







 本文介绍了在聚类分析中几种常见的距离计算方法,包括闵科夫斯基距离、VDM(Value Difference Metric)、余弦距离、马氏距离以及KL散度。这些距离指标用于衡量样本之间的相似性,特别是在处理不同属性类型的数据时。例如,余弦距离适合高维数据,而马氏距离考虑了属性间的关联。文章还提供了相关Python实现和参考资料。
本文介绍了在聚类分析中几种常见的距离计算方法,包括闵科夫斯基距离、VDM(Value Difference Metric)、余弦距离、马氏距离以及KL散度。这些距离指标用于衡量样本之间的相似性,特别是在处理不同属性类型的数据时。例如,余弦距离适合高维数据,而马氏距离考虑了属性间的关联。文章还提供了相关Python实现和参考资料。
距离计算
我们通常采用计算“距离”的方法来度量不同样本之间的相似性,进而判断该样本的大致类别。距离首先是一个几何概念,用 dist(⋅,⋅) d i s t ( ⋅ , ⋅ ) 表示,其中最为任熟悉的是二维和三维几何空间的欧几里德距离,随着数据维度的增大,距离在维数、幂次数等方面被推广了,距离被抽象为满足一些基本性质:
非负性:
dist(xi,xj)≥0;(1.1) (1.1) d i s t ( x i , x j ) ≥ 0 ;
同一性:
dist(xi,xj)=0,当且仅当xi=xj;(1.2) (1.2) d i s t ( x i , x j ) = 0 , 当 且 仅 当 x i = x j ;
对称性:
dist(xi,xj)=dist(xj,xi);(1.3) (1.3) d i s t ( x i , x j ) = d i s t ( x j , x i ) ;
直递性:
dist(xi,xj)≤dist(xi,xk)+dist(xk,xj);(1.3) (1.3) d i s t ( x i , x j ) ≤ d i s t ( x i , x k ) + d i s t ( x k , x j ) ;
需要注意的是,用于相似度度量的距离未必一定满足以上所有的性质,尤其是直递性(1.3)。例如在某些任务中我们可能希望有这样的相似度度量:“人”“马”分别与“人马”相似,但“人”与“马”很不相似;要达到这个目的,可以令“人”“马”与“人马”之间的距离很小,但“人”与“马”之间的距离很大,如下图所示:
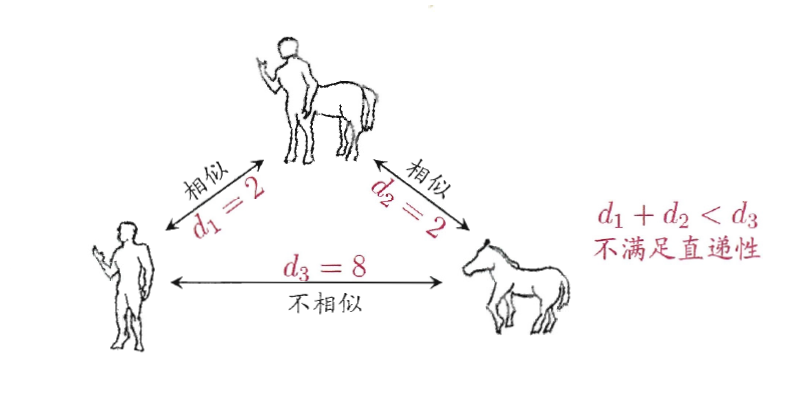
为了让大家对各种距离计算方法的应用场景有个清楚的认识,在讲距离计算方法之前,我先介绍一下几个名词。
- 属性:即样本本身所具有的特征,样本空间中的维度,就是属性的个数。
- 连续属性:样本的属性在定义域上有无穷多个可能的取值,比如说树的高度在 [7,10] [ 7 , 10 ] 米之间,其取值是无穷多的。
- 离散属性:样本的属性在定义域上是有限个取值,比如说树的品种,肯定是有限的,只能从 { 白杨树,柳树,...,桃树} { 白 杨 树 , 柳 树 , . . . , 桃 树 } 中取值,那么树的品种就属于离散属性
- 有序属性:就是说,属性的值能直接用来计算计算距离。例如树的高度。
- 无序属性:就是说,属性的值不能直接用来计算计算距离。例如树的品种。
因此所有样本的属性都可划分为有序属性或者无序属性,或者同时具有有序属性和无序属性,这里我们成为混合属性。针对于有序属性的样本,我们常常使用闵科夫斯基距离计算公式来衡量样本之间的相似度,针对于无序属性的样本我们可采用 VDM V D M (Value ( V a l u e Dif
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









