







——NeoZng[neozng1@hnu.edu.cn]
目录
如果觉得笔者写得还不错,点个赞加个关注吧!
Anchor-Free模型概览
我们在学习Faster R-CNN的时候第一次遇到anchor的概念,它利用anchor匹配正负样本,从而缩小搜索空间,更准确、简单地进行梯度回传,训练网络。但是anchor也会对网络的性能带来影响,如巡训练匹配时较高的开销、有许多超参数需要人为尝试调节等。而anchor-free模型则摒弃或是绕开了锚的概念,用更加精简的方式来确定正负样本,同时达到甚至超越了两阶段anchor-based的模型精度,并拥有更快的速度。这也让one-stage和two-stage的边缘更加模糊。接下来就让我们介绍几个非常经典的anchor-free模型:
-
FCOS
FCOS的全称是fully convulsion one-stage object detector。全卷积网络常用在目标分割任务,最早由FCN引入检测领域。FCOS匹配正负样本的方法别具一格,它直接将backbone输出的feature map上的每一个像素当作预测起点(当然输出的feature map和原图有一个映射的对应关系,本质上并没有将图像上的每一个点当成参考点,而是类似yolo,散布了一组格点),即把每一个位置都当作训练样本,只要该位置落入某一个GT框,就将其当作正样本进行训练。同时为了让一个目标不在多个feature map上被重复输出(推理时),FCOS人为限制了每一层回归目标的尺度大小,超过该限制的目标,这一层就不检测。

FCOS的结构
为了删去低质量的预测框,FCOS还在检测头增加另一个中心度分支,保证回归框的中心和GT较为接近。同时和FPN结合,在每一层上只回归特定大小的目标,从而将不同尺度的目标分配到对应层级上。
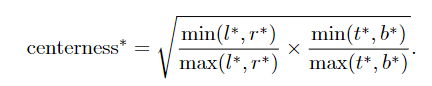
centerness的计算公式,设置中心度阈值从而保证生成的预测框中心接近GT
可以发现,虽然不再显式的使用anchor对正负样本进行匹配,但是仍然加入了一些预定规则来给参考点分配标签,之前的anchor是anchor box,在某种程度上我们可以将FCOS中的回归位置看作是anchor point,或者步长和边长相等的一组正方形anchor box。
-
CenterNet
CenterNet比FCOS更近一步,其论文的名字就叫做Object as points:将目标看作点。它直接在BackBone后接Conv层,输出一个代表物体中心点的Heatmap,在预测时取该Heatmp的topk作为可能的物体中心,再进入接下来的回归和分类分支,回归分支输出的是预测框相对于中心的offsets(width、height两个值或left、right、bottom、top四个值)。

CenterNet的预测示意图
其匹配正负样本的方法自然和预测一样,取GT的中点作为正样本。不过仅仅去中点一个点那是在是太少了,网络可能都不会收敛或是被负样本的梯度淹没。因此以GT中点为Gaussian中心,生成一个“正样本分布”,在此分布范围内的points都会得到正样本的监督信号,只不过离中点越近,one-hot label的值越大(就是将GT的标签乘上一个gaussian权重,也可以看作距离衰减因子)。

来自论文原文,GT中点附近会有一个衰减的惩罚,从而间接地增加正样本数量
虽然CenterNet的论文提到这是一个真正无anchor的网络,然而,我们鸡蛋里挑骨头看看,生成的中心点heatmap在位置上其实和原图也有对应关系,和FCOS一样是原图上的密集网格(网格密度由center heatmap的大小决定)。
-
CornerNet
CornerNet和CenterNet有异曲同工之妙,两兄弟的论文题目也稍稍互动了一下,这篇叫:Objects as paired points。

CornerNet的pipline,通过预测top-left和bottom-right角点得到检测框
CornerNet通过预测物体的左上和右下角点的heatmap得到预测框。这里其实有两种方式,一种是只预测检测框,不管里面是社么物体,随后再在每一个检测框上运行分类网络;另一种则是直接为每个分类预测左上和右下两组heatmap,直接得到类别和定位,这也是CornerNet的做法(说不定你用第一种方法试试,也能发篇paper)

CornerNet的架构
CornerNet使用Hourglass作为backbone(是一个常用于姿态估计和关键点检测的backbone),在其后接上两组角点的预测分支,其中每一个分支内又分为三个分支,分别是角点heatmap、角点embedding和角点offset分支。
前述cornerNet为每一个类别预测两组heatmap,因此总共需要预测c组热图,开销还是比较大的。论文还提出了一种用于聚合特征的CornerPooling:

Corner Pooling的示意图
corner pooling将会对topleft角点的同一列的下方和同一行的右侧进行channel-wise的max pooling操作,对于bottom-right角点则是同列上方和同行左侧。从直觉上理解,一个物体的外接矩形必然在边框上和物体有相接的地方,从这些地方提取出的特征就能被Corner Pooling很好地捕捉到:

字如其名,角点embedding将计算每个角点的嵌入,以得到最小距离为目标进行训练就能匹配成对的左上和右下角点。
offsets则输出角点的偏移量,用于获取更精确的定位(heamap的分辨率没有原图高,因此需要offset分支来修正角点位置,可以看作一种插值手段)。
-
ExtremeNet
ExtremeNet师从前两个检测网络,同样是通过预测特征极值点的方式来检测物体。通过预测五组极值点的heatmap并使用center grouping的方式将这些极值点分组从而形成检测框。下面这张图阐释了ExtremeNet的检测思路:

也可以称这些极值点为极大的边缘响应
ExtremeNet匹配四个极值点一组的方法是暴力搜索(复杂度为O(n^4),原文提到有方法可以将复杂度降低到O(n^2),其中n为生成的heatmap的WxH),取每个heatmap的topk,四个一组进行遍历组合,若这一组极值点生成的检测框的中心附近恰好对应着预测的center heatmap上的一个极值点,就把他们作为一个检测目标输出。
整个网络的架构如下图所示,同样使用了特征点检测常用的backbone hourglass:

在骨干网路后紧跟着9个分支,分别检测上下左右和他们对应的修正偏移量,以及物体中心的heatmap。可想而知,这个检测网络的速度不会太快。由于物体的外界矩形边界上可能存在多个极值点,或者这一条边恰好和物体的一条边重合,那极值点就可能会出现连成一条线的情况,因此论文中提出了一种Edge aggregation的方法。其实和soft-NMS差不多(NMS则是直接去除分数不是最高的检测框),又和CornerNet的corner pooling有相似之处,它会对每一行列都进行aggregation,若一个极值点附近有其他极值点,直接降低其附近极值点的score。当然,你也可以在检测框生成以后进行NMS,两者的开销比较如何,需要自己计算一下。
和前面两个网络一样,训练的时候用L1 smooth来作为损失函数计算预测框的损失即可。
经过一些修改,这个网路可以比较轻松地扩展到分割任务上,方法就是多预测几个极值点,然后用这些点连接成地多边形来近似一个分割mask,以下不同颜色的多边形是用于分割的结果,白色半透明的bbox是外接检测框:

那么这回,你觉得ExtremeNet是否是真正的anchor-free?似乎它也只是换了一种方式回归bbox,却巧妙地避开了anchor匹配的问题,其实换一种思路,生成四个角点的heatmap然后匹配bbox,这不就是最常见的anchor-based方法嘛。
-
FSAF
FSAF(feature select anchor-free )则是的思想也非常的巧妙,可以看作是一个anchor-free和anchor-based网络的结合,其整体架构如下:

图中省略了backbone,原文选用的是ResNet-50
之前的FPN的每一层输出都会接到一个检测头上,常规的检测头都有两个分支:分类和回归。传统的网络为GT选择特征层对进行回归的方法是根据GT box的大小,大目标会被分配到高层,小目标则分配到底层,“大”和“小”的定义都是需要人为设定的超参数,人为设计的规则一定是最好的吗?要怎么样分配最合适的特征层去检测对应的目标?
基于这个问题,在训练时,FSAF让FPN中输出的不同特征层上的anchor-free分支先进行检测,然后输出得到loss,再使用loss最小的那个特征层的anchor-based分支进行回归和分类。这样就做到了自适应的尺度大小分配。
-
ATSS
这个方法的全称是Adaptive training sample selection,基本可以说是一统anchor江湖的天下,人家直接通过严密的消融实验告诉你,anchor不anchor无所谓,关键是怎么分配正负样本并采用最好的特征图检测目标!前者也就是后来所说的标签分配问题。
原文对比了两个one-stage检测器,分别是上面介绍的FCOS(anchor-free)和RetinaNet(anchor-based,focal loss),通过控制变量法在MS COCO上验证,得出了不论从从reference point(FCOS)还是anchor box(RetinaNet)开始检测和回归,产生的差异都不大的结论。

RetinaNet在把FCOS用到的buff都叠完了以后,就只有0.8AP的差距了
他们的差异只在于如何定义正负样本:FCOS把落入GT内的参考点都当作正样本并限制不同层回归最大目标的尺度,而RetinaNet还是采用的IOU方法:

两者确定正样本的方法的图示
对于(a),FPN2上布置的一个anchor和GT有最大的IOU因此选择pyramid level2上中心位置的anchor作为正样本;对于(b),每一层上都有数个点(grid)落入GT中,但是FCOS对每一层检测的目标尺度大小有限制,level 1超出了尺寸限制故最终选择Pyramid level 2 来学习此GT。

RetinaNet从anchor box开始回归,预测值是四个offsets;FCOS从点开始回归,预测的是点到四边的距离
因此,作者认为定义更合适的正负样本,如何让对应的拥有最好特征的特征层后接的检测头进行其检测才是问题所在。
前述的FSAF在一定程度上解决了不同尺度目标检测的问题,但是同层的不同的anchor box的长宽比和大小、数量全部是需要设置的超参数,即使用聚类、差分进化或dynamic anchor,也只是尽量取平均值,不能达到最好的效果。
在经过了前面一大段的铺垫后,作者提出自适应的样本选择方法ATSS,对于每个GT,在FPN的每一层上选择距离GT中心距离最小topk个anchor boxes(有几层就有几*k个,而且前面的实验已经得出了anchor不anchor无所谓作者为了方便说明就沿用了anchor的概念)。计算这些anchors与GT的IOU均值 μ 和 标准差 σ,然后选定那些和GT的IOU大于 μ+σ 的anchor(高子里面再拔高子!)作为正样本(同时保证这些点是在GT框内的),剩下的都是负样本。如果一个anchor在上述计算下被划入多个GT,就选择IOU最高的那个。
通过这种方法,就不用设置各种超参数,唯一的参数就是topk的k。经过实验确定,在大于7的情况下也是鲁棒的(用大数定律就能很好地解释,太小的值不能反映其分布特性)。对于不同的anchor大小(其实也就是分割网格的大小),经过实验验证也是稳定的,而且发现即使使用多组不同形状和大小的anchor对于回归和分类也没有帮助。
都说这篇文章的ablation做的特别扎实,行文流畅条理清晰,颇有终结anchor之争的意味。强烈推荐阅读: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (arxiv.org)














 1367
1367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









