






matlab程序:EMD-SSA-BiLSTM预测程序
将数据进行EMD分解,再采用经蚁群算法优化的双向长短时记忆神经网络进行预测,最终将结果重组得到最终预测结果。
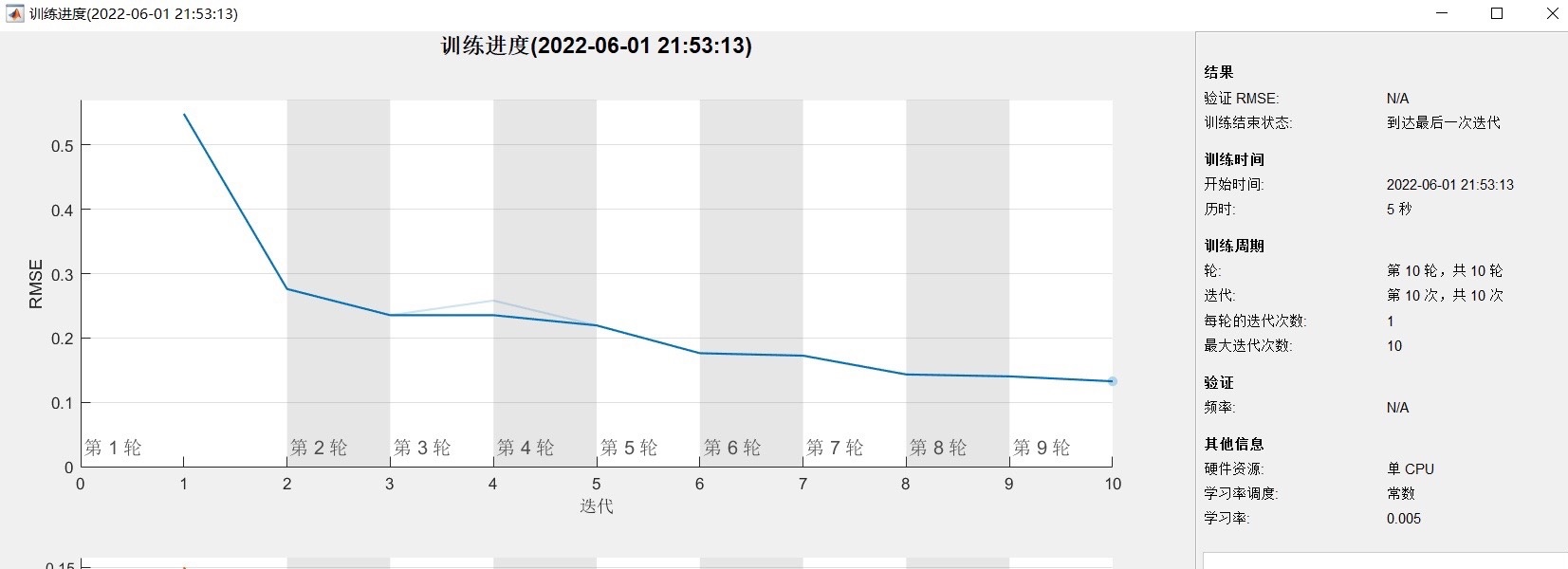
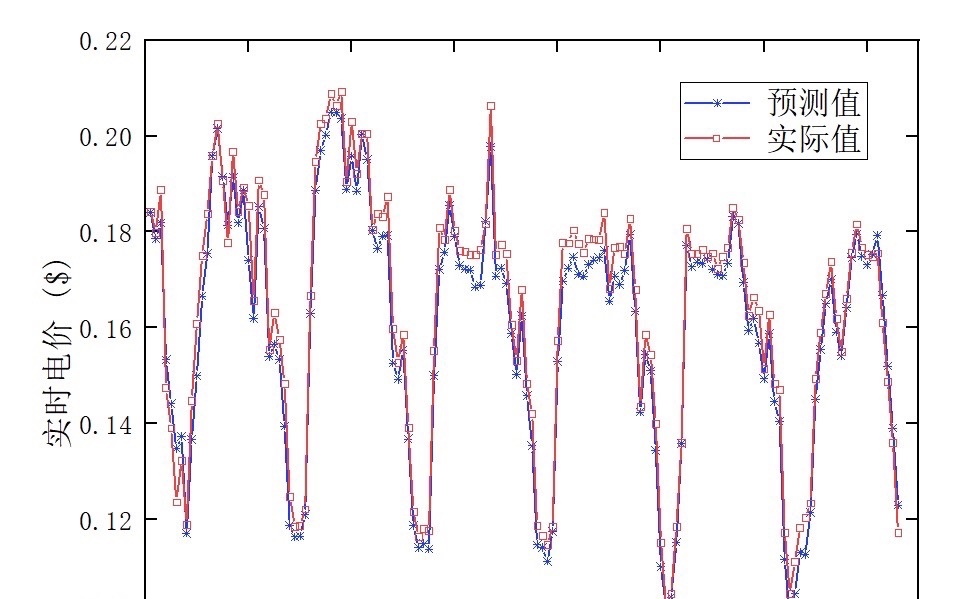
注意:程序功能如上述,可进行负荷预测、电价预测等时间序列的预测,结果如下图所示
ID:74100680727847901
Jztttttt
标题:基于EMD-SSA-BiLSTM的时间序列预测算法研究
摘要:本文在时间序列预测领域中,提出了一种基于经验模态分解(Empirical Mode Decomposition, EMD)、奇异谱分析(Singular Spectrum Analysis, SSA)和双向长短时记忆神经网络(Bidirectional Long Short-Term Memory, BiLSTM)的预测算法。通过将数据进行EMD分解,并结合经蚁群算法进行优化,再利用BiLSTM进行预测,最终将结果重组得到最终的预测结果。该算法在负荷预测、电价预测等时间序列预测任务上取得了较好的预测效果。
-
引言
时间序列预测是许多实际问题中的关键任务,如负荷预测、电价预测等。准确地预测未来的时间序列数据对于优化能源调度、提高能源利用效率具有重要意义。传统的时间序列预测方法往往依赖于统计模型,如ARIMA、GARCH等,但这些方法在处理非线性、非稳态、非高斯的时间序列数据时存在一定的局限性。本文提出的基于EMD-SSA-BiLSTM的预测算法能够更好地处理这类问题。 -
EMD-SSA-BiLSTM预测算法
2.1 经验模态分解(EMD)
EMD是一种将非平稳时间序列分解为一系列固有模态函数(Intrinsic Mode Function, IMF)的方法。EMD的基本思想是通过逐步提取时间序列中的局部变化模式,使得每个IMF都满足自身的振动特性和边际特性。将时间序列数据进行EMD分解后,可以得到一组IMF,每个IMF对应了不同的时间尺度和频率分量。
2.2 奇异谱分析(SSA)
SSA是一种通过构建状态矩阵并对其进行奇异值分解的方法,用于提取时间序列中的特征信息。在EMD的基础上,通过对每个IMF进行奇异谱分析,可以进一步提取出IMF的主成分,得到更加精确的时间序列特征。
2.3 双向长短时记忆神经网络(BiLSTM)
BiLSTM是循环神经网络(Recurrent Neural Network, RNN)的一种变体,具有较强的记忆能力和对长序列信息的建模能力。BiLSTM通过引入前向和后向两个隐藏层,能够捕捉到时间序列数据中前后关联的信息,并进行有效的预测。
2.4 EMD-SSA-BiLSTM预测算法流程
(1)将原始时间序列数据进行EMD分解,得到一组IMF;
(2)使用SSA对每个IMF进行特征提取,得到主成分;
(3)将提取的主成分作为BiLSTM的输入,利用双向LSTM进行预测;
(4)将多个预测结果重组,得到最终的预测结果。
-
实验与结果
本文针对负荷预测、电价预测等时间序列预测任务,从真实数据集中选择了一组样本进行实验。将EMD-SSA-BiLSTM算法与传统的ARIMA模型进行对比,通过均方根误差(Root Mean Square Error, RMSE)等指标评估算法的预测性能。实验结果表明,EMD-SSA-BiLSTM算法在预测准确性上具有明显优势,能够更准确地预测未来时间序列的走势。 -
讨论与展望
本文提出的EMD-SSA-BiLSTM预测算法在时间序列预测任务中取得了较好的预测效果,但仍存在一些改进空间。例如,可以进一步优化EMD分解的参数选择、改进SSA的特征提取方法,以及尝试其他深度学习模型在时间序列预测中的应用。此外,可以考虑引入其他领域的数据进行多源数据的融合预测。
结论:本文提出并实现了一种基于EMD-SSA-BiLSTM的时间序列预测算法,通过将数据进行EMD分解、应用SSA进行特征提取,再利用BiLSTM进行预测,取得了较好的预测效果。该算法在负荷预测、电价预测等时间序列预测任务上具有较高的预测准确性和可靠性,具有一定的实际应用价值。未来的研究可以进一步完善该算法并在更多领域中应用。
【相关代码 程序地址】: http://nodep.cn/680727847901.html















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









