








欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
前面三篇写了线性回归,lasso,和LARS的一些内容,这篇写一下决策树这个经典的分类算法,后面再提一提随机森林。关于决策树的内容主要来自于网络上几个技术博客,本文中借用的地方我都会写清楚出处,写这篇[整理文章]的目的是对决策树的概念原理、计算方法进行梳理。本文主要参考文献的[1][2]的图片和例子。另外,[3]写的也比较仔细,有代码可以参考,可以看看。不过如果只想简单了解一下原理,看本文即可。
决策树
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果[1]。
下面先来看一个小例子,看看决策树到底是什么概念(这个例子来源于[2])。
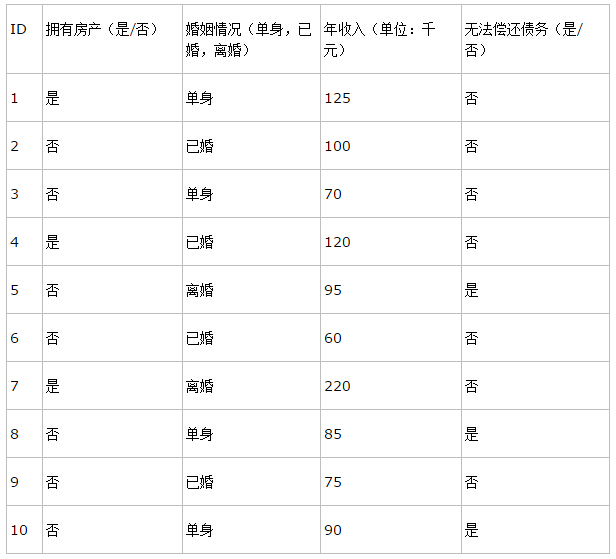
决策树的训练数据往往就是这样的表格形式,表中的前三列(ID不算)是数据样本的属性,最后一列是决策树需要做的分类结果。通过该数据,构建的决策树如下:
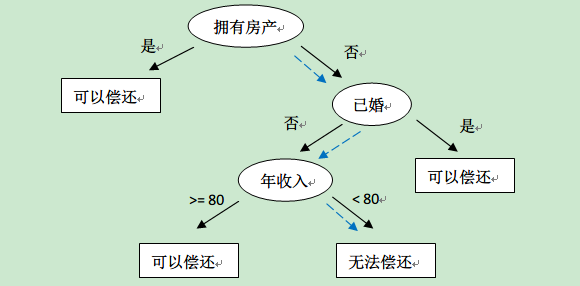
有了这棵树,我们就可以对新来的用户数据进行是否可以偿还的预测了。
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况[1]:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
决策树的属性分裂选择是”贪心“算法,也就是没有回溯的。
ID3.5
好了,接下来说一下教科书上提到最多的决策树ID3.5算法(是最基本的模型,简单实用,但是在某些场合下也有缺陷)。
信息论中有熵(entropy)的概念,表示状态的混乱程度,熵越大越混乱。熵的变化可以看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
设D为用(输出)类别对训练元组进行的划分,则D的熵表示为:
其中 pi 表示第i个类别在整个训练元组中出现的概率,一般来说会用这个类别的样本数量占总量的占比来作为概率的估计;熵的实际意义表示是D中元组的类标号所需要的平均信息量。熵的含义可以看我前面写的 PRML ch1.6 信息论的介绍。
如果将训练元组D按属性A进行划分,则A对D划分的期望信息为:
于是,信息增益就是两者的差值:
ID3决策树算法就用到上面的信息增益,在每次分裂的时候贪心选择信息增益最大的属性,作为本次分裂属性。每次分裂就会使得树长高一层。这样逐步生产下去,就一定可以构建一颗决策树。(基本原理就是这样,但是实际中,为了防止过拟合,以及可能遇到叶子节点类别不纯的情况,需要有一些特殊的trick,这些留到最后讲)
OK,借鉴一下[1]中的一个小例子,来看一下信息增益的计算过程。
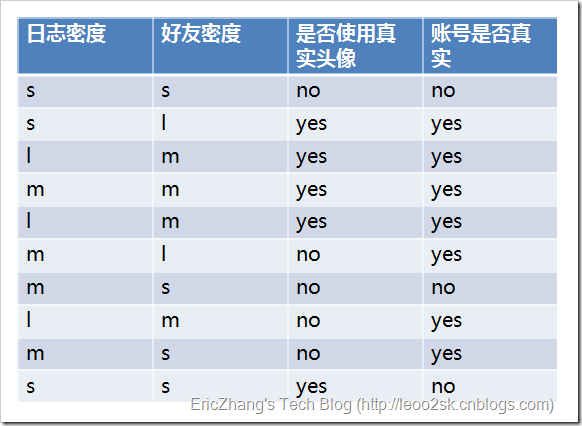
这个例子是这样的:输入样本的属性有三个——日志密度(L),好友密度(F),以及是否使用真实头像(H);样本的标记是账号是否真实yes or no。
然后可以一次计算每一个属性的信息增益,比如日致密度的信息增益是0.276。
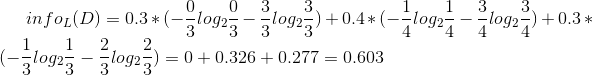
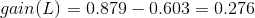
同理可得H和F的信息增益为0.033和0.553。因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
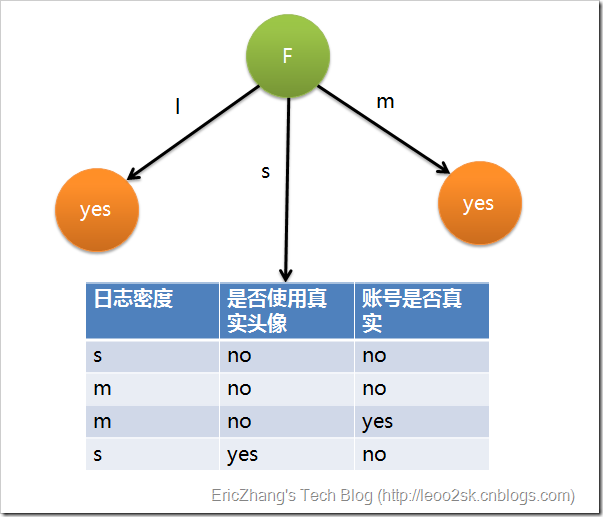
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
C4.5
ID3有一些缺陷,就是选择的时候容易选择一些比较容易分纯净的属性,尤其在具有像ID值这样的属性,因为每个ID都对应一个类别,所以分的很纯净,ID3比较倾向找到这样的属性做分裂。
C4.5算法定义了分裂信息,表示为:
很容易理解,这个也是一个熵的定义,
pi=|Dj||D|
,可以看做是属性分裂的熵,分的越多就越混乱,熵越大。定义信息增益率:
C4.5就是选择最大增益率的属性来分裂,其他类似ID3.5。
实现trick
这一部分参考[2]
停止条件
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
过度拟合
采用上面算法生成的决策树在事件中往往会导致过度拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过渡拟合的原因有以下几点:
•噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
•缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
•多重比较(Mulitple Comparision):举个列子,股票分析师预测股票涨或跌。假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为 ,
C810∗(0.5)10+C910∗(0.5)10+C1010∗(0.5)10
只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为
1−(1−0.0547)50=0.9399
,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
优化方案1:修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;2)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
优化方案2:K-Fold Cross Validation
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。(意思是说对每一个可能的i,都做K次,然后取K次的平均错误率。)这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
优化方案3:Random Forest
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。RF是非常常用的分类算法,效果一般都很好。
OK,决策树就讲到这里,商用的决策树C5.0了解不是很多;还有分类回归树CART也很常用。
参考资料
[1] http://kb.cnblogs.com/page/76196/
[2] http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
[3] http://blog.csdn.net/v_july_v/article/details/7577684
[4] http://baike.baidu.com/link?url=EiLhx_PTLnBvXTxaQslGtVq2x_-a0uKQZydPLzjiETOGj4gt8xzNpwlMurW7zGYBDQFwGe9tR_75prXSccAePK

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









