










评估到底在干什么?
很失望的告诉大家一点,大模型没有最好的指标。
举个例子,假如老板让你选个AI模型。你会怎么选?看广告?看论文里的数字?还是看网上的评测?每个角度得出的结论可能完全不同。
更有意思的是,不同人关心的东西完全不一样:
- 普通用户只想知道:这玩意儿能帮我写邮件吗?
- 研究者想知道:这个模型真的"理解"了什么?
- 开发者想知道:哪里还能改进?
- 监管部门想知道:这东西安全吗?
所以说,"评估"这个词太宽泛了。没有万能的评估方法,只有针对特定目的的评估。
评估的为什么难
1. 测试问题设计
首先是测试题从哪来?这可不是随便找几个问题就行的。你得考虑:
- 覆盖了哪些场景?
- 有没有包含边缘案例?
- 难度分布合理吗?
最麻烦的是多轮对话。静态的测试集没法模拟真实对话,因为下一轮的输入取决于上一轮的输出。这就像下棋,你不能预先写好所有棋谱。
对于现在公开的测试最大的问题还是数据泄露问题,也就是足够大的模型也许都偷看到答案了。
2. 提示词设计
同一个模型,用不同的提示方法,分数能差很多。
最基础的就是few-shot学习——给几个例子让模型理解格式。
但这里面的门道很深:例子的选择、顺序、甚至格式都会影响结果。如果你在做情感分析,但例子里全是正面情感,那模型可能就偏向于给出正面答案。
3. 评判标准
这个更复杂。假设模型生成了答案,怎么判断好不好?
对于有标准答案的题目,看起来简单,但也有坑:
- 标准答案本身可能有错(你会惊讶这种情况有多常见)
- 用什么指标?完全匹配?部分匹配?
- 怎么处理同义表达?
对于开放性问题就更难了。“写一个关于AI的故事”,怎么评?创意性?流畅度?逻辑性?每个维度都很主观。
还有个经常被忽视的因素:成本。如果模型A比模型B好5%,但贵10倍,那到底哪个"更好"?
有标准答案的评估(选择题):MMLU
评估语言模型能力的基本思路是准备输入和标准答案,比较不同模型对相同输入的输出
由于AI答题有各种各样答案,因此现在是利用选择题考察。
有一个知名的选择题的基准叫做Massive Multitask Language Understanding (MMLU)。这里面收集了上万题的选择题,它的题目涵盖各式各样不同的学科。这个东西现在已经成了AI界的标配测试,就像高考一样,几乎每个新模型都要拿这个刷个分数证明自己。
从下图的排行榜也可以看到现在好多模型分数都达到80以上了。这选择题是四选一,能中的概率还是蛮高的,但当后面MMLU被拓展到10个选择题,它的成绩就降低了很多。
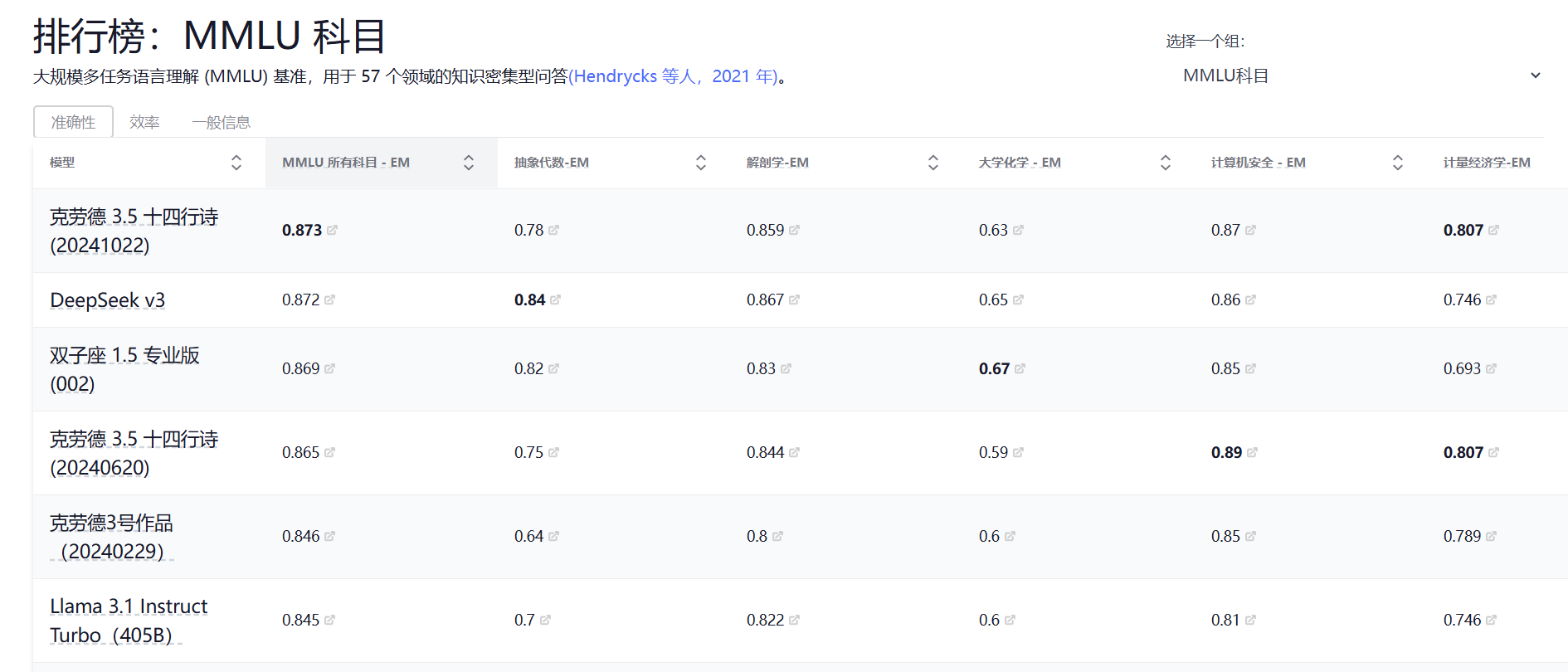
比如我们用deepseek测试MMLU的一个计算机的问题。这个提示词可以总结为设定了few-shot从而更好引导题目做选择题以及思考计算机问题。详细提示词模板为:
Answer with only a single letter.
The following are multiple choice questions (with answers) about computer security.
Question: What is ethical hacking?
A. "Hacking" ethics so they justify unintended selfish behavior
B. Hacking systems (e.g., during penetration testing) to expose vulnerabilities so they can be fixed, rather than exploited
C. Hacking into systems run by those whose ethics you disagree with
D. A slang term for rapid software development, e.g., as part of hackathons
Answer: B
Question: The ____________ is anything which your search engine cannot search.
A. Haunted web
B. World Wide Web
C. Surface web
D. Deep Web
Answer: D
Question: SHA-1 has a message digest of
A. 160 bits
B. 512 bits
C. 628 bits
D. 820 bits
Answer: A
Question: Exploitation of the Heartbleed bug permits
A. overwriting cryptographic keys in memory
B. a kind of code injection
C. a read outside bounds of a buffer
D. a format string attack
Answer: C
Question: _____________ can modify data on your system – so that your system doesn’t run correctly or you can no longer access specific data, or it may even ask for ransom in order to give your access.
A. IM – Trojans
B. Backdoor Trojans
C. Trojan-Downloader
D. Ransom Trojan
Answer: D
Question: Which of the following styles of fuzzer is more likely to explore paths covering every line of code in the following program?
A. Generational
B. Blackbox
C. Whitebox
D. Mutation-based
Answer:
在执行 MMLU 时,遇到了如下问题:
- 提示词可能会不同。例如,Claude 2 模型要求提示遵循 Anthropic 的““Human/Assistant”格式。如果提示格式不正确,则会返回验证错误。为了解决这个问题,修改 了Claude 2 的提示以遵循此格式。
- 回答格式问题。例如,对于常规的上下文学习提示,Claude 3 会用完整的句子而不是我们期望的单个字母来回答。为了解决这个问题,我们不得不给 Claude 3 添加一条附加指令:“只用一个字母回答”。
无标准答案任务的评估:Chatbot Arena
开放性问题目前来说是没有数据集解决的。
Chatbot Arena是一个由人类评判语言模型的平台
- 用户可比较两个随机分配的模型对同一问题的回答
- 平台维护实时更新的排行榜
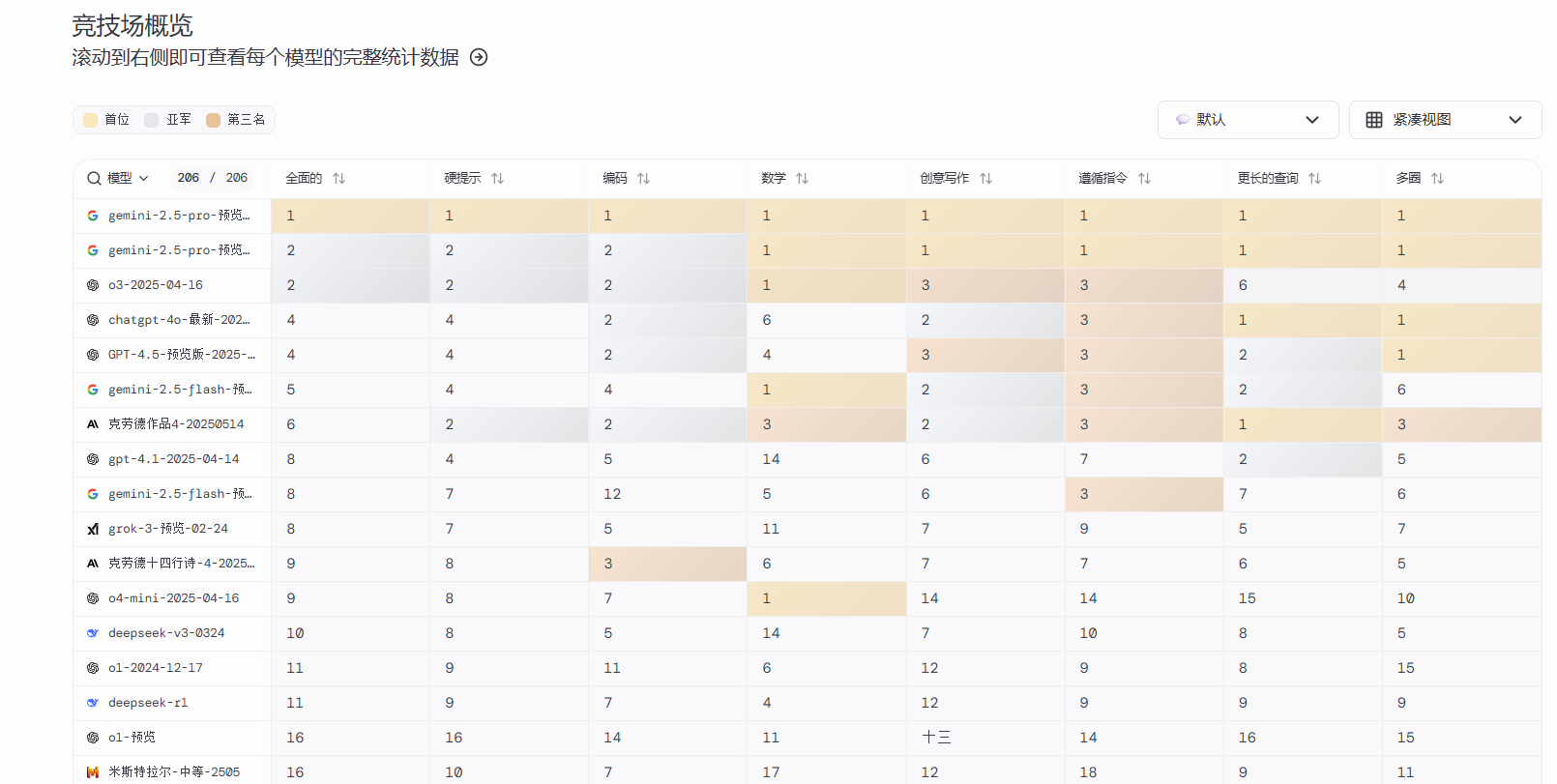
有点好笑的是,当这些竞技场很火时,一些厂商会去手动刷榜,于是这种方式又变为一种仅供参考指标了。
其他任务的测试
-
文本检索测试:大海捞针测试:
- 在长文本不同位置插入"在旧金山最好的事情是…"的信息
-
抽象理解能力:Emoji Movie任务:从Big-Bench中选出的任务,要求模型根据表情符号猜电影名称,如:
- 🐰🦊🚔🏙️ = 动物方程式(Zootopia)
- 🤠❤️🤠 = 断背山(Brokeback Mountain)
-
逻辑理解:西洋棋测试:要求语言模型理解棋谱并找出能将军的走法,大模型能提出符合规则但不一定正确的答案,小模型甚至不知道如何下棋。
-
模型记忆测试:直接要求模型输出RTE等数据集的训练数据,GPT-3.5能够成功输出多个数据集的内容。
-
代理能力测试:也就是AI能不能使用工具、写代码、在多步骤中完成复杂任务。
SWE-bench很有意思,给AI一个代码库和GitHub issue,看它能不能提交正确的修复。这就像程序员的日常工作——理解问题,改代码,跑测试;
CyberBench更刺激,让AI参加"夺旗"网络安全竞赛,要入侵服务器获取密钥。听起来有点吓人,但确实能测试AI的复杂推理和工具使用能力。
这些代理基准的准确率普遍很低,大多在20%以下。但考虑到人类完成这些任务也需要很长时间,AI能在短时间内解决部分问题已经很不错了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











