







Language
Overview
cucu is a toy compiler for a toy language. This language come from C, which is close to ANSI C. So, ecvery valid cucu program could be compiled with a C compiler without any errors.
For example, here’s a valid cucu code snippet:
int main(char *s)
{
int i = 0;
while(s[i]){
i = i+1;
}
return i;
}Grammar
Word
identifier:
which is composed by characters 、digits and _. such as i , j.keyWords include:
int 、main、char、while、return、if、elsepartions:
- operatornal characters: +、-、*、/
- other:
1.注释符:/* ..... */
2.逻辑运算和位运算符:>、<、==、>=、<=、!、&、|
3.其它:, ; ( ) * [ ]- const:
just for int 、 char 、 string( char *)
statement
the structure of a simple program : function declaration 、 function definitions
function definitions including : variable declaration 、expressions and so on
- funtion declaration and function definitions:
<var-decl> ::= <type> <ident> ";"
<func-decl> ::= <type> <ident> "(" <func-args> ")" ";"
<func-def> ::= <type> <ident> "(" <func-args> ")" <func-body>
<func-args> ::= { <type> <ident> "," }
<type> ::= "int" | "char *"- in the function definitions are some statements and expressions, follows are the forms of declarations:
/* These are simple statements */
i = 2 + 3; /* assignment statement */
my_func(i); /* function call statement */
return i; /* return statement */
/* These are compound statements */
if (x > 0) { .. } else { .. }
while (x > 0) { .. grammar
in a word , we can consider the program to be a regression expression. So we can do derivation using following rulers:
<func-body> ::= <statement>
<statement> ::= "{" { <statement> } "}" /* block statement */
| [<type>] <ident> [ "=" <expr> ] ";" /* assignment */
| "return" <expr> ";"
| "if" "(" <expr> ")" <statement> [ "else" <statement> ]
| "while" "(" <expr> ")" <statement>
| <expr> ";"
<expr> ::= <bitwise-expr>
| <bitwise-expr> = <expr>
<bitwise-expr> ::= <eq-expr>
| <bitwise-expr> & <eq-expr>
| <bitwise-expr> | <eq-expr>
<eq-expr> ::= <rel-expr>
| <eq-expr> == <rel-expr>
| <eq-expr> != <rel-expr>
<rel-expr> ::= <shift-expr>
| <rel-expr> < <shift-expr>
<shift-expr> ::= <add-expr>
| <shift-expr> << <add-expr>
| <shift-expr> >> <add-expr>
<add-expr> ::= <postfix-expr>
| <add-expr> + <postfix-expr>
| <add-expr> - <postfix-expr>
<postfix-expr> ::= <prim-expr>
| <postfix-expr> [ <expr> ]
| <postfix-expr> ( <expr> { "," <expr> } )
<prim-expr> := <number> | <ident> | <string> | "(" <expr> ")"Now begin the game
part1:
scanner
in this part, we just separate the words from source program. we will have two functions : void readchr() and void readtok()
so, in the next part - grammatical analysis, we can get the word by calling the readtok().
The algorithm is simple:
- skip leading spaces
- try to read an identifier (a sequence of letters, digits and _)
- if it’s not an identifier - try to read a sequence of special operators, like &, |, <, >, =, !.
- if it’s not an operator - try to read a string literal “….” or ‘….’
- if failed - maybe it’s a comment, like /* … */?
- if failed again - just read a single byte. It might be another single-byte token, like “(” or “[“.
The state transmission diagram:
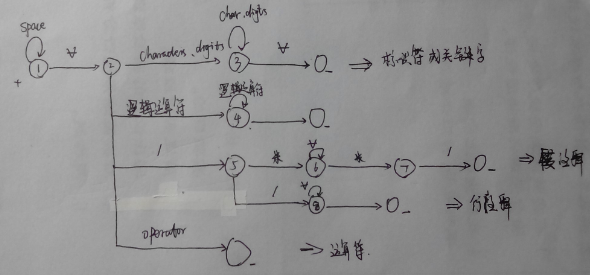
Code:
#include <stdio.h> /* for vpritnf */
#include <stdarg.h> /* for va_list */
#include <stdlib.h> /* for exit() */
#include <ctype.h> /* for isspace, isalpha... */
#define MAXTOKSZ 256
static FILE *f; /* input file */
static char tok[MAXTOKSZ];
static int tokpos;
static int nextc;
void readchr() {
if (tokpos == MAXTOKSZ - 1) {
tok[tokpos] = '\0';
fprintf(stderr, "token too long: %s\n", tok);
exit(EXIT_FAILURE);
}
tok[tokpos++] = nextc;
nextc = fgetc(f);
}
void readtok() {
for (;;) {
while (isspace(nextc)) {
nextc = fgetc(f);
}
tokpos = 0;
while(isalnum(nextc) || nextc == '_') {
readchr();
}
if (tokpos == 0) {
while (nextc == '<' || nextc == '=' || nextc == '>'
|| nextc == '!' || nextc == '&' || nextc == '|') {
readchr();
}
}
if (tokpos == 0) {
if (nextc == '\'' || nextc == '"') {
char c = nextc;
readchr();
while (nextc != c) {
readchr();
}
readchr();
} else if (nextc == '/') {
readchr();
if (nextc == '*') {
nextc = fgetc(f);
while (nextc != '/') {
while (nextc != '*') {
nextc = fgetc(f);
}
nextc = fgetc(f);
}
nextc = fgetc(f);
}
} else if (nextc != EOF) {
readchr();
}
}
break;
}
tok[tokpos] = '\0';
}
int main() {
f = stdin;
/*f = fopen("test.cpp","rw");
if(NULL == f){
return -1;
}*/
nextc = fgetc(f);
for (;;) {
readtok();
printf("TOKEN: %s\n", tok);
if (tok[0] == '\0') break;
}
//fclose(f);
//f = NULL;
return 0;
}
following is the result of the program:
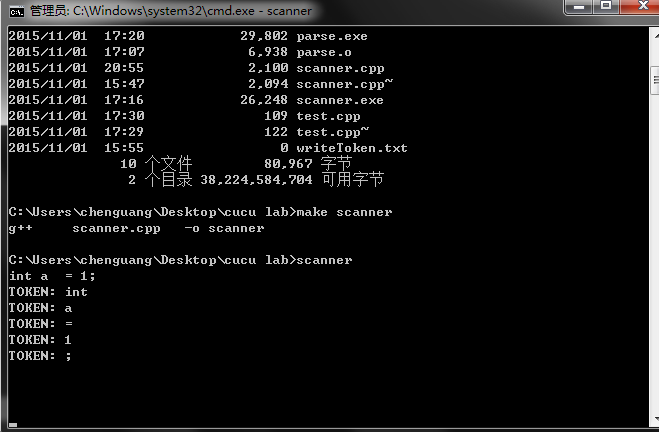
part2:
grammatical analysis
in this part, we will use recursive subprograms to deal with context free grammar. The input of this part is a Token - which is the result of the function readtok().
the main propose of this part is to check the source program whether have grammar mistake and rewrite expressions in a postfix form(instead of 2+3 it’s 2 3 +). So the main tool is a grammar tree. If you are still not very familiar to the grammar of our language, please look back and try to remember the production of our context - the contxt free grammar. That will help you to understand the code quickly.
Here’s the whole CUCU sources we’ve got so far:
#include <stdlib.h>
#include <stdint.h>
#include <stdarg.h>
#include <stdio.h>
#include <ctype.h>
#include <string.h>
using namespace std;
#define MAXTOKSZ 256
static FILE *f; /* input file */
static char tok[MAXTOKSZ];
static int tokpos;
static int nextc;
void readchr() {
if (tokpos == MAXTOKSZ - 1) {
tok[tokpos] = '\0';
fprintf(stderr, "token too long: %s\n", tok);
exit(EXIT_FAILURE);
}
tok[tokpos++] = nextc;
nextc = fgetc(f);
}
void readtok() {
for (;;) {
while (isspace(nextc)) {
nextc = fgetc(f);
}
tokpos = 0;
while(isalnum(nextc) || nextc == '_') {
readchr();
}
if (tokpos == 0) {
while (nextc == '<' || nextc == '=' || nextc == '>'
|| nextc == '!' || nextc == '&' || nextc == '|') {
readchr();
}
}
if (tokpos == 0) {
if (nextc == '\'' || nextc == '"') {
char c = nextc;
readchr();
while (nextc != c) {
readchr();
}
readchr();
} else if (nextc == '/') {
readchr();
if (nextc == '*') {
nextc = fgetc(f);
while (nextc != '/') {
while (nextc != '*') {
nextc = fgetc(f);
}
nextc = fgetc(f);
}
nextc = fgetc(f);
}
} else if (nextc != EOF) {
readchr();
}
}
break;
}
tok[tokpos] = '\0';
}
/*
* PARSER AND COMPILER
*/
/* print fatal error message and exit */
static void error(const char *fmt, ...) {
va_list args;
va_start(args, fmt);
vfprintf(stderr, fmt, args);
va_end(args);
exit(1);
}
/* check if the current token machtes the string */
int peek(char *s) {
return (strcmp(tok, s) == 0);
}
/* read the next token if the current token machtes the string */
int accept(char *s) {
if (peek(s)) {
readtok();
return 1;
}
return 0;
}
/* throw fatal error if the current token doesn't match the string */
void expect(char *s) {
if (accept(s) == 0) {
error("Error: expected '%s', but found: %s\n", s, tok);
}
}
static void expr();
/* read type name: int, char and pointers are supported */
static int typenam() {
if (peek("int") || peek("char")) {
readtok();
while (accept("*"));
return 1;
}
return 0;
}
static void prim_expr() {
if (isdigit(tok[0])) {
printf(" const-%s ", tok);
} else if (isalpha(tok[0])) {
printf(" var-%s ", tok);
} else if (accept("(")) {
expr();
expect(")");
} else {
error("Unexpected primary expression: %s\n", tok);
}
readtok();
}
static void postfix_expr() {
prim_expr();
if (accept("[")) {
expr();
expect("]");
printf(" [] ");
} else if (accept("(")) {
if (accept(")") == 0) {
expr();
printf(" FUNC-ARG\n");
while (accept(",")) {
expr();
printf(" FUNC-ARG\n");
}
expect(")");
}
printf(" FUNC-CALL\n");
}
}
static void add_expr() {
postfix_expr();
while (peek("+") || peek("-")) {
if (accept("+")) {
postfix_expr();
printf(" + ");
} else if (accept("-")) {
postfix_expr();
printf(" - ");
}
}
}
static void shift_expr() {
add_expr();
while (peek("<<") || peek(">>")) {
if (accept("<<")) {
add_expr();
printf(" << ");
} else if (accept(">>")) {
add_expr();
printf(" >> ");
}
}
}
static void rel_expr() {
shift_expr();
while (peek("<")) {
if (accept("<")) {
shift_expr();
printf(" < ");
}
}
}
static void eq_expr() {
rel_expr();
while (peek("==") || peek("!=")) {
if (accept("==")) {
rel_expr();
printf(" == ");
} else if (accept("!=")) {
rel_expr();
printf("!=");
}
}
}
static void bitwise_expr() {
eq_expr();
while (peek("|") || peek("&")) {
if (accept("|")) {
eq_expr();
printf(" OR ");
} else if (accept("&")) {
eq_expr();
printf(" AND ");
}
}
}
static void expr() {
bitwise_expr();
if (accept("=")) {
expr();
printf(" := ");
}
}
static void statement() {
if (accept("{")) {
while (accept("}") == 0) {
statement();
}
} else if (typenam()) {
printf("local variable: %s\n", tok);
readtok();
if (accept("=")) {
expr();
printf(" :=\n");
}
expect(";");
} else if (accept("if")) {
expect("(");
expr();
expect(")");
statement();
if (accept("else")) {
statement();
}
} else if (accept("while")) {
expect("(");
expr();
expect(")");
statement();
} else if (accept("return")) {
if (peek(";") == 0) {
expr();
}
expect(";");
printf("RET\n");
} else {
expr();
expect(";");
}
}
int main() {
f = fopen("test.cpp","rw");
if(NULL == f){
return -1;
}
nextc = fgetc(f);
readtok();
while (tok[0] != 0) { /* until EOF */
if (typenam() == 0) {
error("Error: type name expected\n");
}
printf("identifier: %s\n", tok);
readtok();
if (accept(";")) {
printf("variable definition\n");
continue;
}
expect("(");
int argc = 0;
for (;;) {
argc++;
typenam();
printf("function argument: %s\n", tok);
readtok();
if (peek(")")) {
break;
}
expect(",");
}
expect(")");
if (accept(";") == 0) {
printf("function body\n");
statement();
}
}
fclose(f);
f = NULL;
return 0;
}
until now
- we have finished the scanner and grammatical analysis , we also have put them together . So, what’s we will get if we write a program and run it in this procedure?
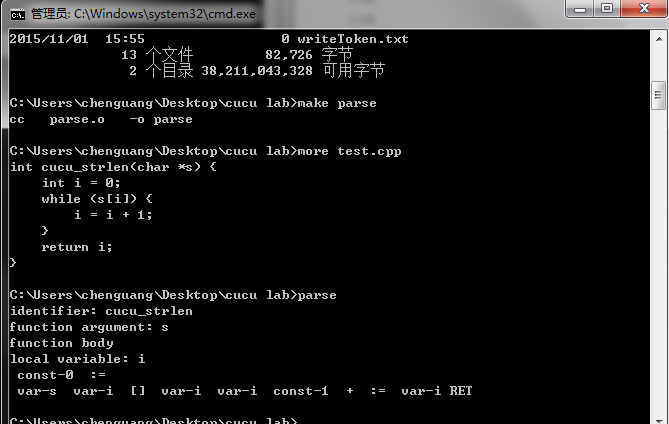
- we can separate and check the grammar of source program . just so















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









