







 本文详细介绍了如何在IBM SPSS Statistics中进行K均值聚类分析,包括数据准备、参数设置、结果解读等步骤,并强调了K均值聚类对连续型数据变量的依赖以及其对异常值的敏感性。
本文详细介绍了如何在IBM SPSS Statistics中进行K均值聚类分析,包括数据准备、参数设置、结果解读等步骤,并强调了K均值聚类对连续型数据变量的依赖以及其对异常值的敏感性。
IBM SPSS Statistics的K均值聚类分析,是一种采用欧式距离作为分类指标的迭代聚类分析方法。其优点是操作简单,运算速度快,但由于其聚类原理是将欧式距离相似的数据归为一个类别,因此需采用连续型的数据变量。
接下来,我们通过实例来演示一下K均值聚类分析。
一、数据准备
本例使用的是一组店铺的销售数据,包含客流量、销售额与销售量三个连续型变量。我们会使用到以上三个连续变量对数据个案进行K均值聚类分析。
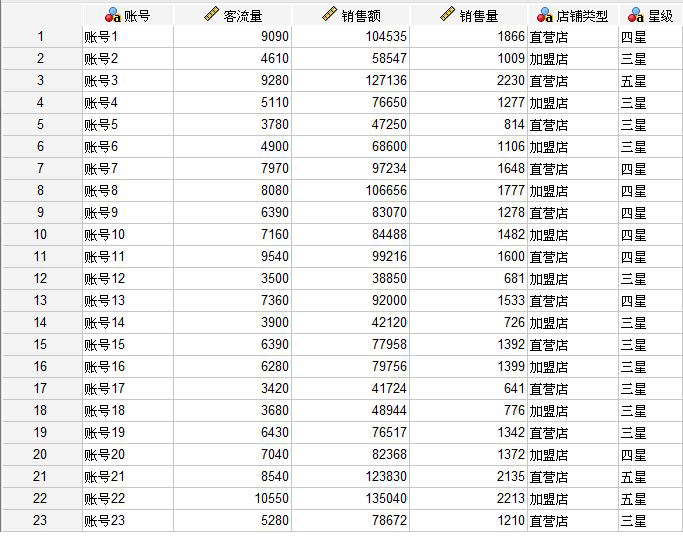
图1:店铺数据
二、K均值聚类参数设置
K均值聚类分析是SPSS分类分析法中的一种,由于其运算的快速性,也被称为“快速聚类”。
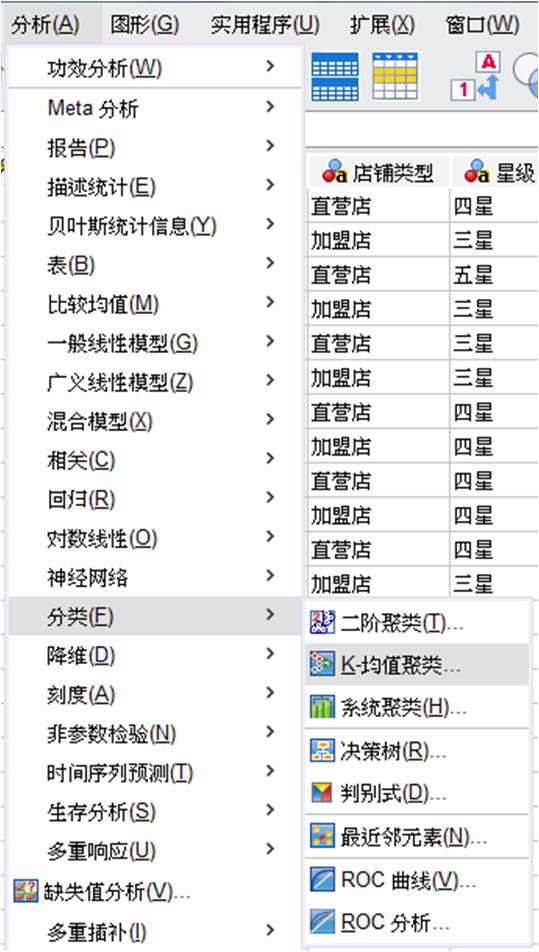
图2:K均值聚类
如图3所示,K均值聚类分析设置面板包含变量、聚类中心等设置参数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4052
4052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









