







语言模型(LM)
在经过孤立词识别之后,需要进入实际应用,也就是实际的语境中的识别,现实生活的语境往往十分复杂,比如方言,断句,省略词等,而且会面对无法预测的未知词语。这章的语言模型则是对这些问题一一分解。
目录
• 统计语言模型
• N-gram语言模型与评价方法
• 平滑算法(Smoothing)
- 拉普拉斯平滑(Laplace Smoothing/Add-one Smoothing)
- 古德图灵平滑(Good-turing Smoothing)
- 卡茨平滑(Katz Smoothing)
- 克奈瑟-内平滑(Kneser-Ney Smoothing)
• RNN语言模型
• 其它语言模型思想简介(Class-based N-gram & Cache Model)
语言统计模型
定义
一个统计语言模型包含一个有限集合V,和一个函数p(x1,x2,…,xn):
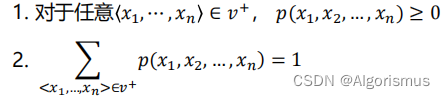
简言之:统计语言模型是所有词序列上的一个概率分布。
作用
1.它可以给我们任意词序列的概率,即帮助我们确定哪个词序列可能性大。
2.给定一个词序列,可以预测下一个最可能出现的词语! [用于ASR,MT等]
举个例子,如果是孤立词识别,那么会圈定识别的范围,如果是电话一样的指令识别,那么会有特定的词语规则,但是如果是日常对话,那么它的可能性就太多太广了。甚至还会面临断句,省略,同音词,缺失语境等等问题…
如何获得语言模型中的概率? 在语料库(Corpus)中计数。
训练集(training-set)与测试集(test-set)
保留集(held-out set): 从训练集中分离,用来计算一些其它参数,如插值模型中的插值系数
N-gram语言模型与评价方法
在实际语境中遇到新词的时候,我们通常会用前面已识别的词语作为基础去预测后面的词的可能性。这就是N-gram的核心思想:用前N-1个词作为历史,估计当前(第N个)词
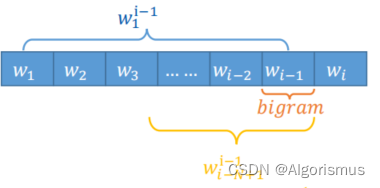
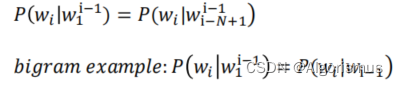
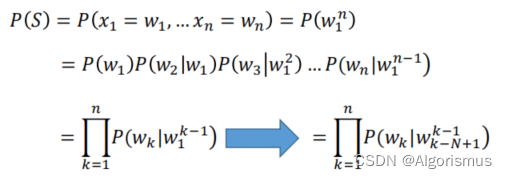
结合上述描述与之前的一些思想,考虑用最大似然的方式来预测中间词语。与此同时,开头与结尾则是用与来记录,而未知词(OOV)则会被标记为
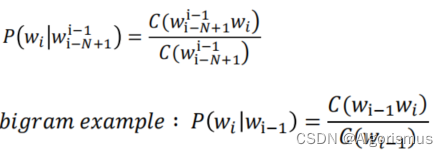
问题是如何评估这个模型的效率,这里采用了一个度量单位:困惑度(perplexity)
这个度量单位就是用单词归一化后的测试集概率
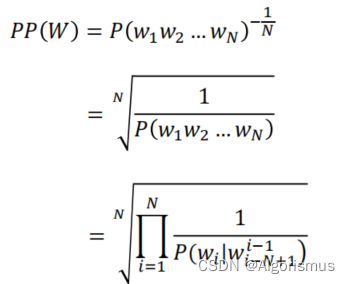
平滑算法
这个算法用于解决在已知语料库较为稀疏的时候,出现很多未知词序列,此时就需要用平滑算法把已知的概率分给未知。
1.拉普拉斯平滑Laplace Smoothing
Intuition:将每个计数加一,从而使得任何词序列都有计数。
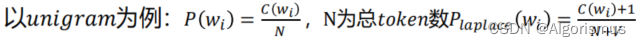
此时需要注意这个算法的两个概念:
1.调整计数c*:用于描述平滑算法对分子的影响。意思是在自身概率被分走之后,对原有概率的影响程度
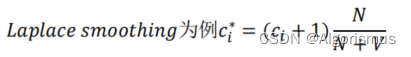
2.相对打折率dc:代表打折计数和原计数的比率。意思是对整体而言发生的变化
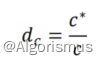
齐夫(Zipf)定律
自然语言语料库中,一个词出现的频率与它在频率表里面的排名成反比。
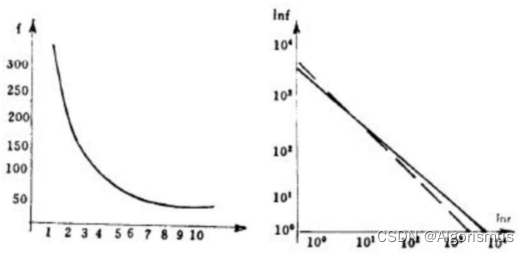
这意味着语言中大部分词都是低频词,只有很少的常用词。换句话说,就像是在英语交流中,只需要掌握常用的一两千词就可以比较顺畅的使用英语交流了。
2.古德图灵平滑(Good-turing Smoothing)
Intuition:用你看见过一次的事情(Seen Once)估计你未看见的事件(Unseen Events),并依次类推。
频率c出现的频数 frequency of frequency c − −Nc
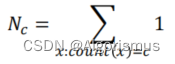
其核心算法为:
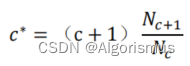

这个算法算是一个框架,把需要使用不同平滑的数据分类,因此需要与其他平滑算法结合使用。
认为c > k katz建议k = 5 ,认为计数可靠不进行打折。
而这里的算法常用的有两种:插值法和回退法
插值法
首先,在held-out set上使用MLE的方法,这些参数也可以通过经验获取
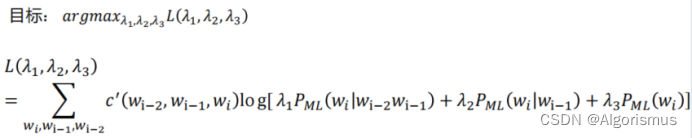
而在实际工程中如果无法获取全局的参数,则考虑使用历史计数来调整获取。

以下便是使用tri-gram为例介绍的插值法
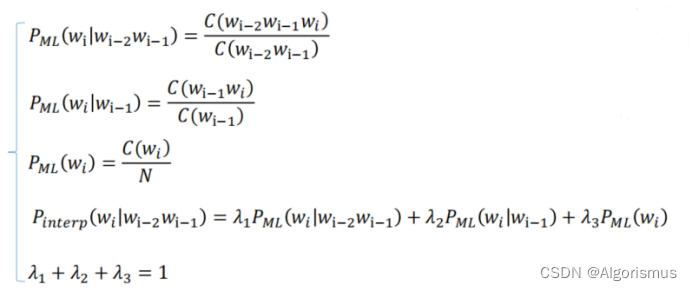
3.卡茨平滑(Katz Smoothing)
又叫递归回退法
Intuition:若N阶语言模型存在,直接使用打折后的概率(常使用Good-turing算法进行打折);
若高阶语言模型不存在(i.e. unseen events),将打折节省出的概率量,依照N-1阶的语言模型
概率进行分配,依此类推。
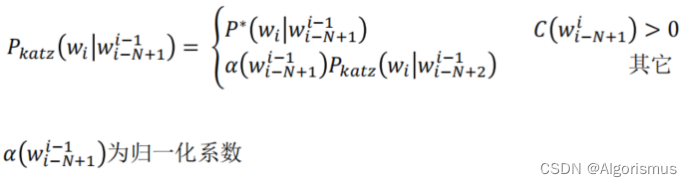

4.克奈瑟-内平滑(Kneser-Ney Smoothing)
Intuition:对于一个词,如果它在语料库中出现更多种不同上下文(context) 时,它可能应该
有更高的概率。
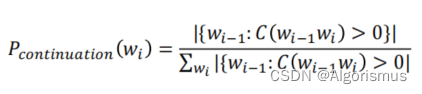
以bi-gram为例
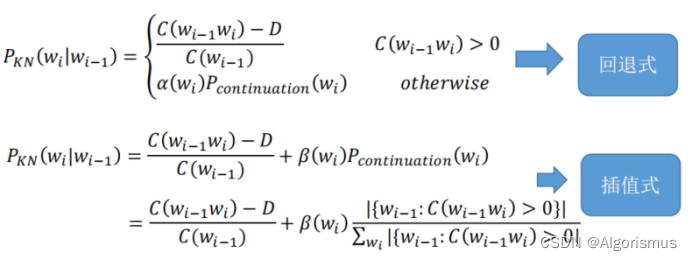
RNN语言模型
统计语言模型的目标:
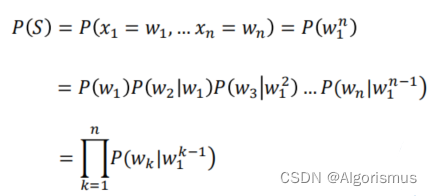
RNN就是根据历史推测当前
低频词袋法:
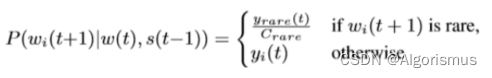

基于类的N元语言模型(Class-based/Clustering N-gram):
Intuition:在语言学中,将具有同样语义的字词归为一类是一种常见的解决数据稀疏的方法。
受此启发,在语言模型中,根据词性分析,语义分析,或者特定任务时人为设计,我们可以将
词和类别建立联系,通过类别信息,帮助我们提升语言模型建模性能。(e.g.航空订票系统)

缓存模型(Cache Model):
Intuition: 如果一个词在句子中用到,那么它很可能被再次用到。
例如:两个人在讨论旅游,它们可能反复用到同一个地名。

作业地址之后会补充在评论区















 4335
4335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









