以及验证过程中每个 epoch 的输出信息
- 调用 my_dataset.py 文件中的自定义数据集读取部分
【补充】关于上面第四条的补充说明:
- 关于训练数据集 train_dataset ,其 transforms 采用了 get_transform(train=True) ,在 train.txt 中记录了训练过程中使用的图片
- 关于验证数据集 val_dataset ,其 transforms 采用了 get_transform(train=False) ,在 val.txt 中记录了验证过程中使用的图片
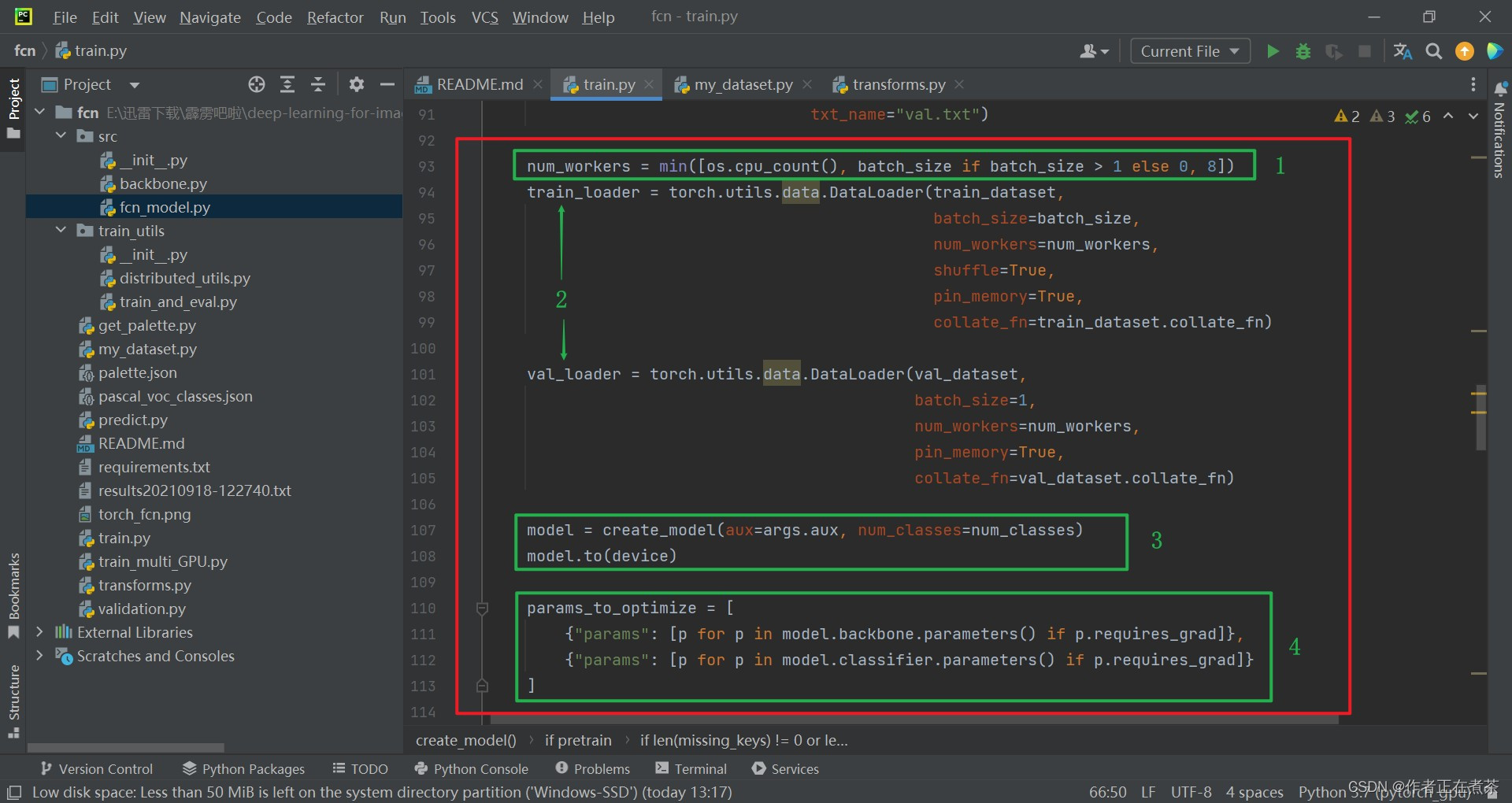
【代码解析2】对 main 函数代码的具体解析如下(结合上图):
- 设置 num_workers 值,在 GPU 的核数、max ( batch_size, 1 ) 和 8 中取最小值,赋给 num_workers
- 使用 torch.utils.data.DataLoader 分别载入训练数据集和验证数据集
- 调用 create_model 方法实例化模型,再将模型执行到对应的设备中
- 遍历 backbone 和 classifier 中的权重,将未冻结的权重提取出来,待会去训练这些权重
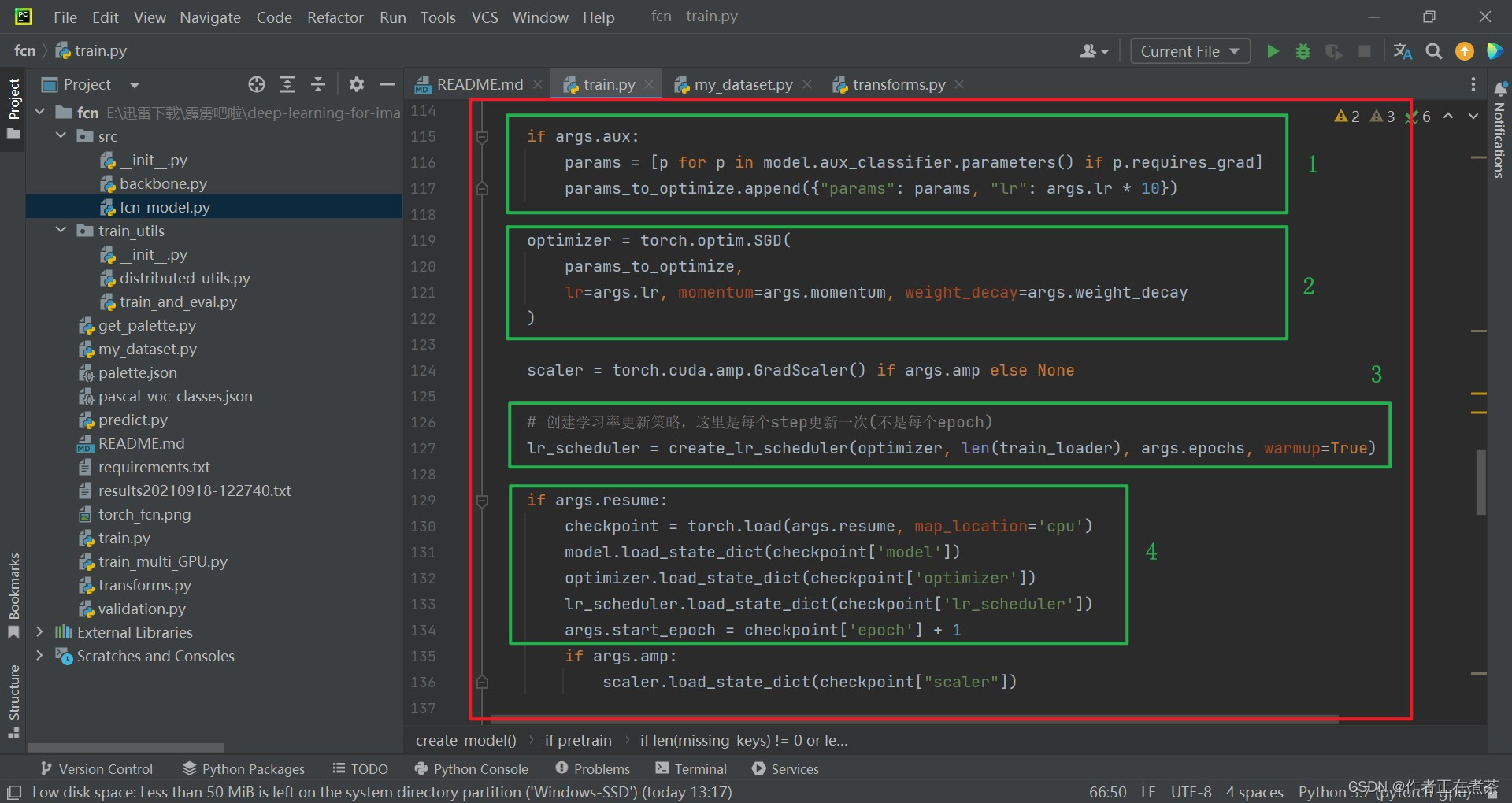
【代码解析3】对 main 函数代码的具体解析如下(结合上图):
- 如果使用辅助分类器的话,就将辅助分类器中未冻结的权重也提取出来,注意辅助分类器采用的学习率是初始学习率的 10 倍
- 定义优化器,采用 SGD ,传入我们要训练的参数,并设置初始学习率 lr、momentum、weight_decay 等
- 创建学习率更新策略,设置 warmup 为 True,从很小的学习率开始训练,慢慢增强到我们指定的初始化学习率,然后再慢慢下降
- 判断是否传入 resume 参数,如果是则载入最近一次保存的模型权重,然后去读取对应的模型权重、优化器数据、学习率更新策略
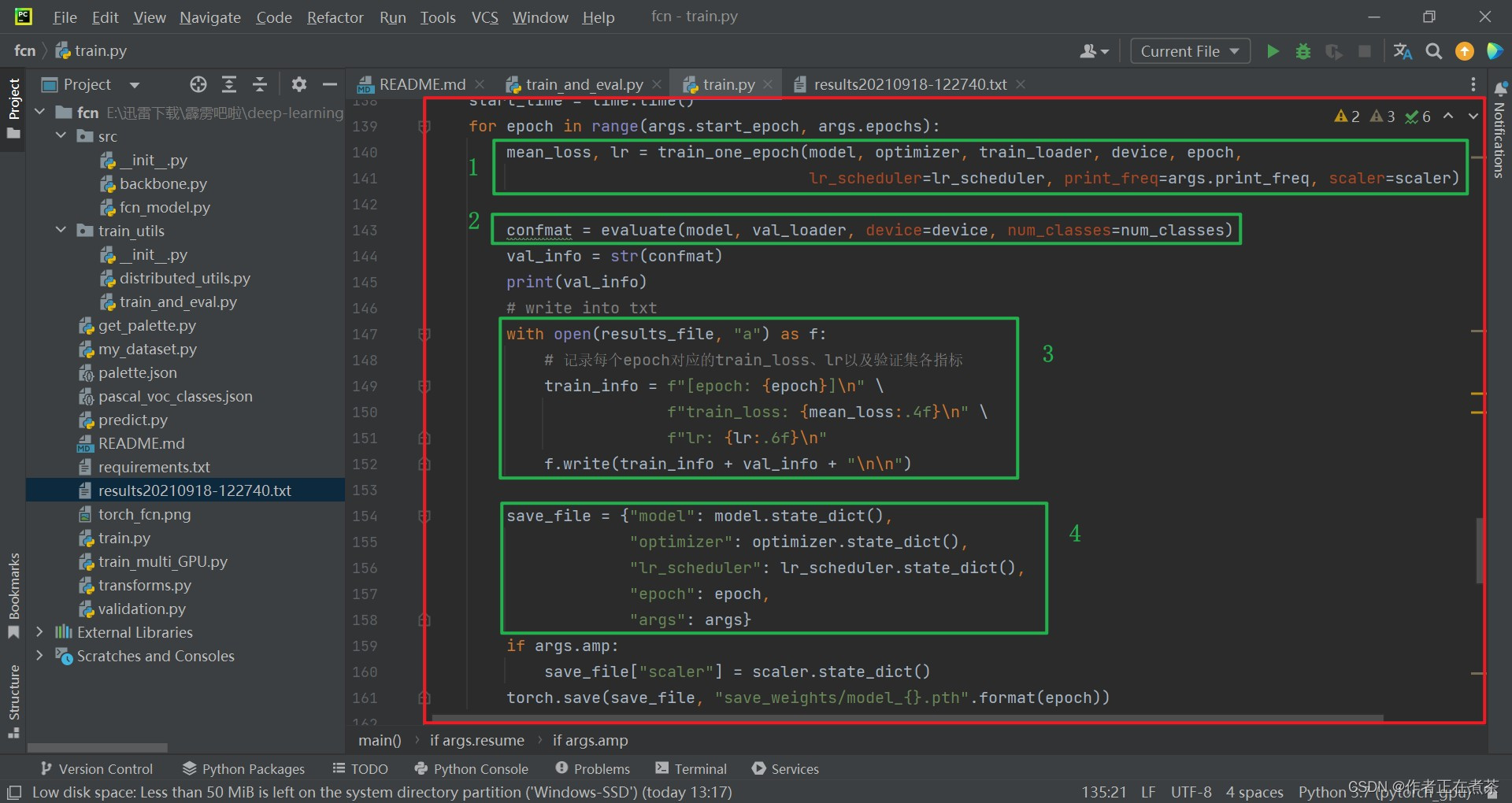
【代码解析4】对 main 函数代码的具体解析如下(结合上图):
- 这个 train_one_epoch 就是训练数据一轮的过程,可用 Ctrl + 左键 的方式点击查看该方法,具体讲解见(2)
- 这个 evaluate 就是验证数据的过程,可用 Ctrl + 左键 的方式点击查看该方法,具体讲解见(3)
- 打印 epoch 信息、训练过程的平均损失、学习率、训练的输出、验证的输出等,并记录到 results_file 中
- 保存 model 模型的参数、optimizer 优化器的参数、lr_scheduler 学习率更新策略的参数、epoch 和 args 等
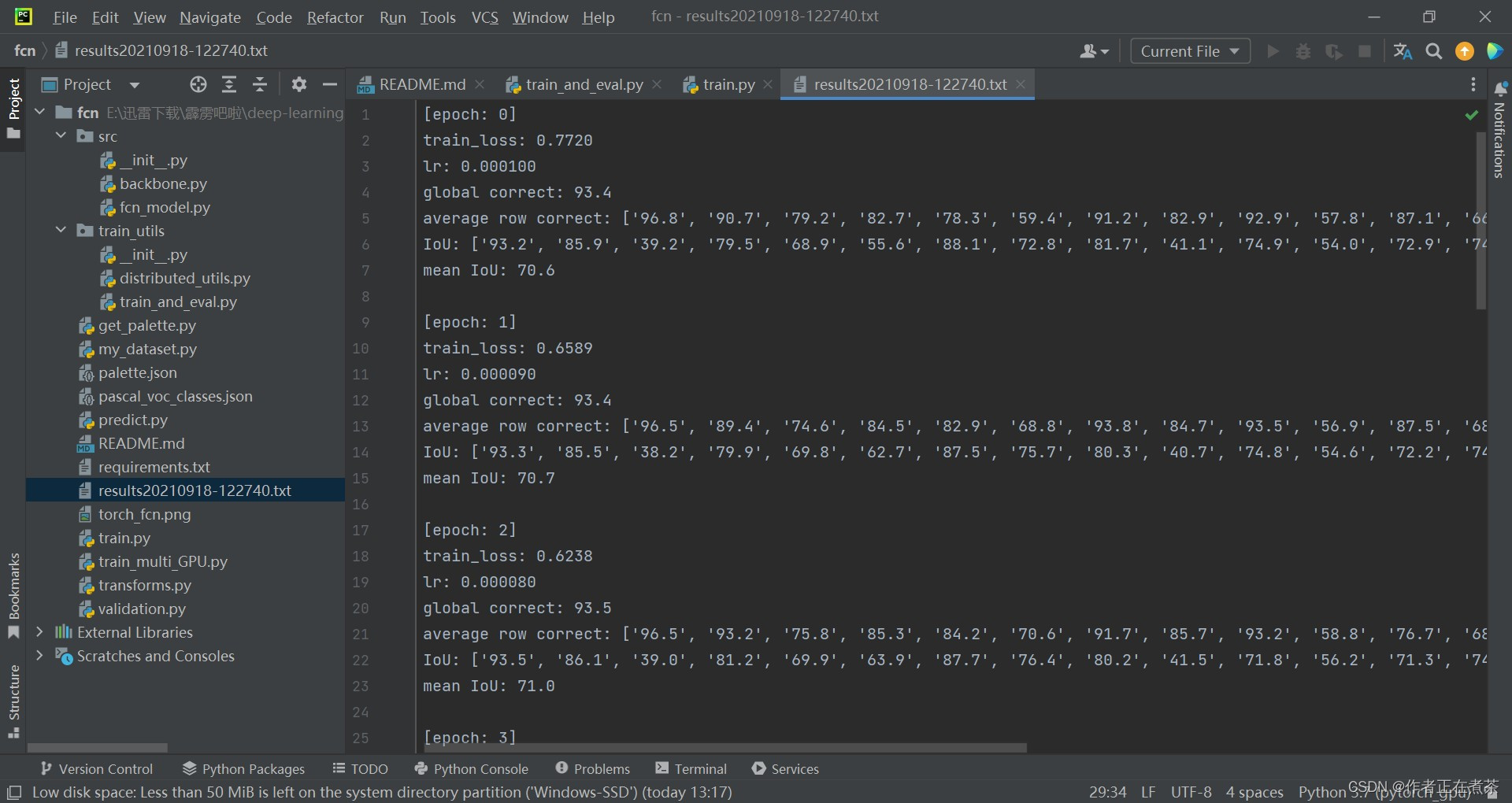
(2)train_one_epoch 训练函数讲解
在 train_and_val.py 文件中的 train_one_epoch 函数与 criterion 函数代码如下:
def criterion(inputs, target):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
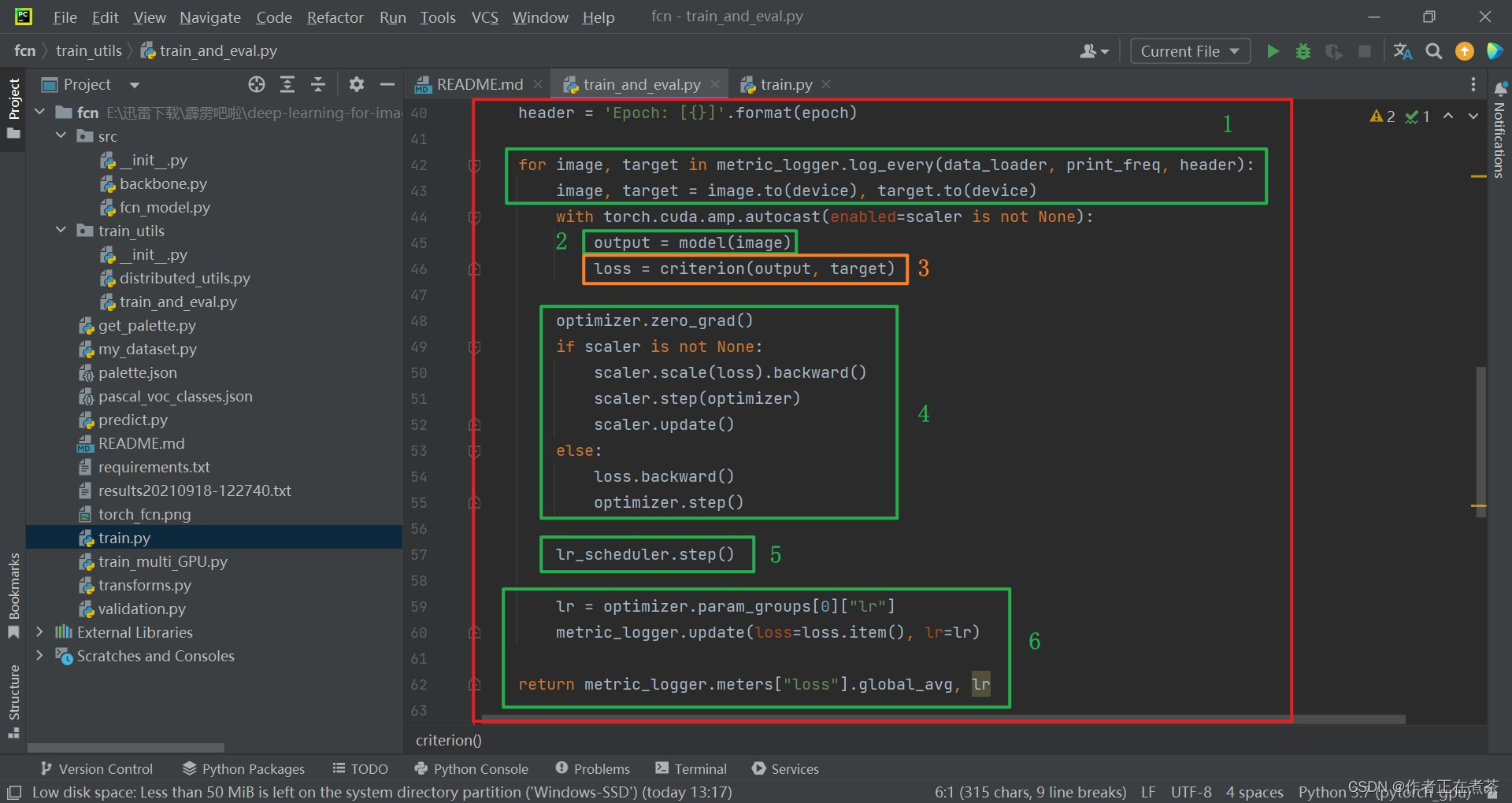
return metric_logger.meters["loss"].global_avg, lr【代码解析】对 train_one_epoch 函数代码的具体解析如下(结合下图):
- 使用 for 循环遍历 data_loader 得到 image 和 target 信息,并将其指给对应的设备当中
- 再将 image 图像输入到 model 模型中进行预测,得到 output 输出(字典形式)
- 调用 criterion 函数计算损失,根据代码可知,使用的是 nn.functional.cross_entropy 方法
- 清空 optimizer 优化器的历史梯度,将误差进行反向传播,再更新参数
- 调用 lr_scheduler 学习率更新策略来更新学习率,每迭代一次 step 就更新学习率(之前是每迭代一个 epoch 就更新学习率)
- 再将 lr 学习率提取出来,最终返回我们训练的平均损失和最后一个学习率
(3)evaluate 验证函数讲解
在 train_and_val.py 文件中的 evaluate 函数代码如下:
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
confmat.reduce_from_all_processes()
return confmat【代码解析】对 evaluate 函数代码的具体解析如下(结合下图):
- 创建 ConfusionMatrix 混淆矩阵
- 使用 for 循环遍历 data_loader 得到 image 和 target 信息,并将其指给对应的设备当中
- 再将 image 图像输入到 model 模型中进行预测,得到 output 输出(只使用主分支上的输出)
- 调用 update 方法时,在计算每一批数据预测结果与真实结果对比的过程中,将 target 和 output.argmax(1) 进行 flatten 处理
【注意】output.argmax(1) 中的 1 是指在 channel 维度,而 argmax 方法用于 将每个像素预测值最大的类别作为其预测类别 。

(4)train_and_eval.py
【源码】上面用到的类与函数均取自 train_and_eval.py 文件,我将代码贴在下方:
import torch
from torch import nn
import train_utils.distributed_utils as utils
def criterion(inputs, target):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
confmat.reduce_from_all_processes()
return confmat
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
return metric_logger.meters["loss"].global_avg, lr
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











