






就在上周,OpenAI 又在 AI 湖面抛下一块大石,激起了千层浪:全新一代旗舰生成模型 GPT-4o 登场了。从现场演示来看,它与人类进行了一轮轮无缝衔接的对话,丝滑得就像真人,不仅响应时间极短,还能识别人类语气,幽默地接住一个个梗,实现了令人惊艳的体验飞跃。

01 大模型走向高实时互动
RTC 技术大有可为
在 GPT-4o 诞生之前,我们当然也可以通过语音与 ChatGPT 交谈,不过对话延迟非常感人。
GPT-3.5 给出回应的延迟约为 2.8 秒,GPT-4 延迟则为 5.4 秒,这期间经历了三个过程:通过一个简单的模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并处理输出文本,再通过另一个模型将文本转换成音频输出。

GPT-4o诞生前 音频处理流程示意
多道转化处理工序,不仅意味着久到离谱的延迟,也意味着大量信息的丢失,GPT 无法直接获取信息,自然也无法通过转化后的文本观察说话人的语调和情绪。
而在即时反应、语言理解等方面,GPT-4o 取得了突破性进展,它是一款真正的多模态大模型,能够实时对音频、视觉和文本进行演绎推理,所有的输入和输出都由同一个神经网络处理,对音频输入做出反应的时间平均为 320 毫秒,几乎与人类对话无异。

GPT-4o的音频处理流程示意
OpenAI 作为如今全球 AI 发展的领头羊,一举一动都有着技术风向标的意义。GPT-4o 在实时交互能力上的长足进步,意味着实时多模态将成为大模型进化的新方向。
为了在全球范围内实现尽可能快的响应速度,除了大模型本身的迭代升级外,提供语音/图像低延时传输能力的 RTC 技术至关重要,因此在此次迭代中,OpenAI 还首次接入了 RTC SDK。
02 RTC如何发挥优势
让大模型变得更实时?
如何充分发挥 RTC 技术优势,让大模型变得更实时的呢?
在发布会的现场演示环节,GPT-4o 扮演了一次“在线导师”的角色,用户打开摄像头将手写的方程式录制下来,它就能快速鼓励和引导用户完成解题,这就得益于 GPT-4o 实时视频输入和识别的能力。
在 GPT-4o 之前,这类语音识别、音频处理或生成的应用,通常是在终端采集音频后,直接将原始裸数据发送给大模型。这个过程中,首当其冲要克服的就是延迟问题。
一般情况下延迟主要来自两个方面:数据量大带来的延迟、边缘网络接入问题造成的延迟。
● 数据量大带来的延迟:视频文件的原始数据远比文本/音频文件更大,举例来说,一帧 720p 的 RGB 图像大小就达到了 2.7MB 左右,若不经过压缩处理很难在互联网上传输,大文件传输造成的延迟不可忽略。
● 边缘网络接入问题造成的延迟:用户边缘终端与大模型机房的物理距离可能非常远。例如:亚洲用户访问 GPT-4o 可能需要跨越半个地球进行数据传输,很难保证可靠性和实时性。
而在接入 RTC 技术后,GPT-4o 延迟问题迎刃而解,通过在终端设备上对音视频进行编码压缩来降低传输数据量,同时通过 QoS 和就近接入来解决边缘网络问题,将音视频跨国传输降低到 300ms 内,为大模型打造更极致的交互体验,达成如真人对话似的效果。
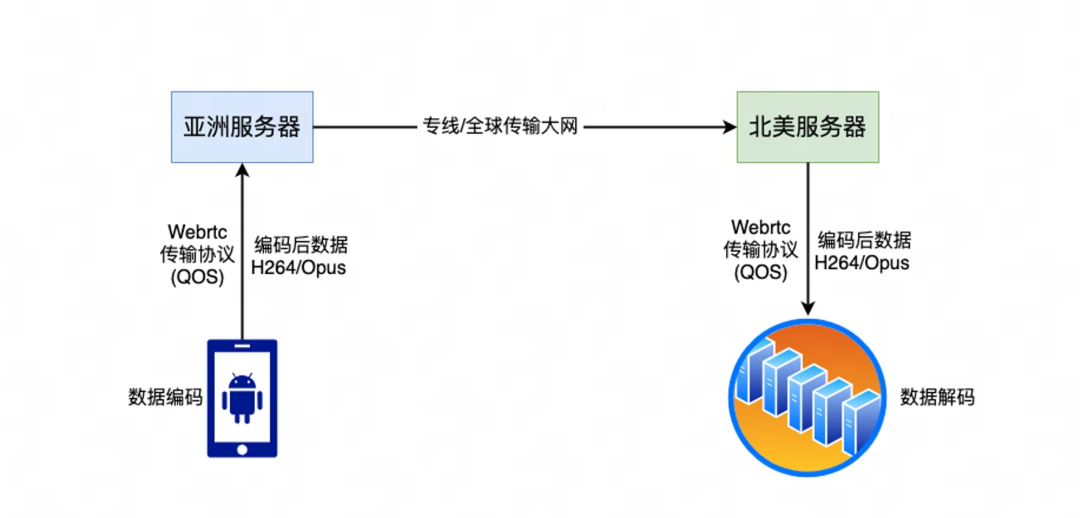
03 大模型实时化
打开更广阔的场景想象空间
在场景落地方面,更实时的大模型有着更广阔的想象空间。
例如:搭载 GPT-4o 的游戏内 NPC 具备了强大的理解能力,能自主生成音频对话内容,懂玩家意图、跟玩家互动、与玩家合作,甚至建立深度的人机社交关系,带来沉浸式的游戏体验;
实时交互的大模型能成为很好的口语老师,语音教学的同时给予即时反馈;
在电商大促时期,具备甜妹人声的 AI 客服能解答消费者的疑问,也能抚平消费者处理售后问题时的烦躁。
甚至具备更强的社会和公益价值。谷歌曾经展示过 AI 在帮助弱视人群方面的能力。我们都喜欢用自拍模式记录生活日常,这个看似简单的动作对于弱视人士来说却很难,受限于视力障碍,他们难以看清自拍时画面中的一切。Google Pixel 手机上的引导框功能能知晓画面内容,并结合音频提示、触觉反馈等帮助盲人和低视力人群完成自拍和合影。
Google AI 帮助弱视人士记录美好生活
若将 GPT-4o 融入该场景,相信它的实时视频输入和识别能力会为视障人士带来更好的体验,让不幸的人也能记录下美好生活片段。
04 网易云信 RTC
助力 AI 未来场景实现
网易云信是全球领先的融合通信云服务提供商,提供包括实时音视频、即时通讯、短信服务在内的全方位解决方案,RTC 服务以其稳定性和安全性,赢得了各行业头部企业的信任。
在超低延时传输方面,目前多数 AI 能力实现依赖于云端的 GPU 算力,为了优化端到端的用户体验,利用 RTC 的低延时特性可以显著提升全链路 AI 应用的效果的核心能力,尤其是在需要快速响应的应用场景中。网易云信 RTC 自研了低延时传输协议和全链路智能 QoS 传输算法,依托 WE-CAN 全球智能路由网络,最终实现了极致的端到端 300ms 延时。
为了实现实时的语音和视频交互,丰富易用的云端媒体处理 Pipeline 也是非常核心的能力。网易云信的云端 MPS(Media Process Server)服务将传输、解码、处理(包括AI处理)、编码、转推等全链路都做标准 Pipeline,并且各个模块都是可插拔的,能够非常好地将各类 AI 处理嵌入到音视频流的获取和生成流程中。

MPS AI 处理 Pipeline 示意图
AI 是一柄锋利的双刃剑,在带来体验革新的同时,并存着诸多的技术应用风险。聚焦到音频生成、视频生成以及实时通话、直播等场景,比较突出的问题在于版权问题、隐私安全、伦理道德等方面,此外视频换脸、语音模拟、不当使用造成的个人隐私泄露、身份欺诈、虚假和有害信息传播等风险,也在 AI 加持下被显著放大。
在这方面,网易云信联合网易易盾推出一站式安全检测方案——安全通,为 IM、RTC 和直播点播提供完备的 AIGC 内容安全解决方案。同时提供声音伪造、视频伪造检测等防御性识别能力,确保创作的内容不被用于有害或非法目的。
除此之外,目前云信已在网易内部内测基于大模型的一站式音视频解决方案,包括了多项云端 AI 能力,例如:AI 语音助手、实时字幕、实时摘要、通话高光时刻总结等等,很快我们将对外开放这些能力。当然,除了基于网易自研的云端 AI 能力,我们也在研发与各大模型厂商构建方便易用的 AI Agent 通用架构,并基于此帮助企业快速构建低延时、高清的 AI 音视频产品应用。
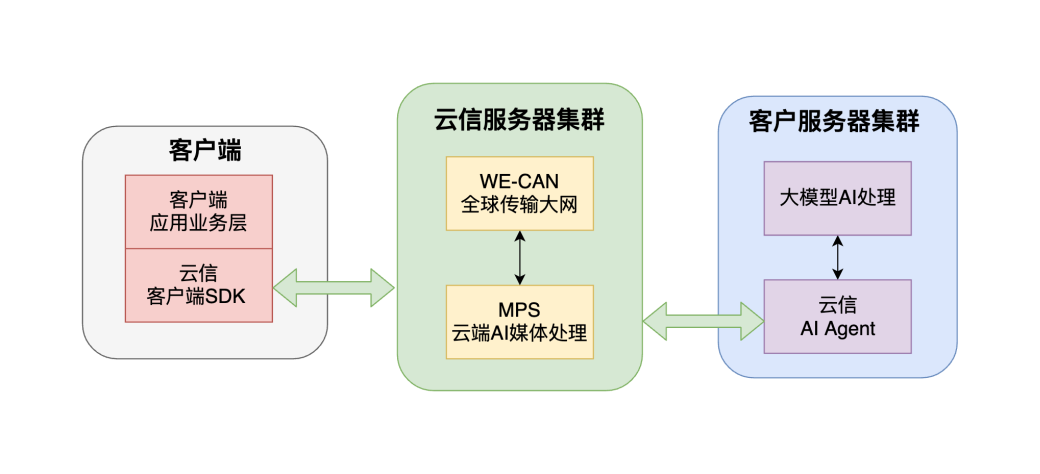
云信 AI Agent 示意图
关于我们


干货资料 免费领取
【扫描二维码】即可免费领取!





















 6180
6180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









