






前言
线性回归算法是实践中广泛使用的一类模型,多年来被广泛研究。线性模型利用输入特征的线性函数进行预测。考虑到线性分类模型是在线性函数的基础上设立合适的阈值对样本进行分类,本文重点讲述线性回归的原理及代码实现。
一、普通最小二乘法原理及实现
线性模型的基础公式是:
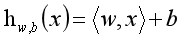
对上式的解释及思考:
在样本空间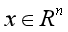 中,输入m条训练数据
中,输入m条训练数据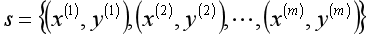
输出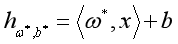 ,使得
,使得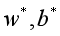 为优化问题
为优化问题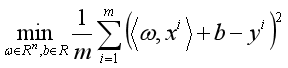 的最优解。
的最优解。
从上面可以看到,采用均方误差作为损失函数。在实际操作中可以添加一个首位为1的向量,则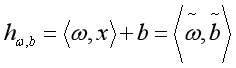 ,此时为
,此时为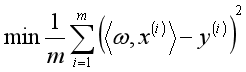 最优化问题。
最优化问题。
考虑模型的拟合效果,需要引入标尺(决定系数)来判断。设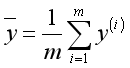 为训练数据标签的平均值。则决定系数
为训练数据标签的平均值。则决定系数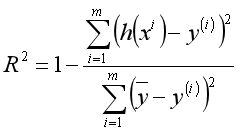 。
。
以上为线性回归模型的基础知识,接下来介绍一下线性回归模型的优化算法——正规方程算法。在后续的文章里,可能介绍更实用的算法。
线性回归的均方误差:
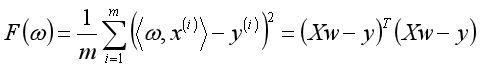
求导得(具体求导第一篇文章上提过):
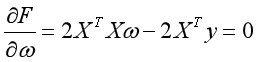
则当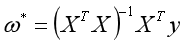 时取得最小值。要求
时取得最小值。要求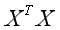 可逆。
可逆。
到这里,可以采用编程实现:
mport numpy as np
import matplotlib.pyplot as plt
# 二乘法的代码实现,采用正规方程算法
class LinearRegression:
"""最小二乘法的代码实现"""
def fit(self, X, y):
"""计算权重值
输入:
X:样本的特征值
y:样本的标签
返回:
无"""
self.w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) #np.linalg.inx()计算矩阵的(乘法)逆
def predict(self, X):
"""模型的预测
输入:
X:样本的特征值
返回:
模型的预测值"""
return X.dot(self.w)
二、多项式回归
在实际问题中,标签与特征的关系并非是线性的,而是多项式关系。在这种情况下,就需要用多项式回归来拟合标签预特征的关系。
比如设
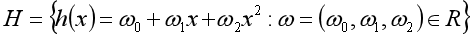
采用最小化算法得出的一个模型为
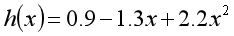
尽管训练数据中只给出了一个特征x,但是,如果将1、x、x^2均看作特征,则多项式,则上式也可以看作标签关于这3各特征的线性模型。
由上,推广到一般情况,n元d次多项式。
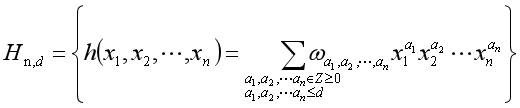
n元d次多项式含有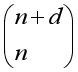 各单项式。将每一个单项式作为一个特征利用线性模型求出权重。
各单项式。将每一个单项式作为一个特征利用线性模型求出权重。
根据现有特征,导出多项式特征可以使用sklearn库实现。
from sklearn.preprocessing import PolynomialFeatures # 多项式的操作库
if __name__ == '__main__':
def generate_samples(m):
X = 2 * np.random.rand(m,1)
y = X**2 - 2*X + 1 + np.random.normal(0, 0.1, (m, 1))
return X, y
np.random.seed(0)
X, y = generate_samples(100)
ploy = PolynomialFeatures(degree=2)
X_ploy = ploy.fit_transform(X)
model = LinearRegression()
model.fit(X_ploy, y)
plt.scatter(X, y)
W = np.linspace(0,2,300).reshape(300,1)
W_ploy = ploy.fit_transform(W)
u = model.predict(W_ploy)
plt.plot(W, u)
plt.show()
作出如下的图形:

可以看出,利用多项式结合线性模型可以拟合出曲线。
三、线性回归的正则化算法
线性回归算法式一个经验损失最小化算法,在某些情况下会出现过拟合,特别是在应用多项式回归算法时。一般来说,导致过拟合主要有特征个数过多与训练数据不足两大原因。当特征个数大于训练数据,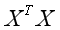 不可逆。而正则化方法是目前最常用的用于降低过度拟合概率。
不可逆。而正则化方法是目前最常用的用于降低过度拟合概率。
首先介绍采用L2正则化的线性回归——岭回归算法。L2正则化认为w的所有元素都有应该尽可能小,接近于0。
其为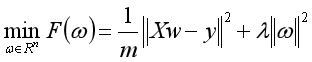 的优化问题,
的优化问题,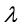 为正则化系数。
为正则化系数。
根据上述,目标函数时严格凸函数,为:
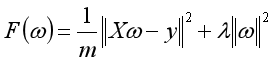
求导,令导数为0:
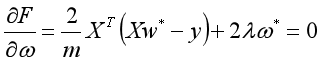
则当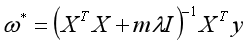 时,取得最小值。要求
时,取得最小值。要求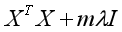 可逆。
可逆。
利用代码实现:
import numpy as np
import matplotlib.pyplot as plt
# 岭回归的代码实现,采用正规方程算法
class RidgeRegression:
"""岭回归的代码实现"""
def __init__(self, Lambda):
"""自动继承lambda值"""
self.Lambda = Lambda
def fit(self, X, y):
"""计算权重值
输入:
X:样本的特征值
y:样本的标签
返回:
无"""
m, n = X.shape
r = m * np.diag(self.Lambda * np.ones(n)) # np.diag(a) 如果a为一维数组,则生成一个以一维数组为对角线元素的矩阵,如果a为二维矩阵,则输出矩阵的对角线元素
self.w = np.linalg.inv(X.T.dot(X) + r).dot(X.T).dot(y)
def predict(self, X):
"""模型的预测
输入:
X:样本的特征值
返回:
模型的预测值"""
return X.dot(self.w)
多项式回归于岭回归:
from sklearn.preprocessing import PolynomialFeatures # 多项式的操作库
if __name__ == '__main__':
def generate_samples(m):
X = 2 * (np.random.rand(m,1) - 0.5)
y = X + np.random.normal(0, 0.3, (m, 1))
return X, y
np.random.seed(100)
X, y = generate_samples(10)
ploy = PolynomialFeatures(degree=10)
X_ploy = ploy.fit_transform(X)
model = RidgeRegression(Lambda=0.01)
model.fit(X_ploy, y)
plt.axis([-1,1,-2,2])
plt.scatter(X, y)
W = np.linspace(-1,1,100).reshape(100,1)
W_ploy = ploy.fit_transform(W)
u = model.predict(W_ploy)
plt.plot(W, u)
plt.show()
作出下图所示的模型,拟合效果相当不错。

再介绍L2正则化的线性模型——lasso回归。L1正则化认为w的某些系数刚好为0。其为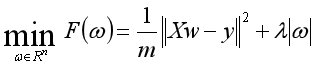 的优化问题。
的优化问题。
还有一种兼顾岭回归与Lasso回归二者的算法——弹性网络回归。
为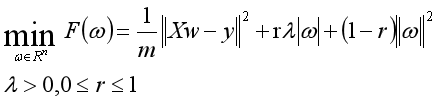 的优化问题。
的优化问题。
由于Lasso回归与弹性网络回归的目标函数都是不可微的,因而不能使用正规方程算法。可以采用次梯度下降算法或者坐标下降算法。在后续的算法将详细介绍。
总结
线性模型的主要参数是正则化参数,正则化参数较大时,说明模型越简单。如果假定只有几个特征是真正重要的,可以采用L1正则化。否则默认使用L2正则化。如果模型的可解释性重要的话,使用L1正则化也很有帮助。
线性模型的训练速度非常快(采用其它优化算法),预测速度也很快。这种模型可以推广到非常大的数据集,对系数数据也很有效。线性模型的另一个优点在于理解相对容易。但是在数据集中包含高度相关的特征,可能很难对系数进行做出解释。另一方面,线性模型在低维空间中可能非常受限。
本文是《机器学习算法导论》(王磊,王晓东)的学习笔记。















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









