







 本文是《统计学习方法》笔记,深入解析决策树模型,涵盖预备知识(熵、条件熵和信息增益)、ID3、C4.5、CART算法的生成与剪枝,以及过拟合和信息增益比的概念。通过实例解释了决策树在分类和回归问题中的应用,并讨论了剪枝策略以避免过拟合。
本文是《统计学习方法》笔记,深入解析决策树模型,涵盖预备知识(熵、条件熵和信息增益)、ID3、C4.5、CART算法的生成与剪枝,以及过拟合和信息增益比的概念。通过实例解释了决策树在分类和回归问题中的应用,并讨论了剪枝策略以避免过拟合。
《统计学习方法》笔记05:决策树模型
决策树模型:由训练数据集估计条件概率模型。
学习算法:ID3,L4.5,CART三种。
5.1 预备知识
1. 熵
熵可用来衡量一个随机变量的概率分布的不确定性情况。当随机变量在各取值上概率相同时,熵最大。熵反映了分布的不确定性程度。当分布中各取值概率相同时,不确定性最大,则熵最大。
举例:巴西,德国,中国三国足球联赛,巴西和德国取胜概率远大于中国,不确定性小,可以看做“熵”小;而巴西,德国,阿根廷联赛,三者取胜概率相近,不确定性大,可以看做“熵” 大。计算公式如:
随机变量X共有n种取值,每种取值上的概率与对数乘积的总和。
当各取值上概率相同时,熵最大:
推导如下:
当随机变量只取2个值时,当取值概率为0/1时,熵为0,此时完全没有不确定性。
2.条件熵
如上,熵可反映随机变量X的概率分布的不确定性。有时候,我们还获得了一些和X有关其他信息,将有助于确定X在某些取值上的概率变化,这时X概率分布的不确定性可能会降低。已知其他信息的情况下,X的熵就成了条件熵。
举例:巴西,德国,阿根廷联赛,三者取胜概率相近,不确定性大,“熵” 大;但我们得知巴西全体队员拉肚子,那其获胜可能性变小。球赛整体熵会变小。在这种情况下,就是条件熵。
已知随机变量(X,Y)的联合概率分布为:
条件熵H(Y|X)表示已知X情况下,Y的分布的不确定性。计算如下:
X的取值有n种。
2. 信息增益
信息增益:得知了X信息,使得类Y的信息不确定性减小的程度。也叫作互信息(mutual information),决策树中的信息增益等价于训练集中的类与特征的互信息。
在监督学习中,特征A对训练集D的信息增益:
很明显,信息增益越大,说明不确定性减小的程度越大,该特征越强。该特征的条件熵很小。
算法:求特征A的信息增益
特征A,有n个取值,每个取值下的样本个数为 Dn ,其和为样本总数。
输出: g(D,A)
(1)计算经验熵H(D)。当从数据估计中得到概率时,称为经验熵。
H(D)=−∑k=1K|Lk||D|⋅log2|Lk||D|
(2)计算经验条件熵H(D|A):
H(D|A)=−∑i=1n|Di||D|⋅H(Di)
H(Di)=−∑k=1K|Dik|Di⋅log2|Dik|Di
(3)计算特征A的信息增益gain:
g(D,A)=H(D)−H(D|A)
信息增益越大,说明不确定性减小的程度越大,该特征越强。该特征的条件熵很小。举例:银行给某个用户是否发放贷款,特征有用户性别,用户收入等。一般的,发放结果主要看用户的偿还能力,和性别关系不大。
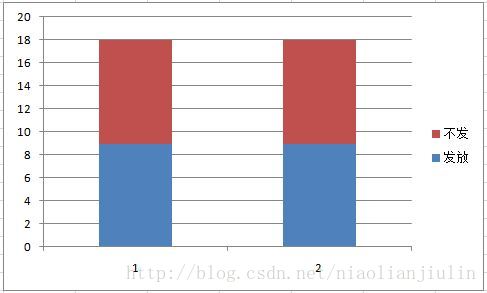
在性别的不同取值(男1、女2)上,发与不发的情况都是各占一半,此时性别的条件熵很大,信息增益就很小;
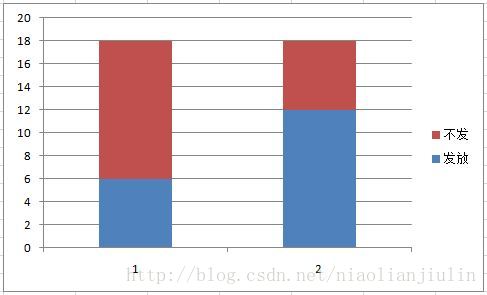
而在用户收入特征上,在收入不同取值(低1,高2)上,收入高时发放比例很高,收入低时发放比例很低,此时收入的条件熵就很小,信息增益会很大。
则由信息增益知道,收入就是个强特征。
5.2 决策树的生成
1. ID3算法
决策树可看做是if-then-else的集合,以树的形式来看,每个节点是一个判断的特征,根据取值去左子树或者右子树,达到分类的目的。
ID3算法在各个节点上,根据信息增益进行特征选择,递归地构建出决策树。相当于用极大似然法进行概率模型的选择。
对数据集D,在特征集A中选择一个由最大信息增益的特征,可将D分为若干自己 Di ,以 Di 中有实例数最大的类为标记,构建子节点。对第i个节点,以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3132
3132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









