







文章目录
前言
结合自己项目中可能会被面试官问到的问题,对机器学习中的几个常见方法进行回顾总结。该篇笔记没有详细的数理讲解,主要目的是为了唤醒自己的记忆,保证在面试现场可以回答得清晰有逻辑。
一、K邻近算法
K邻近算法(K-Nearest Neighbors,简称KNN)是一种基本的分类和回归算法,常用于模式识别和数据挖掘任务中。它的核心思想是根据样本之间的距离度量来确定新样本的分类或预测值。
KNN算法的工作原理如下:
1.训练阶段(Training Phase):将已知类别的样本数据集作为训练数据,存储在内存中。
2.测试阶段(Testing Phase):对于一个新的待分类样本,算法会计算该样本与训练数据集中每个样本的距离(通常使用欧氏距离或曼哈顿距离等),然后选取距离最近的K个样本(K是一个预先设定的值)。
3.选择K个近邻样本:根据选择的K值,找出距离最近的K个样本。
4.多数表决(Majority Voting):对于分类任务,K个近邻样本中出现次数最多的类别即为新样本的预测类别。对于回归任务,可以取K个近邻样本的平均值作为新样本的预测值。
K邻近算法缺点:
-
计算复杂度高:KNN需要计算测试样本与所有训练样本之间的距离,并找出距离最近的K个邻居。在大规模数据集上,这种计算复杂度很高,尤其是当特征维度较高时,可能会受到所谓的"维度灾难"的影响。
-
存储需求大:KNN算法需要保存训练数据集中的所有样本,在内存中存储大规模数据集可能会占用较多的存储空间。
-
预测速度慢:由于KNN是一种懒惰学习算法,它在测试阶段才进行计算。每次进行预测时,都需要计算新样本与所有训练样本的距离,因此预测速度相对较慢。
-
对异常值敏感:KNN算法的结果受到训练数据中异常值的影响。由于KNN是基于距离的算法,异常值可能会对距离计算产生较大的影响,导致错误的预测结果。
-
需要选择合适的K值:KNN算法中的K值是一个重要参数,它需要根据具体问题和数据集进行选择。较小的K值可能会使模型对噪声敏感,较大的K值可能会使决策边界变得过于平滑,无法良好地适应复杂的数据分布。
-
类别不平衡问题:当训练数据中的类别分布不平衡时,KNN可能会出现偏向于占比较多的类别的情况,导致对少数类别的预测效果较差。
提供一个样例:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 创建示例数据集
X = np.array([[1, 2], [2, 1], [2, 3], [3, 2], [4, 2], [3, 3]])
y = np.array([0, 0, 0, 1, 1, 1])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN分类器对象
knn = KNeighborsClassifier(n_neighbors=3)
# 在训练集上训练KNN模型
knn.fit(X_train, y_train)
# 对测试集进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
二、线性回归
利用线性模型学得一个通过特征信息的线性组合得到预测值的方法。当特征为多维时,这个分割面称为超平面
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(LSM, least square method)
从构建误差到求解误差的最小值实际上发生了下面的数学公式处理过程,希望有个印象:
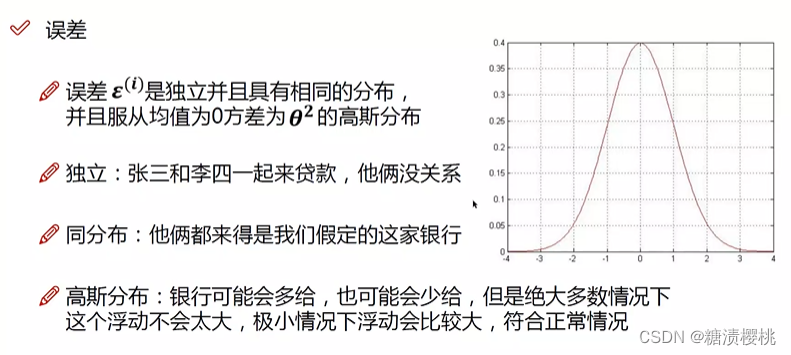


用对数方法简化计算量,虽然值会发生改变,但我们求的不是极值,而是找满足条件的theta极值点,极值点是不会改变的,所以没有关系。

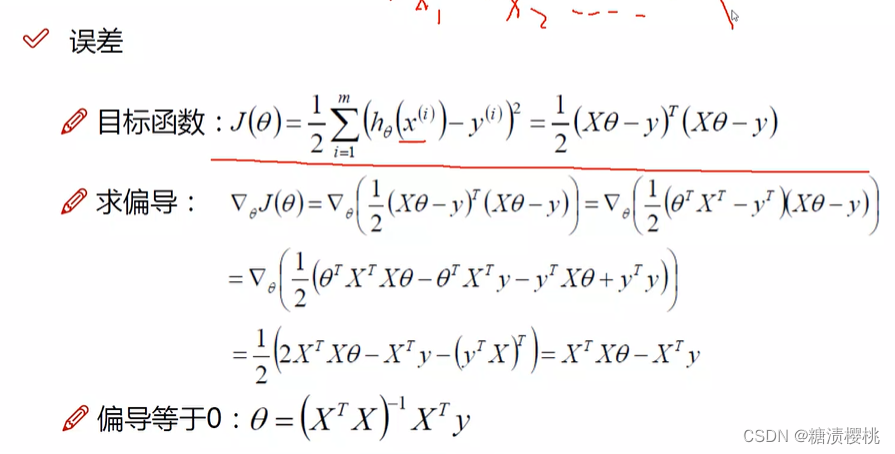
梯度下降
梯度下降为什么是梯度的反方向?
梯度下降是一种常用的优化算法,用于求解函数的最小值。在梯度下降算法中,梯度的方向被选为搜索方向的原因可以从以下两个角度解释:
- 梯度的方向是函数在当前点上升最快的方向。梯度是一个向量,它包含了函数在每个维度上的偏导数。偏导数表示了函数在该维度上的变化率。梯度的方向是函数在当前点上升最快的方向,而梯度的反方向则是函数在当前点下降最快的方向。因此,选择梯度的反方向作为搜索方向可以朝着函数取得更小值的方向进行更新。
- 梯度下降算法的目标是不断迭代地接近函数的最小值。梯度下降算法通过迭代更新当前点的位置,使得函数值逐渐减小。在每一次迭代中,算法根据当前点的位置和梯度的方向来确定下一个点的位置。由于梯度的方向指向函数下降最快的方向,选择梯度的反方向作为搜索方向可以朝着最小值的方向逐步接近

三、逻辑回归
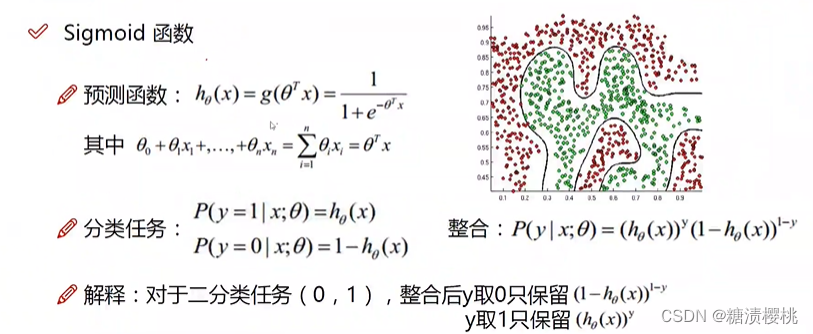
与线性回归的区别:逻辑回归可以理解为在线性回归后加了一个sigmoid函数。将线性回归变成一个0~1输出的分类问题。
逻辑回归与线性回归的区别是什么?
1.线性回归用来预测连续的变量(房价预测),逻辑回归用来预测离散的变量(分类,癌症预测)
2. 线性回归是拟合函数,逻辑回归是预测函数
3. 线性回归的参数计算方法是最小二乘法,逻辑回归的参数计算方法是似然估计的方法
逻辑回归与线性回归、最大熵模型、SVM、朴素贝叶斯等基本机器学习模型的对比
四、决策树
决策树(Decision Tree)是一种基于树结构的监督学习算法,常用于分类和回归任务。它通过构建一个树形模型来进行决策,根据特征的取值将数据集划分为不同的子集,最终在叶节点上给出预测结果。
主要工作步骤:
-
特征选择:决策树通过选择最佳的特征来进行划分,以使得每个子集中的样本尽可能纯净。常用的特征选择指标包括信息增益、信息增益比、基尼系数等。
-
树的构建:从根节点开始,根据特征选择准则将数据集划分为不同的子集。递归地对每个子集进行划分,直到达到预定的停止条件,如达到最大深度、样本数量小于阈值等。
-
树的剪枝:决策树容易过拟合训练数据,为了提高泛化能力,可以采用剪枝(Pruning)策略。剪枝通过去掉一些节点或子树来简化模型,减少过拟合的风险。
-
预测过程:根据构建好的决策树模型,对新样本进行预测时,从根节点开始根据样本的特征值进行判断,沿着相应的分支走到叶节点,该叶节点的预测结果即为模型的预测结果。
我觉得人家已经写得很好看很详细了,回顾为主,节省时间,直接戳这里回忆学习叭


五、集成学习
主要类型:boosting、bagging、stacking
多个学习器分析的结果可能很好,也可能只能做到局部最优,因此结合策略也多种多样。常见的类型有:平均法、投票加权法、学习法。显然学习法具有更好的灵活性,即在完成基学习之后的结合学习称为次级学习或元学习。最常见的方法就是stacking。
boosting的学习方法会先生成多个串行的弱学习器,后一个弱学习器会根据前一个弱学习器的学习结果调整数据的分布,尤其关注那些在上一个弱学习器中被评估错误的样本数据。经过多次微调获得的这多个弱学习器的参数都会保留,然后结合在一起构成一个强学习器。在弱学习器上的准确率如果只有60%,那么在最终结合得到的强学习器上准确率可能会达到90%。
但是这样的集成学习方法具有很强的不稳定性特点,也就是说极易收到数据扰动性的干扰,因此需要增强数据的多样性。在Adaboost中往往会采用序列采样的方式,以保证在弱学习器上样本的多样性。
衍生产品1:随机森林
随机森林RF(它属于bagging类型)是以决策树为基学习器构建bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择。因为,决策树总是以当前结点的最优属性作为划分倾向,而随机森林则是在当前结点的属性中随机选择一些属性,构成多个并行结构,然后在分支子集中选择最优属性进行偏好选择。随机森林计算开销小、学习效果好、性能强大
衍生产品2:Adaboost和XGboost
AdaBoost(自适应增强)和XGBoost(极端梯度提升)都是集成学习中常用的算法,两者的区别是:
- 基本算法:AdaBoost是一种迭代算法,通过训练一系列弱分类器(如决策树)来构建一个强分类器。每个弱分类器都会根据前一个分类器的错误进行加权,以便更好地预测错误分类的样本。而XGBoost是基于梯度提升树的算法,通过迭代地训练决策树模型,每一次训练时都会优化损失函数的梯度,以得到更好的拟合效果。
- 损失函数:AdaBoost使用指数损失函数,通过最小化错误率来训练模型。而XGBoost支持多种损失函数,包括平方损失、指数损失、对数损失等,可以根据具体问题进行选择。
- 并行计算:XGBoost在设计时考虑了并行计算的能力,可以利用多线程进行高效的并行训练,加快模型的训练速度。而AdaBoost是顺序训练的,无法直接进行并行计算。
- 正则化:XGBoost引入了正则化项,如L1正则化和L2正则化,以控制模型的复杂度并避免过拟合。AdaBoost没有显式的正则化机制。
- 特征选择:XGBoost在每次拟合决策树时,会根据特征的重要性进行特征选择,选择最佳的分裂点。而AdaBoost并没有显式的特征选择过程。
- 鲁棒性:XGBoost在处理缺失值和异常值时具有较好的鲁棒性,可以自动处理缺失值,并对异常值进行鲁棒性优化。而AdaBoost对于缺失值和异常值的处理较为敏感。
- 对噪声的鲁棒性:AdaBoost对噪声数据敏感,容易受到噪声数据的干扰。而XGBoost通过引入正则化和梯度优化等技术,对噪声数据有较好的鲁棒性。
AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被凸显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。以此类推,将所有的弱分类器重叠加起来,得到强分类器。
解释来源:牛客网评论区
六、贝叶斯分类器
贝叶斯分类器详解
个人总结:
-
在贝叶斯学习中,我们用概率分布来表示知识,新的知识则通过观察数据并更新这些概率分布来获取。这种方法的优势在于,我们不仅可以预测新的结果,而且可以量化我们对预测结果的不确定性。
-
要使用贝叶斯判定准则来最小化决策风险,首先要获得后验概率P(c|x)。然而,在现实任务中这通常是难以获得的。所以,机器学习首先要基于有限的训练样本准确地估计出后验概率,然后才能基于后验概率计算期望损失,做出决策风险预估。直接通过建模后验概率完成预测的称为判别式模型,决策树、BP神经网络、支持向量机等就属于这类模型,贝叶斯属于通过联合概率建模再获得后验概率进行数据分析的模型,即生成式模型。
-
极大似然估计法:先假定所有的数据满足某种特定的分布,通常也是独立同分布的,然后对这种分布的参数进行估计,得到最合适的参数后再进一步分析数据。
七、K-means聚类算法
以样本间的距离远近划分相似程度,使用的是最小化平方误差
在 K-means 聚类算法中,均值体现在以下两个方面:
- 计算聚类中心:K-means 算法的目标是将数据集划分为 K 个簇,其中每个簇由一个聚类中心代表。聚类中心是簇内数据点的平均值,也就是簇内所有数据点的均值。算法的迭代过程中,会计算每个簇的新聚类中心,即将该簇内所有数据点的均值作为新的聚类中心。
- 数据点分配到最近的聚类中心:K-means 算法将数据点分配到最近的聚类中心,也就是将数据点分配到距离它最近的聚类中心所代表的簇。这里的距离通常使用欧氏距离或其他距离度量方式来计算。分配数据点的过程是通过比较数据点与每个聚类中心之间的距离,选择距离最小的聚类中心进行分配。
- 因此,K-means 算法的均值体现在计算聚类中心和数据点分配过程中。通过迭代计算簇内数据点的均值作为新的聚类中心,并将数据点分配到最近的聚类中心,实现对数据集的聚类操作。
八、主成分分析法
降维的方法之一,筛选出最能够体现数据差异性的特征因子。实现的主要依据是基于最小投影距离。
九、支持向量机SVM
总结
以上是项目接触过程中遇见的几个重要方向算法和模型,具体的技术细节没有赘述。如有项目回顾的需要,会继续修订。















 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









