






K近邻(K-NN)
一,前言
KNN算法可以说使最简单的机器学习模型。通常认为,相似的事物经常使属于同一类别的。KNN便是基于此思想提出的算法。即样例再空间中距离越小,它们之间的相似度就越高。二使用其完成分类任务较多。本文主要学习最近邻分类器,而回归算法仅作简单的概述。
二,k近邻法则
首先是单一邻居(最近邻)的k近邻,如图一所示,在分类任务中,如果y是x的最近邻,则认为x与y属于同一类。

当然,在有噪声的样例中,最近邻的真伪是不可靠的。如图一左上角的原点,我们有理由相信其实一个噪声点,此时将此点分为圆形类可能是错误的。为了提高模型的鲁棒性,可以找到多个最近邻而非单一近邻,然这些最近邻点投票决定。这就是k近邻分类器的实质。其中k是参与投票的近邻个数,通常由使用者自行决定。如图二,是一个k=3的最近邻模型,此时左上角星型的分类值与图一是不同的,它有效的降低了样例中噪音的影响。值得注意的是,在二分类任务中,应将k值设置为奇数,避免两个类数量均分的情况。

三,度量相似性
寻找对象x的最近邻的一个最常用的方法就是比较从x到每个训练样例之间的几何距离。最常用的方法就是采用欧式距离。即两个样本
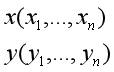
欧式距离为
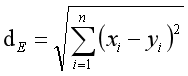
一个更为通用的公式为:此距离也叫做海明距离。
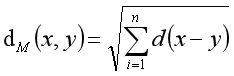
举一个简单的例子x = (2,1.5,summer),y = (1,0.5,winter),可以看出,前两个特征为连续型数据,最后一个特征为离散型数据。此时,可以用公式求得它们的距离:
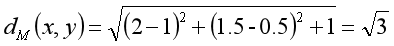
但是,需要注意的是属性与属性之间的距离可能被误导。例如上例中在季节上面的判别d(summer,winder)=1。明显不符合常理,夏秋,春冬的距离也是1。根据实际情况判别,秋冬的差异比春秋的差异更大,在这里使用0和1的差异显然是不够的。另一方面,将连续和离散的属性混合在一起也是非常危险的,因为连续数据的距离可能很大,而离散数据的差异最大为1,这种情况下,离散数据就可能对度量的影响微乎其微。因此,需要在构建模型之前进行数据的预处理。
综上所述,距离度量有一下基本性质:
1,距离不能为负;
2,相同两个向量间的距离为0;
3,x到y与y到x之间的距离是一样的;
4,距离度量必须满足三角不等式: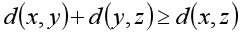
四,不相关属性与瓷都缩放问题
通过上述描述,了解到k近邻分类器的基石是“所描述对象的向量之间的几何距离越小,那对象越相似”。但是,有些情况下,距离又会形成某些误导,比如给你包含鞋号和体温数据的样本,来判断一个人当前的健康状态。显然,鞋号在分类中属于不相关属性,将其用于计算距离会导致很大的影响。幸运的是,在含有很多特征的样本中,其中很少量的不相关属性不会对模型性能产生很大影响。
前文也已经讲过,属性值的尺度不一致会对模型产生较大影响,因此需要对数据进行预处理。最常用的方法就是归一化处理。在很多实例中,数据预处理降低了错误率,特别是在原始尺度明显不同的情况下。当然这样做也有潜在的弱点。比如不同的离散数据的差异值为1,而经过归一化处理的连续数据永远不会大于1,即无形中抬高了离散数据的权重。
五,模型性能的影响
首先考虑k值对模型的影响。通常认为k值越大,模型所参考的样本就越多,模型的性能就越大。但是,试想一下,当k值与样本数一致时,模型就会判定分类点为样本空间中最多的类。显然时不合理的。实际上,k值的设定既不能太少也不能太多,需要根据实际情况选择。
现在为止,上文讲述的都是以近邻点类别的数量多少作为分类的标准。但是,在现实中,不太可能会是k个近邻点与样本点的距离都相等,此时使用个数作为依据对那些距离较近的点显然是不够公平的。此时就需要使用加权最近邻。这里提供一个简单的加权最近邻公式,其原理与归一化基本相同。
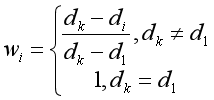
前文的分析可以知道,有些样例的存在可能完全就是误导的样例,在使用模型之前需要将这些危险样例移除。那哪些是危险样例呢?通常认为一个样本被标注为一个类别,但是它被其它类别的样例所包围,那它可能是由噪声所造成的。如图一左上角的圆点。还有一类是属于两个类的边界区域的样例,因为它们的属性值可以被很小的噪声影响,而令它们的位置向着错误的方向改变。
为了移除这些风险样例,数学家提出里托梅克链接,即一个样例对x与y,如果满足3个要求,即说它们形成了一个托梅克连接。
1,x是y的最近邻;
2,y是x的最近邻;
3,x和y的类别不同。
当然,有时移除托梅克链接,还会产生新的托梅克连接,因此,需要重复多次使用。下表提供确认和移除托梅克链接的算法。
| 输入:N个样例的一个训练集 |
|---|
| 1.令i=1,T为一个空集 |
| 2.令x是第i个训练样例,y是x的最近邻 |
| 3.如果x和y属于同一个类别,转到5 |
| 4.如果x是y的最近邻,令T U {x,y} |
| 5.令i=i+1。如果i<=N,转到2 |
| 6,从训练集种将所有在T中的样例移除 |
当然在训练集非常小时,当一个类的样本数明显多于另一个类时,需要谨慎使用托梅克链接技术。
还有一种情况,当样本数很大时,有些样本的存在与否对模型的错误率并无影响,则这些样例叫做多余样例。这些样例的存在会增加计算代价,需要将其移除。当然,移除这些样例并不需要完全删除这些冗余样例,只要尽可能多的移除这些样例就可以了。为此,数学假提供了一个构建一致子集的算法,来删除这些多余样例。
| 构建一致子集 |
|---|
| 1.使得S包含训练集T中的一个正类样例和一个负类样例。 |
| 2.基于S中的样例,用最近邻分类器对T中的样例重新分类。假设M是这时被错误的分类的样例集合。 |
| 3.将M中的样例复制到S中 |
| 4.如果S中的元素未发生改变,算法停止,否则转到步骤2 |
六,k近邻的优缺点
优点: k近邻的优点之一就是模型恒容易理解,通常不需要过多调节就可以得到不错的性能,构建模型的速度也很快。
缺点: 当特征数很多或者样本数很大时,k近邻的预测速度便会很慢,对很大的数据集以及稀疏数据集的效果尤其不好。
当然,k近邻也可以用于回归,在左回归与测试,其预测值未k个近邻点的平均值。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









