






0.前言
五一之前浮躁的心......以前上高中是这样,读了大学也这样,研究生了还这样,一临近放假心就飞的远远的~
1.数据准备
import numpy as np
mu, sigma = 0, 1 # 设置均值和标准差
normal_distribution_data = np.random.normal(mu, sigma, 30) # 随机生成一组符合正态分布的数据
unnormal_distribution_data = np.random.randint(0,30,(30)) # 随机生成一组不符合正态分布的数据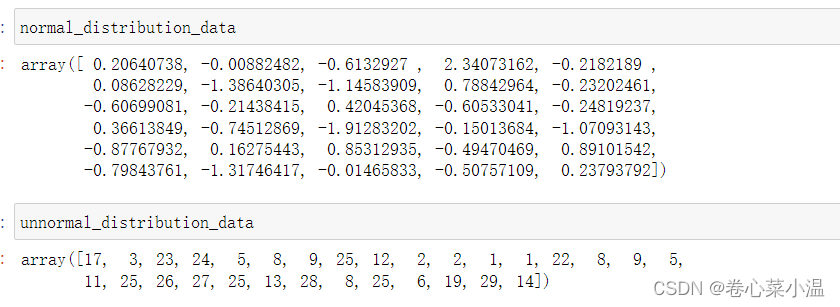
2.正态分布检验(Shapiro-Wilk检验)
正态分布(Normal Distribution),又名高斯分布(Gaussian Distribution)。若随机变量X服从一个数学期望为 、方差为
的正态分布,记为 N(
,
)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差
决定了分布的幅度。当
= 0,
= 1 时的正态分布是标准正态分布。
而对于我们所拿到的一个连续型数值数据,判断其是否符合正态分布,可以采用Shapiro-Wilk检验。
前提条件:数据是连续型的,并且样本量通常不宜太小。
1.假设样本数据是从一个正态分布中随机抽取的。
2.将样本值按照大小顺序排列,进行统计量W的计算,公式如下:
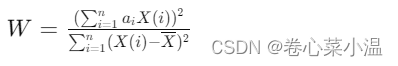

其中,是样本数据的均值,𝑎𝑖 是由样本大小、样本均值和方差等参数计算得到的常数,
是从一个标准的正态分布随机变量上采样的有序独立同分布的统计量的期望值。
V是这些有序统计量的协方差。
统计量W的取值范围在0到1之间,越接近1表示样本数据越可能来自于正态分布。
3.P值表示观察到的统计量W或更极端情况的概率。如果p值小于设定的显著性水平(通常是0.05),则拒绝原假设,即认为样本数据不服从正态分布。(这里其实看的不是很懂,大概就是做了很多次实验,然后该样本数据起码有95%及以上都符合正态分布吧......)
from scipy.stats import shapiro
alpha = 0.05
data_dict = {'normal_distribution_data': normal_distribution_data, 'unnormal_distribution_data': unnormal_distribution_data}
for i in data_dict.keys():
statistic, p_value = shapiro(data_dict[i])
if p_value > alpha:
print(f"{i}符合正态分布")
print(f"统计量为:{statistic}")
else:
print(f"{i}不符合正态分布")
print(f"统计量为:{statistic}")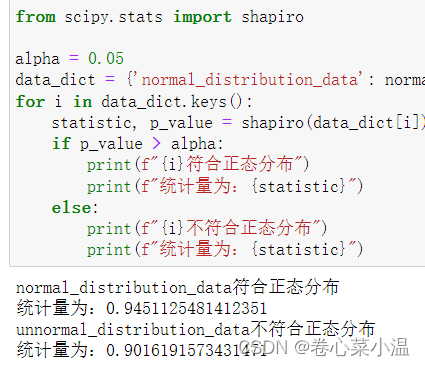
3.异常值检测(3σ原则检测)
先为符合正态分布的数据添加一个异常值。
normal_distribution_data = np.append(normal_distribution_data, 2000000000)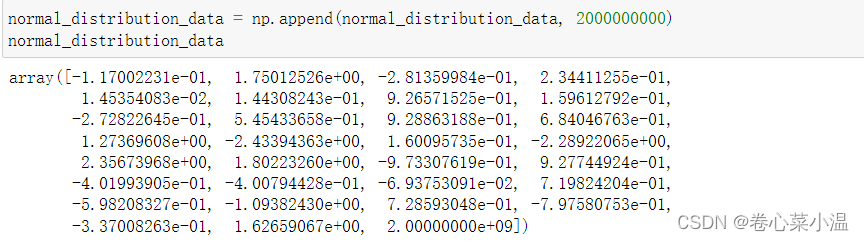
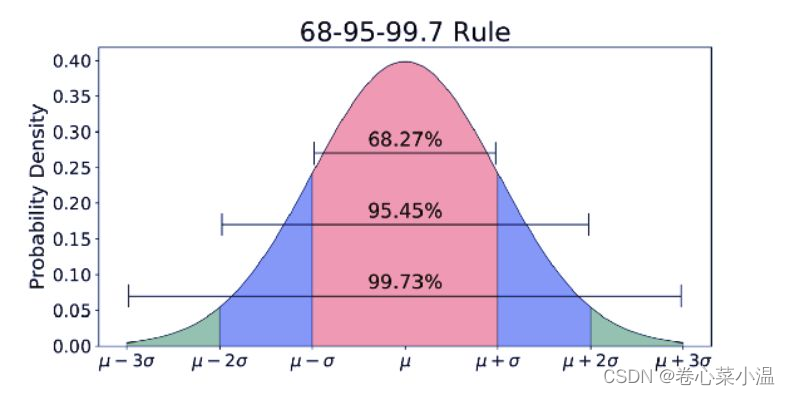
利用3σ原则检测异常值,从上图可知,横轴区间(μ-σ, μ+σ)内的面积为68.27%,横轴区间(μ-2σ, μ+2σ)内的面积为95.45%,横轴区间(μ-3σ,μ+3σ)内的面积99.73%。
由于“小概率事件(<5%)”和假设检验的基本思想 ,样本数据 X 落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,超过这个区间的就属于异常值。
import numpy as np
def three_sigma(sample_data):
"""
3-sigma法则异常值判定
"""
data_mean = sample_data.mean() # 计算均值
data_std = sample_data.std() # 计算标准差
data_max = data_mean + 3 * data_std # μ+3σ
data_min = data_mean - 3 * data_std # μ-3σ
rule = (data_min > sample_data) | (data_max < sample_data) # 选择 小于μ-3σ 或 大于 μ+3σ的数据,也就是异常值
index = np.arange(sample_data.shape[0])[rule] # 得到异常值索引
out_range = sample_data[index] # 获取异常数据
return out_range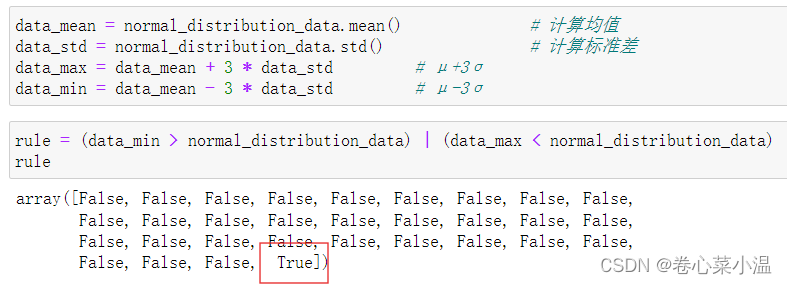
















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









