







3.6 排序算法
3.6.1 直接插入排序
●具体做法是:在插入第i个记录时,R1,R2,.....,Ri-1已经排好序,将记录Ri的关键字ki依次与关键字ki-1, ki-2,....,k1进行比较,从而找到Ri应该插入的位置,插入位置及其后的记录依次向后移动。

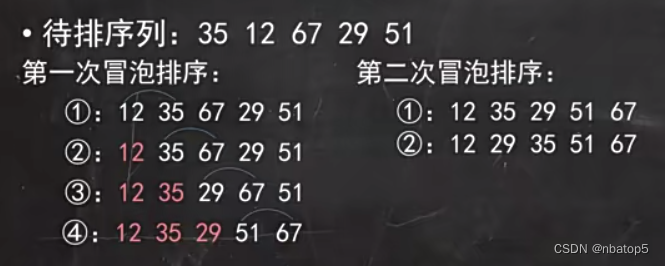
3.6.2 冒泡排序
首先将第一个记录的关 键字和第二个记录的关键字进行比较,若为逆序,则交换两个记录的值,然后比较第二个记录和第三个记录的关键字,依此类推。
3.6.3 简单选择排序
n个记录进行简单选择排序的基本方法是:
通过n-i次关键字之间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i (1≤i≤n) 个记录进行交换,当i等于n时所有记录有序排列。

3.6.4 希尔排序
希尔排序又称“缩小增量排序”,是对直接插入排序方法的改进。
先将整个待排记录序列分割成若干子序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
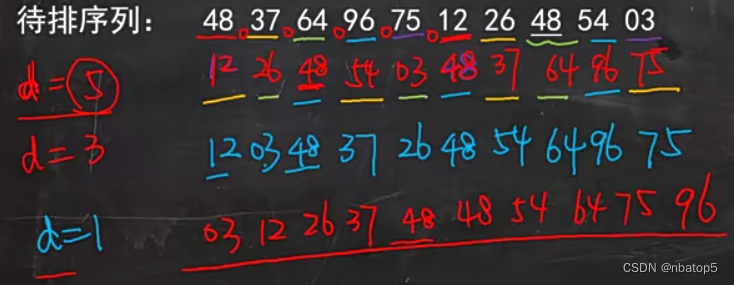
解释:如图,当d=5时,48和间隔为‘5’的12比较后互换位置(12<48),37和间隔为’5‘的26比较后互换位置,以此类推;然后令d=3,重复类似上述的操作,最后令d=1,相邻比较得到最终结果。
3.6.5 快速排序
过于复杂,考试有个印象就行,有兴趣可看
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









